Editer Réseau
Sommaire
1. Généralités
2. Sécurité
3. Types de réseaux
4. Protocoles
5. Modèles
- Couches OSI
- Couches TCP/IP
- TCP et UDP
- Protocole UDP
- Modèle de réseau hiérarchique
6. IPV4
- Adresse réseau
- Adresses réservées
- Adresses publiques
- ICMP
7. IPv6
8. Couche 2 du modèle OSI
- Trame Ethernet
9. Couche 1 du modèle OSI
10. Materiel réseau
- Hub
- Pont
- Switch
- STP (Spanning Tree Protocol)
- Routeur
11. D'un réseau à un autre
- RIP
- OSPF
- Routage Cisco
12. DHCP
- Serveur DHCP (Cisco)
- Relais DHCP (Cisco)
13. Access list
- Vlan
- Sauvegarde des modifications (Cisco)
- Exporter/importer la configuration (Cisco)
- Reset switch Cisco
- Reset routeur cisco
- Commandes diverses(Cisco)
- Windows
14. Configurer connexion ADSL cisco
- NAT avec routeur Cisco
- Faire fonctionner windows 7 avec OpenSWAN
15. VPN
- Open VPN
- Comment ICMP traverse un NAT ?
- DSL
16. Liens intéressants
Les quatre éléments d'un réseau de données :
Réseau convergent :
Autrefois, on avait plusieurs réseaux différents pour la téléphonie, la télévision et internet. Ce n'était pas les mêmes câbles, pas les mêmes protocoles. Un réseau convergent permet d'utiliser un seul réseau au lieu de trois. Baisse les coûts de déploiement et de maintenance.
Réseau à commutation de circuits :
Pour établir une communication entre deux machines, il existe de nombreux chemins possibles, mais un seul est sélectionné durant toute la durée de l'appel. Si le chemin est coupé, la communication est interrompue.
Réseaux à commutation de paquets :
Les messages sont découpés en petits paquets, qui peuvent chacun parcourir un chemin différent pour arriver à destination. Meilleure tolérance aux pannes.
QoS :
La QoS (Quality of Service, Qualité de service), permet de rendre certain types de communication prioritaires par rapport à d'autre. Par exemple, sur un réseau où on trouve à la fois de la téléphonie, de la tv et du web, on pourrait vouloir rendre la téléphonie ou la TV prioritaire par rapport au web. Le routeur transmettra d'avantage de paquets TV que de paquets web (les pages web s'afficheront avec un peu de retard mais l'image de la TV sera meilleure).
Plusieurs niveaux ("tier" en anglais) pour les FAI (fournisseurs d'accès à internet) :
- Niveau 1 (tier 1) : assurent les connexions nationales et internationales. Se connectent avec les autres FAI de niveau 1 gratuitement, car ils ont autant besoin d'accéder à leur réseau qu'eux aux leurs. Parfois, des FAI de niveau 1 ne se considèrent plus comme égaux et l'un demande une compensation financière à un autre. Exemple, Cogent et Telia ont rompu leurs connexions, obligeant les paquets à emprunter une autre route (source 1, source 2). Retenir que les niveau 1 peuvent se connecter à tous les réseaux d'internet sans devoir payer. Coût très élevé si une entreprise veut se brancher directement sur eux, mais pas de goulot d'étrangelement car accès direct donc connexion plus rapide et plus fiable.
- Niveau 2 (tier 2) : payent certains FAI de niveau 1 pour avoir accès au réseau (orange).
- Niveau 3 (tier 3) : payent des FAI de niveau 2 (wifirst).
Ont un impact sur la qualité du réseau : l'envoi d'un accusé de réception, la qualité de la ligne, le nombre de fois où le message doit changer de forme, le nombre d'autres communications sur le réseau, temps alloué.
Multiplexage :
On parle de multiplexage lorsqu'on transmet plusieurs signaux indépendants sur un même support de transmission. Exemple, une ligne téléphonique en Y, les deux extrémités hautes vont chacun chez un client puis se rejoignent sur un seul fil. Plusieurs communications téléphoniques sur un seul fil. Egalement appelé "AMRF Accès Multiple par Répartition de Fréquences" ou "FDM : Frequency Division Multiplexing". Impossible de mettre l'ADSL sur un câble téléphone qui utilise du multiplexage car les fréquences utilisées par l'ADSL sont utilisées par d'autres abonnées. Dans une ligne ADSL, 4 Khz pourront être utilisées par la voix et 1 Mhz par les données. Plus d'infos(( An analog signal's infinite number of variations makes it impossible to reproduce exactly. An analog signal will go only so far in copper wire; to go further the signal must be regenerated electronically with a device called a repeater. The repeater converts the weak input signal to a stronger output signal, unavoidably distorting it in the process. Each regeneration degrades the signal a bit more (in the same way that photocopies of photocopies get worse at each iteration). In a large telephone network, the "copy of a copy" problem becomes very expensive to solve, requiring sophisticated equipment and costly cabling.
Digital signals, on the other hand, are easy to regenerate precisely. Because there are only two possible states for the signal, even a heavily degraded signal can be regenerated into an exact copy of the original. What's more, the cost (and complexity) of equipment to regenerate digital signals is trivial compared with that for analog. Not surprisingly, telephone companies recognized this cost advantage a long time ago and have since converted all long distance transmission to digital signaling. When a subscriber makes a long-distance call, the central office (CO) converts the analog signal to digital using a technique called sampling (see "Analog-to-Digital Conversion Diagram"), in which the state of the analog signal is captured about 8,000 times per second. Each state is converted to an 8-bit binary number, and the resulting string of binary numbers becomes a digital data stream at 64 Kbps. This digital stream is routed along the long-distance network, being regenerated as needed. Each regeneration produces an exact copy of the original digital data stream, so no information is lost. When the destination CO receives the digital data stream, it reverses the sampling process and transmits the resulting analog signal to the receiving subscriber. (On a side note, many local telephone companies are converting to digital switching, even for local calls).))
Ne pas confondre avec le multiplexage sur la couche transport de tcp/ip (divisions en ports 80, 21, etc).
Segmentation :
Les communications sont découpées en petits paquets. Les paquets sont tous envoyés sur la même ligne. Pas de limite de communication simultanées, contrairement au multiplexage qui nécessite une fréquence libre pour chaque communication.
RNIS :
Reseau numérique à intégration de servis ("numeris" chez France Telecom). Plusieurs canaux logiques dans une même ligne. Numérique d'un bout à l'autre, pas de transformation analogique : en transformant la voix en signal numérique, le signal est facilement régénéré. On dit que c'est une technologie à large bande car elle utilise plusieurs canaux. Numeris est un réseau à commutation de circuits (contrairement à ADSL). On paye durant tout le temps que la communication est établie. Bon site sur ISDN
La sécurité s'occupe de 3 points :
* Assurer la confidentialité des données. Système d'authentification des utilisateurs pour s'assurer qu'il va à la bonne personne, chiffrement des données pour que n'importe qui ne puisse pas les lire.
* Garantir l'intégrité des données, c'est à dire que les données ne doivent pas avoir été modifiée entre l'envoi et la réception, ou ce qui a été enregistré ne doit pas avoir été modifié une fois sur le support.
* Assurer la disponibilité. Lutter contre les attaques de type DoS (deny of service), les sabotages, etc. Mettre en place des sauvegardes. Délai suffisant de disponibilité (pas le même délai acceptable pour téléphonie et web). Pour gérer ça, mise en place d'enregistrement du trafic pour prévoir un risque.
On peut ajouter "authentification" (être sûr que la personne à qui on parle est celle que l'on veut) et "non-répudiation".
Répudiation : pouvoir nié avoir pris part à une transaction. La sécurité informatique peut avoir besoin de mettre en place un système de "non-répudiation" par exemple lorsqu'on met en place un système de signature électronique.
Utiliser des sites généralistes comme [http://web.nvd.nist.gov/view/vuln/search|nist.gov] ou les sites des constructeurs/développeurs pour repérer les dernières failles.
Types de menaces :
-Naturelles 26%. 13% pour incendie, explosion, dégâts des eaux, pollution, catastrophe naturelle 2% pour arrêt de service électricité ou télécom. 11% de pannes systèmes : panne informatique, panne réseaux internes, saturation des réseaux.
-Humaines 74% :17% pour erreurs humaines (8% conception, 9% exploitation). 57% pour la malveillance. 2% pour vol, sabotage. 18% pour fraude. 12% pour intrusion, virus. 14% copie de logiciel, 10% vol de ressource, 1% démission, grève, absence.
Origine des menaces :
Menaces la plupart du temps interne.
-Divulgation de la part d'employés autorisés : 54 %
-Employés non-autorisés : 22 %
-Anciens employés : 11%
-Pirates : 10%
-Concurrence 3%
Attaques physiques :
-Interception de signaux électromagnétiques (cf la norme TEMPEST, Telecommunications Electronic Material Protected from Emanating Spurious Transmissions).
-Brouillage.
-Ecoute.
-Piégeage.
-Micros et caméras espions.
Attaques physiques :
-Social Engineering (faire révéler des infos à quelqu'un en se faisant passer pour quelqu'un d'autre), le plus utilisé. "Bonjour, c'est XXX de Tour, on s'est vu à la réunion tu te rappelles ? Je suis embêté ya plus personne dans le bâtiment et j'ai oublié le mot de passe de...".
-Fouille des dossiers.
-Attaque sur les mots de passes.
-Backdoor (créé par le concepteur du logiciel ou la maintenance).
-Déni de service.
-Virus, ver, cheval de Troie.
Attaques sur les mots de passe :
-Dérober un mot de passe (Social Engineering, vol).
-Deviner un mot de passe (question secrète, date de naissance, noms des proches, mots courants, sportif, voiture, vedette, lieu, injure...).
-Renifler un mot de passe (le prendre alors qu'il transit).
-Cracker un mot de passe (brute force, dictionnaire...).
Le piratage téléphonique - Phreaking, pour utiliser une autre ligne que la sienne, ou pour pirater un modem derrière les pare-feus.
Virus : se cache dans un .exe, .doc, .xls... Peut se recopier seul.
Si le lanceur a été écrit pour se mettre à un endroit particulier d'un code, une mise à jour d'un logiciel, même si elle ne s'attaque pas directement à une faille, permet de perturber le fonctionnement du virus. Le virus ne peut plus s'intégrer au code comme prévu.
Ver : ne se joint pas à un programme, se reproduit seul, utilise en général des failles.
Bombe logique : fonction ajouté à un programme qui se déclenche à un moment donné.
Cheval de troie : un logiciel en apparence bienveillant qui cache un virus.
IP spamming : innonder de message un serveur.
IP sniffing : écouter le trafic réseau.
Ip Spoofing : voler une adresse ip.
Source Routing : forcer à utiliser une route plutôt qu'une autre.
Attaque par fragmentation (teardrop) : envoyer des paquets volontairement impossibles à remettre dans le bon ordre pour bloquer l'appareil (dépassé).
Man in the Middle : A communique avec C en croyant qu'il s'agit de B, B communique avec C en croyant qu'il s'agit de A. C voit toutes les informations passer, A et B pensent communiquer directement.
Pour définir une politique de sécurité, il y a plusieurs entités à prendre en compte :
-L'organisation, définir les responsabilités, les procédures.
-Le personnel, définir les droits, sensibiliser les chefs/techniciens/utilisateurs, former.
-La zone physique, définir un contrôle d'accès, penser au ménage, à l'environnement (inondation, incendie, etc).
-Le matériel, définir une méthode de gestion du parc, protéger contre le vol, penser à la maintenance, l'homologation...
-Le logiciel, contrôle d'accès, imputabilité ("non-répudiation"), audit (qui a accédé à quoi), développement, maintenance, archivage.
-Le support, gestion des enregistrements sur support physique, de la destruction, reproduction, conservation, marquage...
En priorité, la sécurité physique (quelqu'un qui a accès physiquement à une machine peut très facilement la craquer), les sauvegardes. Ensuite, les mots de passes, les comptes, les bases de définition des virus. Pas de bidouilles sur système en production.
Surtout : sécuriser les personnes et les sauvegardes.
Authentification par ce qu'on sait (mot de passe), ce qu'on détient (jeton), ce qu'on est (biométrique)
Il ne faut pas que la sécurité soit trop forte ou les utilisateurs passeront au travers. Si on met trop de chose ce n'est plus maintenable. Il y a un équilibre à trouver entre facilité d'utilisation et sécurité. Autre problème, les hackers vont vérifier si une machine est particulièrement protégée, signe qu'elle protège quelque chose.
SOCKS (Socket Secure) : Protocole qui route les paquets entre client et serveur à travers un proxy. Au niveau 5 de la couche OSI (session). SOCKS ne sert pas uniquement pour le HTTP mais pour n'importe quel service, écoutent en général sur le port 1080.
Zone démilitarisé : où on met les serveurs accessibles par le public.
Callback : pour éviter que quelqu'un se fasse passer pour nous (faux N° de tel envoyé), on appelle un téléphone ip, lui demande de nous rappeler.
ARP spooffing : Lorsqu'on fait une requête ARP, on demande l'adresse du routeur. Si quelqu'un répond avant, il peut se faire passer pour le routeur.
Attaque par fragmentation : on regarde les paquets fragmentés passer et on envoie des paquets qui disent faire partie de cette fragmentation.
Source routing : on change son ip source quand on envoie une demande au routeur.
Chiffrement : par exemple, on mélange les bits selon un algorithme et une clef, on peut déchiffrer avec une clef.
Clef symétrique : même clef pour chiffrer/déchiffrer.
Clef asymétrique : A et B génèrent chacun une paire de clef générée ensemble, une permet de crypter, l'autre de décrypter. Basé sur l'impossibilité de factoriser les nombres premiers de grandes dimensions. On envoie la clef qui permet de crypter à l'autre, il crypte, nous envoie le message, on décrypte. En envoyant sa clef publique, on accepte que des hackers puissent nous envoyer des messages (<-à vérifier, me semble que c'est la privée qui permet d'envoyer des messages).
SSL permet de faire appel à des organismes officiels auprès desquels les clefs publiques ont été diffusé. Si on va chez paypal, le navigateur va consulter un tier pour demander si la clef publique reçue correspond bien à une clef de type paypal.
Quand on fait un ping dans un VPN, le TTL du ping ne pas avoir décrémenté, car le paquet ping est chiffré, donc le routeur ne l'a pas décrémenté.
Attention : si on fait des choses trop complexes on fait des choses qu'on ne gère plus et on fait donc des failles de sécurité.
Matériel : difficile de désassembler le code (processeur spécial...), moins vulnérable aux virus qu'un pare-feu installé sur un linux...
Un parefeu doit être invisible pour un attaquant extérieur. Si on fait son parefeu avec un routeur, ou un linux avec iptable, il faut le cacher.
Même si l'un des avantages d'un pare-feu est de centraliser les règles de filtrage, on peut mettre plusieurs pare-feux, mieux vaut avoir de la redondance.
La priorité de la sécurité, c'est l'accès et les personnes : si un employé peut faire un point d'accès avec son téléphone le pare-feu ne sert à rien.
Dans un système "stateful", on peut n'ouvrir les ports que si il y a établissement d'une connexion TCP, pour éviter de les laisser tout le temps ouvert.
Avec ses analyses, le pare-feu peut réduire la bande passante.
Le pare-feu peut servir à faire de la répartition de débit. Il peut faire de la QOS pour réserver de la bande passante selon les personnes ou les entreprises.
Pare-feu bridge : fonctionne au niveau 2, pas avec l'ip. N'a pas d'adresse ip ni mac, donc invisible.
On peut tester sa sécurité avec NMAP, NPING2 ou NESSUS ou via des sites internet.
Schéma 1 :
Les ordinateurs du réseau lan de l'entreprise vont faire leur demande sur internet en passant par le proxy. Le proxy va faire les demandes à notre place. Les réponses iront au proxy. Le routeur 2 peut faire du NAT pour supprimer les adresses ip.
Si un ordinateur de l'entreprise est piraté (trojan), le proxy le rend difficile à contrôler.
Le pare-feu est un filtre, le proxy est un outil qui fait des demandes à la place de l'utilisateur.
Identifié selon : la zone qu'il dessert, la façon dont sont stockées les données, la manière dont sont gérées les ressources, son organisation, le type de périph, le moyen utilisé pour les connecter entre deux.
Réseau local (LAN : Local Area Network) : généralement une zone restreinte et un seul groupe d'administration. Peut contenir d'autres LAN.
WLAN : réseau local sans fil (wireless LAN), utilise les ondes radio (d'une dizaine de mètres de portée à plusieurs dizaine de kilomètres en Wimax). Les périphériques se connectent sans fil au points d'accès, qui sont eux mêmes connectés à internet via des câbles.
PAN : Réseau personnel (personal area network), souris, smartphone, tablettes connectées, généralement en Bluetooth (7 periph maximum, fréquence radio de 2.4 à 2.485ghz, technologie adaptative AFH pour réduire les interférences). Généralement symétrique, les appareil communiquent entre eux contrairement au wifi où c'est généralement client/serveur.
MAN : Réseau métropolitain (metropolitain area network), optimisé pour une zone géographique plus large que le LAN. Lignes appartiennent généralement à un consortium d'utilisateur ou à un FAI.
WAN : Réseau étendu (wide area network), relie ensemble des réseaux plus petits (interréseaux). Des entreprises privées peuvent aussi metrte en place leur WAN pour relier deux sites distants avec des lignes louées. Internet est un réseau WAN.
SAN : Réseau de stockage (Storage Area Network), utilisant par exemple ISCSI. Une unité de stockage SAN est désignée par un numéro LUN (Logical Unit Number). Dans un réseau SAN, on a accès au disque en mode block, comme s'il était directement connecté au PC, et pas en mode fichier (contrairement à un NAS).
Réseau P2P : Pas de serveur dédié ni de hierarchie entre les PC. Pas d'administration centralisée, pas de sécurité centralisée, plus il y a de PC, plus la complexité du réseau augmente. Pas forcément de sauvegarde centralisée.
Intranet : Réseau interne à une entreprise.
Extranet : accès limité au réseau intranet d'une entreprise via l'extérieur.
Un protocole est une règle de communication, une sorte de langage commun que 2 programmes utilisent pour communiquer. Lors d'une communication, il existe plusieurs programmes qui vont discuter entre eux. Par exemple, imaginons un navigateur qui veut consulter une page internet.
-Premier programme, le navigateur (Internet Explorer). Il sait demander une page internet à un serveur web 1.2.3.4 selon le protocole HTTP ("donne moi s'il te plait la page index.htm, si elle a été modifiée après le 10 juin 2014, je m'appelle internet explorer."
Mais pour que ce texte, ces données, arrivent jusqu'au service web du serveur, il faut qu'il voyage sur le réseau.
-Deuxième programme (ou plutôt, une "blibliothèque"), winsock, qui va découper les données en segments. Il va utiliser le protocole IP (pour envoyer le message vers 1.2.3.4.) ainsi que le protocole TCP pour demander un accusé de réception et préciser le port où écoute la machine (un "port" permet de filtrer ce que l'ordinateur reçoit -tel port est destiné à tel programme, cela lui permet d'éviter se se mélanger quand il reçoit, par exemple, à la fois une page web et un fichier).
-Troisième programme, le pilote de notre carte réseau, qui va utiliser le protocole Ethernet et transformer le tout en impulsions électriques. Le protocole ethernet permet à des machines de communiquer entre elles d'après leur adresse MAC. Si on disait que l'adresse IP serait le numéro de téléphone, l'adresse MAC serait le numéro de série du téléphone. Notre ordinateur ne connait pas toutes les adresses MAC de tous les PCs sur internet : il ne connait que les adresses macs des machines connectées à lui (commande "arp -a" pour les voir).
En résumé : 1)Ethernet pour communiquer avec la machine directement connectée à nous, 2)IP pour communiquer avec une machine plus loin, 3)TCP pour demander un accusé de réception et préciser un port, 4)HTTP pour demander telle page web.
On a ici 4 protocoles différents, "encapsulés" les uns dans les autres : dans un seul paquet, on aura "[ethernet[ip[tcp[données]]]]". On parle aussi de "couches".
Avoir des couches distinctes permet :
* une plus grande flexibilité. On peut très bien avoir du HTTP sur la première couche mais pas de l'Ethernet sur la dernière, ou bien autre chose que du http ou du TCP/IP mais toujours de l'ethernet.
* de concevoir des nouveaux protocoles plus facilement, qui s'encapsulent avec d'autres, ce qui encourage la concurrence.
* si un protocole devient obsolète, les protocoles des autres couches peuvent continuer à être utilisés.
Mis à part la couche 1 et 2, les protocoles sont en général définis par des organisations telles que l'IETF (Internet Engineering Task Force), par les constructeurs ou les créateurs de programmes. Les couches 1 et 2, très liées au matériel, voient leurs protocoles en grande partie définis par des organisation internationales de normalisation comme l'IEEE (Institue of Electrical and Electronics Engineering).
L'organisation internationale de normalisation (ISO) propose un standard pour les couches de protocoles, en proposant 7 parties. Néanmoins, beaucoup de protocoles ne collent pas vraiment à ces 7 parties (voir la Tentative de séparer de sprotocoles selon ces 7 couches).
Modèle OSI chez cisco, Modèle OSI chez webopedia.
Première sous-couche de la couche liaison ⇒ LLC (Logical link control) : Des mécanismes de multiplexage, par exemple en utilisant le champ VLAN (si on utilise la norme 802.1Q) ou bien le champ "type" d'une trame ethernet (qui indique quel protocole est en train d'être transporté, par exemple IP ou ARP). Inclus aussi les acquittement et le contrôle d'erreur (4 octets à la fin d'une trame ethernet).
Seconde sous-couche de la couche liaison ⇒ MAC (media access control) : Accès au support, adresses physique des machines.
Un navigateur web comme Internet Explorer intègre les couches 5, 6 et 7.
Protocol Data Unit : On appelle PDU le fragment d'une donnée. Par exemple, le PDU de la couche 1 est le bit (la donnée a été découpée en bits). Le PDU de la couche 2 est appelé une trame. Le PDU de la couche 3 est appelé un paquet. Le PDU de la couche 4 est appelé un segment pour TCP et un datagramme pour UDP. Plus d'info sur wikipedia
Moyen mnémotechnique : "Après Plusieurs Semaines Tout Respirait La Paix".
Il existe également le modèle TCP/IP ("modèle internet"), finalisé avant le modèle OSI, qui lui ne propose que 4 parties. Ne pas confondre le protocole TCP et le protocole IP : un protocole peut utiliser un système en couche similaire à celui du modèle TCP/IP mais ne pas utiliser le protocole TCP (par exemple, UDP à la place de TCP).
Comparaison des couches dans les modèles OSI et TCP/IP :
Protocoles utilisant le modèle TCP/IP (source de l'image inconnue) :
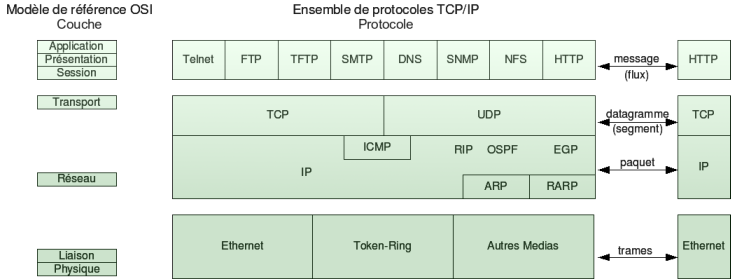
ICMP est en dessous de TCP et UDP : il n'y a pas de notion de port avec ICMP (on ne peut pas "ping" un port).
La couche 3 utilise 3 processus de base : l’adressage (assignation d'une adresse à un hôte), l'encapsulation ("création" du paquet comprenant les données des couches précédentes + adresses ip source et dest), le routage (sélectionner le chemin), la désencapsulation (on transmet le contenu du paquet à la couche supérieure).
Moyen mnémotechnique : Le prénom "Rita".
Le périphérique qui demande l'information est appelé le client, celui qui répond est appelé serveur. Un serveur contient des informations qu'il va partager à de multiples clients, par exemple, plusieurs clients vont demander une page web au même serveur. Un serveur d'impression va transmettre les demandes d'impression des clients à une imprimante.
Dans un réseau P2P (peer to peer) il n'y a pas de notion client/serveur. Chaque périphérique peut jouer le rôle de serveur ou de client. Par exemple, un PC directement connecté à un autre, ou bien deux PC sur un grand réseau partageant des fichiers entre eux.
Il existe aussi des systèmes hybrides, où les fichiers ne sont pas centralisés mais où l'index des fichiers est centralisé.
Les deux protocoles les plus utilisés. L'un s'assure de l'intégrité des données au prix d'une lourdeur de mise en place, l'autre privilégie la vitesse au risque de perdre des données.
Ils utilisent tous les deux la notions de port. Un port permet de filtrer ce que reçoit l'ordinateur. Pour que le client sache vers quel port envoyer ses données, il est défini du côté du serveur (80 pour http, 20/21 pour ftp...). En dessous de 1023, on parle de ports reconnus/réservés. De 1024-49 151 on parle de ports réservés définis par l'Internet Assigned Numbers Authority. Au dessus (jusqu'à 65 535), on parle de port dynamique.
Il n'y a aucune obligation d'utiliser tel port pour tel service. On peut très bien avoir un serveur HTTP qui écoute sur le port 81 au lieu du port 80, mais les clients ne pourront pas deviner où le serveur écoute et ne pourront donc pas accéder au site web. Attention : deux services ne peuvent pas écouter sur le même port.
Le port est aléatoire au niveau du client (par exemple le client ouvre le port aléatoire 50654 et le serveur le 80 pour HTTP afin d'établir une communication).
La commande netstat permet de voir les ports ouverts sur sa machine.
TCP est un protocole établissant une connexion full duplex entre 2 applications dialoguant sur 2 ordinateurs ("circuit virtuel"), chaque connexion correspond à un port.
Détection et traitement des erreurs, compression des données, sélection de la méthode de division des données, adressage des paquets de données, retransmet les paquets perdus, garantit la transmission dans l'ordre. Toutes ces fonctionnalités (notamment l'accusé de réception et la retransmission en cas d'erreur) imposent donc une surcharge sur le réseau.
Le récepteur doit aussi garder en mémoire les paquets arrivés dans un mauvais ordre pour les réassembler. C'est le numéro de séquence (ou numéro d'ordre) qui indique l'ordre des paquets. Ce numéro est incrémenté du nombre d'octet ayant été transmis. Par exemple, en commençant par l'octet 1, un PC indique qu'il envoie 10 octets. Le prochain numéro de séquence sera donc 11. S'il envoie là aussi 10 octets, le prochain numéro de séquence sera 21, etc. Normalement, il faudrait un accusé de réception à chaque fois, mais on peut demander un accusé après X données, c'est la "taille de la fenêtre". Augmenter cette taille peut faire baisser l'encombrement sur le réseau car moins d'accusés sont envoyés, attention quand même sur des réseaux peu fiable peu faire augmenter le nombre de paquet retransmis pour cause de défaillance. La taille de fenêtre est géré de façon automatique, selon le nombre de pertes ("fenêtre coulissante").
Le client envoie par exemple 3 segments, le serveur répond avec un accusé de réception. S'il n'a pas reçu cet accusé, le client renvoie les 3 paquets. Il existe aussi un système d'accusés de réception "sélectifs", qui ne redemande que les paquets perdus.
Protocole "fiable", un peu lourd, utilisé avec des protocoles nécessitant que les données arrivent exactement dans leur état d'origine, avec des données très longues, comme HTTP, POP3, FTP.
Les segments TCP comportent un en-tête (avec port source 16 bits, port destination 16 bits, n° de séquence 32 bits, n° d'accusé de reception 32 bits, longueur de l'entête + divers flags tels que ACK pour indiquer qu'il s'agit d'un accusé, SYN utilisé pour l'établissement d'une connection, FIN pour la fermeture de connexion, RST reset de connexion, PSH remise des données à la couche supérieure, URG pour indiquer données urgentes -le tout pour 16 bits, un champ windows pour indiquer le nombre d'octets que la session peut recevoir sans accusé de réception ("contrôle de flux") 16 bits, un checksum de 16 bits, la position urgente de 16 bits), des options facultatives sur 0 ou 32 bits et enfin un champ de données de taille variable. L'ensemble est passé à la couche inférieure (IP), puis inséré dans une trame.
Exemple de trame ethernet contenant du TCP :
La trame est convertie en hexadecimal pour que ça soit plus facile à lire.
E5 en hexadécimal est équivalent à 1110 0101 en binaire :
1110 devient 14 en décimal, qui devient donc E en hexadécimal.
0101 devient 5 en décimal, qui reste à 5 en hexadécimal.
Penser qu'un symbole hexa est équivalent à 4 en binaire, donc "sur 4 bits". les symboles hexa sont regroupés par 2 car on travaille souvent en octets (sur 8 bits). 08 en hexadécimal vaut 0000 01000 en binaire.
Exemple :
Pour distinguer les notations décimales/hexadécimales des chiffres de 0 à 9, on ajoute "0x" devant le chiffre. Par exemple, "0x8" indique qu'on travaille en notation hexadécimale (il vaut 8 en décimal et 1000 en binaire).
Plus d'informations sur frameip.com
D'autres infos sur lovemytool.com
Autres explications sur packetlife.net
*Entête Ethernet
Adresse MAC destination : 08 00 2B E5 BF
Adresse MAC source : 00 00 E8 C7 49 6A
Indique qu'il s'agit du protocole IP : 08 00
Entête IP
Version : 4
IHL ("Internet header lengh", longueur de l'entête ip) : 5
Type de Service (TOS, Type Of Service) : 00
Longueur totale du paquet ip : 00 35
Numéro d'identification du paquet (en cas de fragmentation plus tard) : 00 04
Flags (indique si sera suivi d'un autre paquet, si fragmentation autorisée) : 00
Position fragment : 00
TTL (durée de vie maximale du paquet décrémenté d'un chaque routeur, ici à 60 en décimal) : 3C
Protocole utilisé (01 ICMP ; 02 IGMP ; 06 TCP ; 17 UDP) : 06
Checksum (qui devra être recalculé à chaque routeur car TTL change) : 80 B9
IP source (126.0.0.4) : 7E 00 00 04
IP destination (126.0.2.2) : 7E 00 02 02
En image sur sixscape.com
Entête TCP
Port source (en binaire 0000 0000 0000 0000, en décimal 1024+1 = port 1025) : 04 01
Port destination (en binaire 0000 0000 0000 0000, en décimal 16+4+1 = port 21): 00 15
n° de séquence : 00 08 0C 09
n° de reçu : 11 84 60 3B
Longueur de l'entête + réservé + bits de code : 50 18
Champ windows : 0B 40
Checksum : 1E A3
Champ urgent : 00 00
Données
Se traduisent par "User Colomb" : 55 53 45 52 20 63 6F 6C 6F 6D 62 0D 0A
Couche transport dans le modèle TCP/IP et OSI.
Pour établir une connexion TCP :
1) Le client envoie au serveur un SEQ numéro de séquence (aléatoire) contenant le flag SYN (disons, 100).
2) Le serveur répond avec les flags SYN et ACK (avec le numéro d'ordre+1, n° de reçu, donc 101) et génère un nouveau numéro de SEQ (200).
3) Le client répond avec le numéro de séquence égal au numéro d'ordre (101) et le numéro de reçu égal au numéro de SEQ+1 (201).
L'attaque SYN flood se passe lorsque le client saute volontairement l'étape 3, pour laisser le serveur en attente d'une réponse. Un
Pour fermer la connexion TCP, 4 étapes :
1)Le client envoie FIN.
2)Le serveur répond avec un ACK.
3)Le serveur envoie à son tour un FIN.
4)Le client répond avec un ACK.
Bonne explication sur firewall.cx
Protocole simple, sans connexion, pas de négociation, pas d'accusé de réception, pas de numéro d'ordre pour les datagrammes (les données peuvent arriver dans un ordre différent de l'ordre d'envoi, par exemple si elles ont pris des chemins différents).
Utilisé dans des applications nécessitant de la vitesse et moins de lourdeur, par exemple la lecture de video, la téléphonie sur IP ou les jeux en lignes : si un paquet n'arrive pas, c'est quasiment invisible vu le nombre de données envoyées. Il est également utilisé pour les DNS (sauf dans le rare cas où une réponse dépasse 512 octets, à ce moment TCP est utilisé), TFTP, RIP, SNMP, DHCP.
Le datagramme UDP est composé uniquement du port source, port destination, longueur du message UDP en octet, checksum. Chacun de ces champs est sur 16 bits, ils sont suivis des données.
Attention, UDP n'est pas fiable mais ça ne signifie pas que les applications qui l'utilisent ne le sont pas. Il est tout à fait possible de mettre en place une système de vérification des données dans la couche supérieure. Pour certains protocole ,par exemple pour DNS, la requête est réémise en cas d'absence de réponse.
Plus simple à gérer et à dépanner. 3 couches distinctes : couche d'accès (les périphériques finaux et les switch/hub/où ils se branchent, établissement de VLAN), couche de distribution (délimite les domaines de diffusion, fait de la QoS...) et le coeur du réseau (la voie principale empruntée par le trafic, se connecte éventuellement à internet).
Il existe un modèle plus simple, le "modèle fédérateur", qui regroupe la couche de distributions et le cœur du réseau.
C'est une séparation logique : au niveau physique, la couche d'accès et la couche de distribution pourraient très bien être dans le même local technique.
Un modèle de réseau hiérarchique est plus simple à faire évoluer, redondant (sauf la couche d'accès en général), plus facile à gérer, maintenir, sécuriser et rendre performant.
Le diamètre maximal du réseau est le nombre maximal de périphériques entre une machine et une autre. Ce diamètre est à prendre en compte lors du plan : on peut fait en sorte que la couche d'accès de l'équipe des graphistes ait un faible diamètre jusqu'au serveur qui leur est réservé. Il faut analyser les besoins des communautés d’utilisateurs pour faire un agencement physique et logique cohérent.
On peut agréger la bande passante en connectant deux switchs avec plusieurs câbles (technologie EtherChannel chez Cisco). Dans un plan logique de réseau on utilise un ovale sur un lien pour indiquer une agrégation de bande passante. On peut créer de la redondance en créant différents chemins entre les switchs de la couche de distribution ou du coeur : par exemple, pour aller de la machine A à C, on pourrait mettre un lien direct ET un lien qui passe par B. Si un chemin est en panne, l'autre est utilisé.
Pour la couche de distribution ou le coeur du réseau il faudrait donc dans l'idéal un switch capable de redondance, QoS, agréagation de liaison, ACL, composants redondants (double alimentation pour en remplacer une si l'autre grille), disposant d'un débit élévé.
il y a des besoins différents pour la couche d'accès : aggrégation, PoE, sécurité des ports (quel périphérique peut se connecter à ce port), VLAN.
Le protocole ip fonctionne sans connexion : elle n'est pas établie avant l'envoi de données, l'hôte ne sait pas à l'avance que le paquet arrive et l'expéditeur ne sait pas si l'hôte est là/si le paquet arrive. Le protocole IP est "non fiable" (pas d'accusé de réception, de renvoi de paquets, d'assemblement dans le bon ordre...), il ne garantit pas l'envoie des paquets, c'est le travail des couches supérieures comme TCP.
Il est indépendant du support de transmission des données (wifi, fibre optique, ethernet...). Le support détermine néanmoins la taille maximale tu paquet (MTU). La couche liaison de donnée passe à la couche réseau la taille maximum du paquet. Parfois, lors d'un changement de réseau, un routeur doit "fragmenter" le paquet, c'est à dire le découper en plusieurs paquet (avec chacun sa propre entête IP). La couche TCP peut spécifier un "Maximum Segment Size" (mss). Plus d'infos sur nain-t.net
L'adresse ip permet d'identifier un hôte au niveau de la couche 3. L'adresse ip est en quelque sorte l'adresse postale de l'ordinateur (l'adresse mac serait son nuémro de sécurité social).
Le protocole ip permet l'établissement d'un réseau logique, à ne pas confondre avec un réseau physique (deux appareils ou plus connectés à un support commun). Deux machines peuvent être dans le même réseau logique sans être sur le même emplacement géographique (VPN).
Une adresse IPv4 comporte 32 bits, 4 fois 8 bits (4 fois 8 bits) : 00000000 00000000 00000000 00000000
On peut convertir cette adresse en décimal pour que ça soit plus facile à lire.
Par exemple, pour le premier octet :
On a 128+64+0+0+0+0+0+0=192.
Pour le deuxième octet :
On a 128+0+32+0+8+0+0+0=168.
En décimal, elle se lit donc : 192.168.2.1
Une partie de cette adresse indique le réseau, une autre partie indique l'hôte. On peut choisir quelle partie indique quoi avec un masque de sous réseau. Selon les situations, on pourra vouloir peu de réseaux avec beaucoup d'hôtes, ou beaucoup de réseaux avec quelques hôtes.
Diviser un grand réseau en plusieurs permet d'améliorer les performances. On peut diviser un grand réseau en plusieurs selon différents critères : géographique (si la distance est grande), par secteur d'activité (un même secteur génère un trafic réseau proche, par exemple le secteur des graphistes va échanger de lourdes données / le secteur des vendeurs en échangera moins), par besoin d'accès (on peut vouloir se connecter depuis l'extérieur à ce réseau mais pas celui-là).
Un masque de sous-réseau indique quelle partie de l'adresse IP représente le réseau.
Par exemple, pour l'ip 00001001.00000000.00000000.00000001, autrement dit "11.0.0.1". On pourrait décider que les 8 premiers bits indiqueraient le réseau (et donc les 24 derniers indiquent l'hôte sur ce réseau). Ce qui s'écrit simplement "11.0.0.1/8". On parle de "préfixe /8", c'est la notation CIDR (Classless Inter-Domain Routing).
Le masque pourrait également se noter en décimal "255.0.0.0". Ce qui donne, en binaire : 11111111.00000000.00000000.00000000, ce qui revient au même que de noter "/8". Dans cet exemple, il y a donc 255 réseaux possibles. Dans un seul de ces réseaux, il peut y avoir (256*256*256) 16 777 216 machines (moins 2 pour l'adresse réseau et celle de broadcast, voir plus bas).
On pourrait aussi mettre un masque en 255.255.255.0 (autrement dit, préfixe /24). Dans ce cas là, il y a 16 777 214v réseaux possibles et 255 hôtes dans chacun de ces réseaux.
/8 (autrement dit 255.0.0.0 ou 11111111.00000000.00000000.00000000), /16 (autrement dit 255.255.0.0 ou 11111111.11111111.00000000.00000000) et /24 (autrement dit 2555.255.255.0 ou 11111111.11111111.11111111.00000000) sont des masques très utilisés.
Le masque donne le nombre de machines qui nous entourent.
Les IP sont divisés en classes A, B, C, D et E. Autrefois, cela dispensait d'utiliser les masques réseaux pour certains protocoles. On pouvait déduire l'adresse réseau selon sa classe. C'est "l'adressage par classe". Par le passé, une entreprise se voyait attribuer un bloc d'adresse d'une classe. Certaines entreprises possèdent encore des ip de classe A et ont donc à leur disposition 16 millions d'adresses.
Une ip de classe A (de 1.0.0.0 à 127.0.0.0 -soit les adresses commençant par 0 en binaire, "bits d'ordre haut") avait un masque de 255.0.0.0, une B de (128.0.0.0 à 191.0.0.0 -adresses dont les bits d'ordre haut commencent par 10) avait un masque de 255.255.0.0, une C (192.0.0.0 à 223.0.0.0 -commençant par 110 en binaire) avait un masque /24.
Plus d'infos sur wikipedia
Aujourd'hui, tous les protocoles récents supportent les masques réseau, donc la notion de classe n'est plus aussi importante. On retrouve tout de même cette notion encore aujourd'hui dans windows par exemple quand on renseigne une ip : le sous-réseau proposé automatiquement est celui de la classe de l'ip qu'on vient de taper.
Ou "VLSM" (Variable Length Subnet mask).
On est pas obligé de se limiter à /8 (255.0.0.0), /16 (255.255.0.0) ou /24 (255.255.255.0). On peut très bien indiquer que les 25 premiers bits indiquent le réseau. On aura donc : 11111111.11111111.11111111.100000 ou 255.255.255.128, autrement dit /25. Ici, si on applique ce masque à une adresse de type 192.168.1.x, il y aura 2 sous réseau : un premier de 192.168.1.1 à 192.168.1.127, un deuxième de 192.168.1.128 à 192.168.1.255.
Cette technique permet de donner le nombre exact d'ip nécessaires pour un réseau.
Par exemple, imaginons que l'on veuille faire 3 sous réseau avec 100 hôtes dans le premier, 50 dans le deuxième et 25 dans le troisième.
On aura :
-192.168.9.0/25
-192.168.9.128/26
-192.168.9.192/27
Il existe finalement assez peu de VLSM possibles :
00000000 = 0
10000000 = 128
11000000 = 192
11100000 = 224
11110000 = 240
11111000 = 248
11111100 = 252
11111110 = 254
11111111 = 255
Un calculateur de VLSM
L'adresse réseau est la première adresse du réseau.
Par exemple, l'adresse réseau de la machine 192.168.2.1/24 est 192.168.2.0, l'adresse réseau de la machine 10.2.3.4/8 est 10.0.0.0.
Dans une adresse réseau, tous les bits représentant l'hôte sont à 1. Elle est toujours paire.
Ou "domaine de diffusion". Un broadcast est un message envoyé à tous les membres d'un réseau. En général, il s'agit du message d'un ordinateur qui veut communiquer avec une machine dont l'adresse ip lui indique qu'elle se trouve sur le réseau sans qu'il sache précisément qui elle est. Il envoie alors son message à tout le réseau dans l'espoir qu'elle réponde (voir la partie "requête ARP").
Créer des sous réseau limite la diffusion des messages de broadcast et améliore donc les performances.
L'adresse de diffusion est la plus haute adresse du réseau. Par exemple, l'adresse de diffusion de 192.168.2.1/24 est 192.168.2.255, celle de 10.0.0.0/9 sera 10.127.255.255. Elle est toujours impaire.
Pour calculer le nombre d'hôte, on utilise la formule "(2 puissance (le nombre de bits laissés pour les hôtes)) moins 2".
Par exemple, si on a besoin de 1000 hôtes :
2*2*2*2*2*2*2*2*2*2=1024
Il faut donc laisser 10 bits dans l'adresse pour les hôtes. Le réseau sera donc en /22 :
255.255.252.0, par exemple 192.168.0.0/22 (2^6=64 donc 4 sous-réseaux, donc adresse de broadcast 192.168.3.255).
Ensuite, on peut découper encore une fois ce nombre d'hôte, par exemple en 2, pour avoir un réseau 192.168.0.0/23 (255.255.254.0, adresse de broadcast 192.168.1.255 car 2^1=2, donc 128 sous réseaux) contenant 500 hôtes.
On peut encore découper, pour avoir, à la fin, un sous réseau de 500, un autre de 200, un autre de 40, par exemple.
Penser à toujours commencer le découpage par le plus gros. Travailler sur papier et s'assurer que les sous-réseaux ne se superposent pas.
Un outil pour calculer
Une adresse 178.155.23.188/18.
1)On calcule à quoi correspond le /18. C'est un /16 (255.255) + 2 bits (128+64).
11111111.11111111.11000000
Donc le masque en notation décimale est 255.255.192.0.
2)Combien y a-t-il de sous réseau (sans compter les octets complets) ? 192 est un masque, il faut l'appliquer à l'envers, sans oublier le 0 : 256-192=64. 4 réseaux.
Autre technique plus simple qui exploite le fait que le binaire fonctionne en puissance de 2. Prendre les bits des octets incomplets et mettre en puissance de 2. Ici, il y a 2 bits, on les met en puissance de 2. 2^2 (c'est à dire 2*2) =4 sous-réseaux.
3)On regarde dans quel sous-réseau se situe 178.155.23.188. C'est le "23" qui est à observer ici, il est inférieur à 64, il se situe donc dans le premier sous-réseau.
4)On peut donc déduire l'adresse réseau : 172.155.0.0 et l'adresse de broadcast : 172.155.63.255.
Une adresse 143.254.190.250/29 :
1)/29, c'est /24 plus 5 bits (128+64+32+16+8), donc 248.
2)2^5 (2*2*2*2*2) = 32 sous-réseaux. 256/32=8, tous les 8. C'est aussi là où est le tout dernier bit.
3)On essaye le multiple de 8 qui se rapproche le plus du nombre recherché (250). 8*30=240. On voit qu'on peut rajouter 8, 248, mais pas plus sinon ça dépasse 250. Donc il est dans la tranche 248 et 255.
4)Adresse réseau 143.254.190.248. ; broadcast 143.254.190.255.
Une adresse 179.75.197.132/25 :
1) /25 c'est /24 qui est connu (255.255.255.0) auquel on rajoute 1 bit. Donc 255.255.255.128
2)Combien de sous-réseaux ? 2^1 = 2.
3)Adresse dans le 2e sous-réseau car 132 est supérieur à 128.
4)Adresse réseau : 179.75.197.128 ; broadcast 179.75.197.132
Une adresse 167.55.131.128/22 :
1)/22 ça ressemble à /24 qui est connu. Donc 255.255.255.0 moins 2 bits, c'est à dire 2+1. Donc 255.255.252.0.
2)Combien de sous réseaux ? 2^6=64.
3)C'est tous les 4 (64*4=256). Adresse entre 128 et 132.
4)Adresse réseau : 167.55.128.0 ; Broadcast : 167.55.131.255
On veut faire un réseau de 28 personnes, un autre de 12 personnes, en prenant le moins de place possible. 192.168.1.0
1)28 personnes, il faudra prendre des tranches de 32. 24=tranche de 255, /25=2 tranches de 128... /26 4 tranches de 64... Ce sera donc /27.
192.168.1.0/27
Le réseau ira donc jusqu'à 192.168.1.32.
2)Pour celui de 12 personnes, on va utiliser les tranches de 16, donc 192.168.1.32/16.
On veut deux réseaux. Réseau A avec 110 hôtes utilisant 192.168.7.0 et réseau B avec 54 hôtes.
A) 110 hôtes, c'est proche de 128, or 256-128=128. Le masque sera 192.168.7.0/255.255.255.128. C'est rajouter un bit : /25. L'adresse du routeur pourrait être la dernière, 192.168.7.126.
B) 54 hôtes, c'est proche de 64, or 256-64=192. Le masque sera 192.168.7.0/255.255.255.192. C'est rajouter 2 bits donc : /26. L'adresse du routeur pourrait être 192.168.7.190.
On veut 2 réseaux, un de 174 hôtes et un de 60, en prenant le moins de place possible.
1)192.168.1.0/24, dernière adresse d'hôte 192.168.1.254.
2)192.168.2.0/26, dernière adresse d'hôte 192.168.2.62.
//www.subnettingquestions.com/ posent ce genre de question :
Combien de sous-réseaux et d'hôtes par sous réseau pouvons nous obtenir à partir du réseau 172.28.0.0/26 ?
En /26 (ou 255.255.255.192), le nombre d'hôte est assez évident. Pour le trouver, calculer "256-192" ou compter les bits libres :
11111111.11111111.11111111.11000000 = 6 bits, donc 32+16+8+4+2+1 (+1 pour prendre en compte le 0).
64 emplacements disponibles, auxquels on enlève broadcast et réseau, donc 62 hôtes possibles.
Combien de "sous réseaux" ? La question peut sembler étrange mais c'est un problème de vocabulaire : 172.28.0.0 est un réseau de classe B, sont masque devrait être de /16, donc les 10 bits qui viennent après sont considérés comme étant un "sous-réseau".
Donc en additionnant ces bits pour avoir le nombre maximum de combinaisons qu'il peuvent prendre, on arrive à 512+256+128+64+32+16+8+4+2+1=1023+1 pour prendre en compte le 0=1024.
Donc 1024 subnets et 62 hosts.
Le système utilisé par les machines pour trouver l'adresse réseau avec le masque.
1 et 1 donne 1, 0 et 1 donne 0, 0 et 0 donne zéro.
Les hôtes peuvent communiquer de 3 façon : monodiffusion ("unicast" d'une IP à une seule autre IP), diffusion ("broadcast", à toutes les ip), multidiffusion ("multicast", à plusieurs ip à la fois).
On peut faire un broadcast à un réseau distant (diffusion dirigée, "Directed Broadcast").
On peut effectuer un déploiement windows en multidiffusion pour envoyer les mêmes données à plusieurs machines à la fois, ce qui économise la bande passante car un seul paquet envoyé (et "dupliqué" par le switch).
Certaines Ip sont réservées pour les réseaux privés, par exemple un LAN dans une entreprise :
-de 10.0.0.0 à 10.255.255.254 pour la classe A (10.0.0.0 /8),
-de 172.16.0.0 à 172.31.255.254 pour la classe B (172.16.0.0 /12),
-de 192.168.0.0 à 192.168.255.254 pour la classe C (192.168.0.0 /16).
Ces IP ne sont pas routées sur internet (pour y accéder, elle doivent passer par un NAT, qui va convertir l'adresse, par exemple 10.0.0.1 et 10.0.0.2 seront convertis en 81.12.9.1 par la box adsl).
Les IP ci-dessous sont aussi des IP séservées, non-routées sur internet (il n'y a pas de route vers elles sur internet).
-La plage de 224.0.0.0 à 239.255.255.255 est réservée à la multidiffusion. Le Network Time Protocol fonctionne avec 224.0.1.1. Cette plage-ci, contrairement aux autres réservées, peut être utilisée sur internet, par exemple pour la télévision sur ip ou certaines webradios.
-De 240.0.0.0 à 255.255.255.254, il s'agit d'une plage spéciale d'adresses expérimentales (pour la recherche), peut être utilisées sur internet dans le futur.
-Impossible d'utiliser une adresse commençant par 0 (sauf 0.0.0.0 qui sert à indiquer une route par défaut).
-L'adresse 127.0.0.1 est une adresse de bouclage ("loopback adress"), c'est à dire l'adresse qu'un hôte utilise pour rediriger du trafic vers lui même. Pratique quand on héberge un serveur sur son PC. L'intervalle 127.0.0.0-127.255.255.255 ne doit pas être utilisé. On peut définir d'autres adresses comme étant adresses de bouclage, 127.0.0.1 est celle par défaut.
-De 169.254.0.0 à 169.254.255.255, il s'agit d'adresses APIPA (Automatic Private Internet Protocol Addressing), appliquées lorsque le PC demande une adresse à un serveur mais qu'il n'obtient pas de réponse.
-Les adresses de 192.0.2.0 à 192.0.2.255 sont des adresses pédagogiques, qui servent aux étudiants.
Les adresses routables et accessibles sur internet, elles sont uniques mondialement. Attribuée par l'IANA (Internet Assigned Numbers Authority) et les registres internet régionaux (AfriNIC -African Network Information Centre, APNIC -Asia Pacific Network Information Centre, ARIN -American Registry for Internet Numbers, LACNIC -Latin-American and Caribbean IP Address Registry), RIPE NCC). Le FAI prête des adresses à ses clients. En général, pour les particuliers, on a une adresse par ligne téléphonique.
ICMP (Internet Control Message Protocol) sert à véhiculer des messages d'erreurs et de contrôles entre les hôtes. L'utilitaire ping utilise le protocole ICMP et les messages Echo Request/Echo Reply. Il existe également le message "ICMP Destination Unreachable" qui peut être envoyé si un hôte ne sait pas où envoyer le paquet. Le message "Time Exceeded" indique que le TTL du paquet ip que le routeur vient de recevoir est à 1, il le décrémente à 0 et envoie le message. Un message "Route redirection" peut aussi être émit pour indiquer qu'une meilleur route est disponible.
Route redirection (Redirection de la route). Un hôte peut aussi indiquer "Source Quench" pour dire qu'il commence à saturer et demander que l'envoyeur baisse la fréquence d'émission des messages.
IPv6 a plusieurs avantages par rapport à IPV4 :
-Adressage sur 128 bits, donc beaucoup plus d'adresse disponibles.
-Entête simplifiée.
-Un emplacement dans l'entête pour étiquetter le flux afin de faire de la QOS.
-Element d'entête facultatif sur 8 bits pour évolution future ou personnalisation.
-Pensé pour la sécurité (IPsec a été penser en premier lieu pour marcher avec IPV6).
IPv6 s'inscrit dans toute une suite de protocoles, par exemple ICMPv6.
Une adresse IPv6 se compose de 8 champs de 16 bits exprimés en hexadécimal, par exemple :
2001:0db8:0000:85a3:0000:0000:ac1f:8001
Elle prépare les données pour le transfert sur le support physique. Elle permet au protocole de la couche supérieure (IPv4, par exemple) de ne pas se soucier du support sur lequel il est transporté (éthernet, wifi, fibre...) Les protocoles de cette couchent spécifient le format de la trame qui va encapsuler un paquet. Les trames seront différentes selon les supports. Un routeur peut modifier la trame. Une séquence de bits détermine le début et la fin de la trame (diverses techniques sont utilisée pour éviter que les données ne soient vues comme des délimiteurs, "delimiter collision", voir cette page bien détaillée en japonais.
Divisée en 2 sous-couches :
-LLC (Logical link control) : indique les VLAN, type de protocole encapsulé, aquittement, contrôle d'erreur, QoS, indication d'encombrement).
-MAC (Media Access Control) : assure l'adressage, formate les données de manière appropriée selon le support, place/récupère les données sur les supports, encapsulation, détection des erreurs, détermine si la trame peut être envoyé, s'il n'y a pas eu de collision avec d'autres trames.
Le champ contrôle d'erreur (checksum) est calculé lors de l'émission de la trame selon le contenu puis recalculé à l'arrivé selon la même formule, si le résultat n'est pas le même, les données ont été corrompues pendant le voyage et la trame est ignorée. On peut aussi parfois utiliser un CRC (Cyclic Redundancy Check, contrôle de redondance cyclique, un peu plus complexe qu'un checksum) pour contrôler l'intégrité des données. La quantité d'informations de contrôle requise dépend du support : par exemple, moins de contrôle nécessaire sur un support par câble que par ondes satellites.
Contrairement à beaucoup de protocoles de la couche supérieure, les protocoles de cette couche ne sont pas décrits dans un RFC (un document décrivant le protocole, "Request For Comments") mais par des organismes internationaux de normalisation car elles sont très liées au matériel tel que les carte réseau (en anglais "NIC", Network Interface Card). Ainsi, les normes wifi sont gérées par l'IEEE.
Quelques organismes :
UIT : Union internationale des télécommunications, département des nations unies.
IEEE : Institue of Electrical and Electronics Engineering, élabore les normes informatiques et électronique (IEEE 802 pour les LAN et MAN).
ISO : organisation internationale de normalisation. A créé la norme OSI (système de couches).
IAB : Internet Architecture Board, supervise développement technique et structurel d'internet.
CEI : Commission Electronique Internationale.
ANSI : American National Standard Institute.
TIA/EIA : Telecommunication Industry Association et Electric Inustrie Alliance, met en place des normes concernant l'industrie électronique.
En Full Duplex les périphériques peuvent écouter et recevoir en même temps, en Half Duplex ils ne peuvent que recevoir ou que écouter.
Une trame de type Ethernet II, encapsulant un datagramme IP encapsulant lui même de l'ICMP :
[Trame Ethernet]
AA AA AA AA AA AA AA : Préambule (7 octets). Chaque A représente "10101010" en binaire.
AB : "Start of Frame delimiter", "SoF" (1 octet), "10101011", sert de délimiteur pour annoncer la trame.
00 24 2c 2c e2 85 : Adresse MAC de destination.
54 04 a6 63 ca 77 : Adresse MAC source.
08 00 (2 octets) : indique ici type de protocole encapsulé (IP). Ce champ peut aussi être utilisé pour indiquer la taille de la trame (si inférieur à 1500 en décimal).
[Datagramme IP]
45 : longueur de l'en-tête.
00 : Type de Service (TOS, Type Of Service).
00 3C : Longueur totale du paquet ip (60 octets).
32 C3 : Numéro d'identification du paquet (en cas de fragmentation plus tard).
00 : Flags (indique si sera suivi d'un autre paquet, si fragmentation autorisée).
00 : Position fragment.
80 : TTL (durée de vie maximale du paquet décrémenté d'un chaque routeur, ici à 128 en décimal).
01 : Protocole utilisé (01 ICMP ; 02 IGMP ; 06 TCP ; 17 UDP)
84 93 : Checksum (qui devra être recalculé à chaque routeur car TTL change).
C0 A8 01 0E : IP source (192.168.1.14)
c0 a8 01 0c : IP destination (126.0.2.2)
A noter : en ethernet, on a destination puis source, en IP on a d'abord la source puis la destination.
[Segment ICMP]
08 : Type de requète ICMP, ici une demande d'echo.
00 : code d'erreur.
4D 2F : Somme de contrôle.
00 01 : identifiant (n° du ping, varie selon les versions de Windows, assigné à un processus sous linux).
00 2C : Numéro de séquence (nombre aléatoire qui reset au démarrage de windows).
00 00 00 00 00 00 00 00 69 6a 6b 6c 6d 6e 6f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 69 : Pour remplir le paquet (si le datagramme est plus petit que 28 octets il est invalide).
[/Segment ICMP]
[/Datagramme IP]
18 45 AA B1 : Séquence de contrôle de la trame (exemple fictif)
[/Trame Ethernet]
La couche physique créé les signaux électriques, lumineux, ondes radios représentant les bits. Elles peut ajouter ajouter un signal pour indiquer le début d'une trame de couche 2 (en plusn par exemple du préambule Ethernet lui-même, la couche 1 créé ses propres séparateurs). Ce sont les mêmes organisations internationales de normalisation que celles de la couche 2 qui définissent les protocoles. Ils définissent les propriétés électriques/mécaniques, définissent la façon dont sont envoyés les informations de contrôle, la représentation du binaire (durée d'un bit, puissance du signal..."méthode de signalisation" ou "codage"), les voltages, les types de connecteurs, etc. de façon à ce que le matériel reste compatible.
Un bit peut être représenté de différentes façons : par variation de la tension, par variation de la fréquence (fréquence basse+0, élevée=1 par exemple), variation de phase. Les hôtes utilisent une horloge pour mesurer ces variations.
Différents exemples de codages chez workig.free.fr
La méthode non-retour à zéro ("NRZ") utilise la variation de tension. Elle est sensibles aux interférences, ne peut pas être utilisé pour les connections à haut débit. Lorsque plusieurs 0 sont envoyés à la suite, aucun signal n'est transmis, ce qui peut être interprété comme une perte de connexion. Lorsque plusieurs 1 ou 0 sont transmis à la fois, difficile de savoir combien ont été envoyés car il n'y a pas de séparation.
Le Codage Manchester utilise les transition de tension. Par exemple, une transition d'une tension faible vers une tension élevée peut représenter le 1. Une transition d'une tension élevée vers une tension faible représenterait le 0. Pour envoyer une suite de 5 zéro, on pourrait baisser la tension 5 fois. Utilisé pour l'Ethernet 10BASE-T (câbles cat 3).
Parfois, une séquence de signaux n'est pas égal à la même séquence de bits. On parle de "groupe de code". Par exemple, la séquence "1010101010" pourrait être codé "10011001100", ou bien "1111111" être codé en "1010110001" afin de réduire les erreurs, améliorer la détection des bits de données et limiter l'énergie transmise sur le support (si on utilise le codage Manchester pour envoyer des paquets de 1, la tension ne cesserait de monter). Voir par exemple le groupe de code "4B/5B".
http://en.wikipedia.org/wiki/Rollover_cable|Plus d'info
Le matériel réseau peut s'échanger des informations avec le protocole LLDP. Pour connaitre le numéro du port et le nom du routeur sur lequel on est branché, lancer wireshark et filtrer en utilisant "lldp" ou un programme du type haneWIN LLDP Agent. Peut poser des risques de sécurité (trop d'infos diffusée ou construction de faux paquets LLDP par un pirate).
Attention : lorsqu'on parle de "port" ci-dessous, on parle de port physique, c'est à dire là où se branchent les cables RJ45. Ce ne sont pas les ports logiciel (port HTTP, port Telnet...).
Un concentrateur (ou HUB) renvoie les données reçues sur un port à tous les autres ports. Il peut aussi servir de répéteur pour augmenter la puissance du signal. De moins en moins utilisé car il ne segmente pas le trafic donc diminuent la bande passante disponible. Le débit du HUB est le débit divisé par le nombre de ports. Pas de mémoire, moins cher. Un PC connecté à un HUB verra tout le trafic entre tous les PC.
Cela pose des problèmes d'encombrement du réseau, les PC sont tous dans le même "domaine de collision" (ils se gênent quand ils communiquent). Un seul PC peut communiquer à la fois.
On appelle pont de "niveau 1" (niveau 1 de la couche OSI) un adaptateur entre 2 supports différents, par exemple un adaptateur fibre à CPL, ou un convertisseur Fast Ethernet / Fibre optique. Il ne s'intéresse pas aux protocoles de couche 1.
Possède donc 2 ports.
Un pont de niveau 2, ou "pont éthernet", est une frontière entre un segment de réseau physique et un autre. Ne diffuse pas une trame si il voit qu'elle n'est pas destinée à une adresse mac connue branchée à un de ses ports.
Un pont permet de partager un domaine de collision en 2 (par contre, il ne sépare pas les domaines de broadcast).
Il peut lire les informations ethernet mais pas les modifier.
Très répandu dans les réseaux sans fil.
Ou "commutateurs".
On peut considérer un switch comme un "pont multiport" (donc niveau 2 de la couche OSI). Il sait lire les paquets et déterminer sur quel port renvoyer une trame selon son adresse MAC.
Il encombre moins le réseau qu'un Hub car sépare les domaines de collisions. Il utilise les adresses MAC pour diriger les données.
Pour savoir sur quels ports sont quels MAC, il écoute les trames (mémorise que telle adresse mac vient d'arriver sur tel port). Quand il ne sait pas où renvoyer une trame, il la renvoie sur tout ses ports avec une machine connectée (LED allumée) sauf celui d'entrée pour éviter les boucles.
Des boucles infinies peuvent néanmoins de former si les commutateurs sont reliés entre eux par de multiples liaisons (redondance) : le switch A envoie à tous ses ports sauf celui où il a reçu, le B fait de même, le C aussi... et la trame revient au A. On parle de "tempête de broadcast" quand cette situation empêche le réseau de fonctionner. utiliser le protocole STP (Spanning Tree Protocol) pour éviter les boucles.
Un switch a besoin de mémoire pour faire une table de correspondance mac/port (en général on parle de mémoire CAM, "mémoire adressable par contenu"). On appelle cette table "table de commutation" ou "table de pont" ou encore "table MAC", elle peut être commune à tous les ports ou bien chaque port entrant peut avoir sa mémoire réservée.
Une attaque courante consiste à inonder un switch de fausses adresses MAC : le pirate va envoyer un maximum de fausses adresse mac au switch, ce qui va remplir sa table et lui faire oublier sur quels ports sont branchées les vraies machines. Le switch est alors forcé d'émettre ses paquets sur tous les ports pour les retrouver. En émettant sur tous les ports, il devient alors aussi transparent qu'un HUB, ce qui permet au pirate de lire les paquets.
Il utilise aussi sa mémoire pour réaliser une opération de commutation dite "store and forward" (stockage et retransmission) : il retient la trame envoyée, recalcule son checksum pour voir si elle contient des erreurs (Frame Check Sequence, FCS) puis l'envoie au port correspondant à la MAC du périphérique désigné. Si plusieurs trames doivent être envoyée au même port, il les envoie les unes après les autres.
Certains switchs ne lisent que l'adresse sans calculer le CRC pour ne pas perdre de temps (commutation "cut-through fast forward"). Ils transmettent plus rapidement mais envoient parfois des trames endommagées sur le réseau, qui seront ignorées par la carte réseau à l'arrivé. Il existe une méthode un peu entre les deux, "cut-through fragment-free", qui vérifie uniquement les 64 premiers octets de la trame car c'est souvent là que sont les erreurs. Un switch peut également combiner ces méthodes, et s'adapter selon un seuil d'erreur défini.
Utiliser un switch à la place d'un hub permet de partager le domaine de collision en autant de ports que comporte le switch. En effet, si un PC est connecté à un switch, sur le support qui va jusqu'au PC n'arrivent que des informations destinées à ce PC.
Il ne filtre pas les domaines de diffusion (domaines de broadcast). Un switch enverra un broadcast sur tous ses ports (excepté le port d'origine du broadcast) : si le switch est branché à un autre switch, ce dernier enverra lui aussi un broadcast sur tous ses ports (excepté le port d'origine du broadcast). Un routeur ou la mise en place de VLAN permet de limiter les domaines de diffusion. Schéma explicatif
S'il est full-duplex, c'est à dire que le support peut émettre et renvoyer en même temps (il utilise 2 paires de fils, une paire pour envoyer et une pour recevoir -il faut au minimum une paire de fil pour fonctionner pour établir un courant, un half-duplex utilise une paire, un full-duplex 2 paires), il n'y a plus du tout de problème de collision car les données "aller" ne circulent pas sur la même paire que les données "retour". On parle aussi de "communication bidirectionnelle simultanée".
Un commutateur peut bloquer une trame si le FCS n'est pas bon, si elle est incomplète ou selon des règles programmées.
A noter que certains switch peut opérer au niveau 3 de la couche OSI (couche réseau) s'il analyse les paquets pour faire de la QoS ou des ACL. Même si c'est assez contre-intuitif, il est possible de donner une addresse IP à certain switchs pour les gérer à distance.
Au niveau des coûts, considérer qu'il peut être moins couteux et plus efficace de prendre plusieurs commutateur qu'un seul gros. Plusieurs commutateurs permettent d'avoir de la redondance (plusieurs chemins d'un PC à un autre, passant par des switchs différents), mais il faut prendre en compte qu'il faut
La plupart des commutateurs peuvent s'empiler sur un rack (chassis), leur hauteur est indiqué en "rack unit". Il existe des commutateurs de configuration fixe, d'autres modulaires (qui viennent avec leur propre chassis qur lesquels on rajoute des options). Il existe également des "Commutateurs empilables", qui se connectent entre eux pour fonctionner comme un seul gros switch.
Pour une même taille, deux switchs peuvent avoir une densité de ports différentes (24 ports contre 48 par exemple).
Forwarding Rates/debit de transfert/Capacité de commutation : la quantité maximale de données par secondes pouvant être traitées par le switch. Un switch gigabit 24 ports devra pouvoir traiter 48 Gbits/s en mode bidirectionnel simultané. Si son débit de transfert est de 12 Gbits/s il ne pourra pas fonctionner avec tous ses ports en gigabit. C'est un point important à prendre en compte. Il existe aussi la notion de "fond de panier" pour indiquer la vitesse du bus principal Sur cette page les 2 termes sont utilisés. On peut privilégier un port par rapport à un autre (par exemple donner 1 Gbits/s sur le port d'un serveur et 100 Mbits/s pour les clients, "commutation asymétrique").
Un switch peut également envoyer du courant (Power over Ethernet, PoE, 48 V de tension) pour alimenter un téléphone, une caméra ou un point d'accès sans fil.
Bonnes infos sur STP
802.1D.
STP garantit un chemin unique entre plusieurs switch en bloquant les chemins redondants. Lorsqu'un port est bloqué par STP, rien ne passe sauf les paquets STP, les BDPU (Briged Protocol Data Unit).
Utilise l'algorithme "Spanning Tree" : un commutateur est élu comme base, comme "pont racine" (choisi avec son adresse mac, une valeur de priorité et éventuellement un ID système) puis le protocole calcule pour toutes les destination un chemin vers le pont racine. Il est recommandé de choisir soit même le pont racine en donnant une valeur de priorité basse à un switch pour éviter que ça ne soit décidé avec l'adresse mac. Les ports des autres commutateurs ayant un coût moindre vers ce pont racine sont les "ports racines" (un seul port racine par commutateur). Les ports qui ne sont pas des ports racines et qui acheminent du trafic, ou qui sont sur le pont racine, sont les "ports désignés" (un seul port désigné par lien). Enfin, les ports n'acheminant pas de trafic sont les "ports non désignés".
Au départ, tous les ports sont bloqués pendant 20 secondes pour éviter une boucle avant l'élection du pont racine, chaque commutateur s'identifie comme pont racine en envoyant toutes les deux secondes (hello time) un paquet contenant son id, l'id de pont racine et le coût vers la racine. S'il reçoit un paquet avec un pont racine inférieur, il changera le contenu de son paquet pour y mettre ce nouvel id. Au final, l'ID le plus faible devient le pont racine.
On peut forcer un commutateur à être pont racine sur les cisco avec la commande
Le coût d'un chemin est calculé d'après le nombre de ports traversés et la vitesse de chacun, STP prend le chemin le moins coûteux. Plus la vitesse du port est haute, moins il est coûteux. Le système de coût a été révisé : autrefois, un port avec une vitesse de plus de 100 Mbits/s valait 1, 100 Mbits/s valait 10, 10Mbits/s valait 100. Désormais, un port 10 GBits/s vaut 2, 1Gbits/s vaut 4, 100Mbits/s vaut 19, 10Mbit/s vaut 100. On peut configurer manuellement le coût d'une interface en mode config-if avec la commande
Un switch stocke les infos d'un paquet BDPU selon un timer "Max Age" de 20 secondes. Au bout de ces 20 secondes, sans nouveau BDPU reçu, un nouveau processus d'élection est lancé.
Les ports passent par 4 étapes :
Blocage, n'achemine rien sauf les trames BDPU. Ecoute, se prépare à acheminer, prévient autours de lui (reste 15 secondes dans cet état de "forward delay"). Apprentissage, apprend les adresses mac (reste également 15 secondes dans cet été de "forward delay"). Acheminement, où il fonctionne pleinement. La technologie PortFast de Cisco permet de ne pas passer par l'état d'apprentissage ou d'écoute (s'utilise sur les ports d'accès)
Le STP a été optimisé pour un réseau de diamètre de 7 switchs. On peut changer le diamètre avec la commande
En cas de changement de topologie, un paquet TCN (Topology Change Notification) est envoyé par le commutateur concerné et le timer "max age" tombe à 15 secondes.
Rapid spanning tree protocol (RSTP), reprend certaines idées du rapide PVST+ pour convergence plus rapide. La nouvelle norme qui remplace STP. N'utilise pas de minuteurs, convergences très rapides. Introduit la notion de "Ports d’extrémité", des ports qui ne sont pas reliés à un switch mais à un hôte. Les ports n'étant pas des ports d'extrémités sont des liasons point à point (périphérique à un autre) ou partagée (avec un hub). Les états "blocage" et "écoute" ont été fusionnés dans un état "mise à l'écart".
Per-VLAN spanning tree protocol, qui génère un arbre pour chaque VLAN, PVST+ qui prend en charge l'aggrégation 8021.Q (et non plus uniquement ISL comme son prédécesseur), rapid PVST+ avec des technologies telles que portfast pour une convergence plus rapide.
Multiple STP (MSTP), associe plusieurs réseaux virtuels à la même instance d'arbre, moins de spanning tree nécessaire.
Un routeur fait transiter les paquets d'une interface réseau vers une autre selon des règles. Les routeurs travaillent avec le protocole IP. Ils sont souvent des passerelles d'un réseau vers un autre. Ils peuvent lire et modifier les informations de couche 2 (Ethernet, ils y changent notamment les adresses MAC). Il peut lire les informations de couche 3 (ip) mais ne modifie pas les adresses, sauf s'il s'agit d'un routeur doté de fonctions avancées comme un système de pare-feu ou un NAT (un NAT peut lire/modifier les couches supérieures à 3, on parle de passerelle applicative, "application layer gateway").
Un routeur modifie toutefois dans le paquet IP le champ "TTL".
A chaque routeur traversé, le TTL (Time To Live) d'un paquet ip diminue de 1. Lorsqu'un routeur reçoit un paquet avec un TTL de 1, il le décrémente, le détruit et renvoie un paquet "Temps dépassé" (schéma), ceci afin d'éviter d'avoir un paquet qui tourne indéfiniment en rond.
Un routeur peut servir à connecter des réseaux utilisant différentes technologies. On peut par exemple ajouter une carte ADSL ou une carte fibre à un routeur, pour connecter un réseau local (les PC d'une habitation) à un réseau étendu (WAN, à son FAI).
Lorsqu'un réseau n'est atteignable que par une seule route (un seul routeur dans ce réseau), on parle de "réseau d’extrémité".
ARP (address resolution protocol) permet d'associer une ip à une adresse mac.
Une requête ARP sert à récupérer une adresse MAC selon une ip.
Un PC demande à tous les autres PC si leur IP est celle voulue. Sans réponse à sa requête, un PC enverra alors le paquet à sa passerelle.
Le résultat des requêtes ARP est stocké dans la table ARP,
Un nombre important de périphériques faisant une requête ARP (allumer un groupe de PC qui veulent trouver la MAC de leur passerelle par exemple) peut ralentir le réseau pendant un bref instant.
Empoisonnement ARP : Un pirate peut émettre continuellement des fausses réponses à une requête ARP pour que lorsqu'une machine cible fasse une requête ARP, elle reçoive la réponse du pirate. La machine victime communiquera avec le pirate en pensant que son ip est celle voulue. Une table ARP avec des adresses fixes permet d'éviter un empoisonnement.
Un routeur bloque les requêtes ARP entre 2 réseaux, sauf si il est configuré pour agir en tant que proxy ARP (un proxy ARP répond en utilisant l'adresse MAC d'une de ses propre interfaces, il se fait "passer" pour le périphérique au delà).
Pour donner une adresse à une patte sur un routeur cisco :
-"enable" (rentrer dansle routeur en tant qu'admin)
-"conf t" ("configure terminal", configurer le routeur)
-"interface f0/0" (configure la patte fast ethernet 0/0)
-"ip address 1.2.3.4 255.0.0.0".
On peut aussi définir des adresses de loopback, en utilisant "lo1", "lo2", "lo3" etc. par exemple
Un hôte ne peut pas connaitre les adresses de toutes les machines existantes. Lorsqu'il ne connait pas une adresse, il demande à sa passerelle, un routeur.
Exemple :
A[10.0.0.1] --- [10.0.0.2]B[11.0.0.1]
La machine A veut aller sur le réseau distant 11.0.0.1 qu'elle ne connait pas, elle interroge le routeur B qui est sa passerelle par défaut : le routeur connait ce réseau, car il est connecté directement dessus. Il va modifier dans la trame l'adresse mac de l'expéditeur et la remplacer par la sienne, puis va envoyer la trame vers l'autre réseau.
Plutôt que d'utiliser toujours la même machine pour atteindre un réseau inconnu, on peut aussi indiquer que pour aller à tel réseau, il faudra utiliser telle machine : c'est ce qu'on appelle une route. Dans la mémoire de B (sa "table de routage") est inscrit la route vers 12.0.0.0 : "pour aller au réseau 12.0.0.0, il faut passer par C".
[10.0.0.2]B[11.0.0.1] --- [11.0.0.2]C[12.0.0.1]
Bien penser qu'un paquet peut réussir à faire le chemin de B vers C mais ne réussira pas forcément le chemin inverse. Dans l'exemple ci-dessus, il faut ajouter une route à B mais aussi à C pour qu'un paquet puisse faire l'aller-retour.
Un périphérique ajoute automatiquement à sa table de routage les réseaux sur lesquels il est directement connecté. Les routes peuvent être ajoutés manuellement ("routage statique", pour les petits réseaux, difficile à maintenir, risques d'erreurs) ou échangées de façon automatique entre les routeurs ("routage dynamique" : protocoles RIP, IRGP, OSPF... moins sécurisé car échanges d'infos entre les routeurs, plus facile à mettre en place, utilise ressources système et réseau). Certains routeurs ont une table de routage indiquant plusieurs centaines de milliers de réseaux.
En résumé :
-Le routeur supprime l'encapsulation de la couche 2 (adresse mac).
-Il lit l'adresse de la couche 3 (ip) et regarde s'il connait une route vers le réseau.
-Il met sa propre adresse mac et envoie le paquet.
Une passerelle est donc simplement une route par défaut (on parle aussi de route vers le réseau 0.0.0.0). Il est possible de donner une route par défaut à un routeur, pour lui dire par exemple "si tu dois atteindre un réseau inconnu, passe par tel routeur" ou "si réseau inconnu, envoie via ton interface ADSL".
Il peut exister plusieurs routes pour suivre un même chemin. On privilégiera tout d'abord les routes les plus précises : pour aller à 1.2.3.4 on prendra la route 1.2.3.0 avant la route 1.2.0.0.
Si 2 routes sont identiques, on utilisera alors un chiffre, la métrique. Selon les protocoles, la métrique peut prendre en compte le nombre de routeur à traverser, la bande passante, le coût (valeur que met un administrateur pour privilégier une route), la fiabilité, la charge... La route avec la métrique la plus basse est privilégiée.
Il existe aussi une autre valeur, la distance administrative, qui compare plusieurs protocoles entre eux. Par exemple, une route statique, entrée manuellement par un administrateur, aura une distance administrative plus basse qu'une route envoyée par un routeur inconnu. Seul un réseau directement connecté possède une distance administrative de 0. La valeur de la distance administrative de toute route statique (y compris les routes connectées à une interface) est de 1. Une route avec une distance administrative de 255 ne sera jamais utilisée par le routeur (elle sera absente de la table).
Par exemple, dans cette route statique, la métrique est de 0, la distance administrative à 1.
Dans le cas où il y a deux routes strictement identiques, un routeur divise équitablement les paquets entre les 2 routes, pour ne pas en surcharger une. On parle "d'équilibrage de charge à coût égal" (il existe aussi, avec les protcoles EIGRP et IGRP, "l'équilibrage de charge à coût inégal", diviser les paquets non-équitablement entre 2 routes avec la commande
On peut aussi programmer une route, avec une métrique volontairement assez forte pour qu'elle ne soit pas utilisée en première. Elle ne sera utilisée que si la route habituelle disparait (par exemple, l'interface passe down), on parle de "Routes statiques flottantes".
Si un routeur n'a pas de route vers le réseau demandé ni de passerelle par défaut, il détruit simplement le paquet.
Pour interconnecter 2 réseaux utilisant des protocoles de routage différents( ex: RIP et IGRP), on utilise un protocole EGP (Exterior Gateway Protocol, par ex BGP), dit "protocole à vecteur de chemin". S'oppose aux Interior Gateway Protocol (RIP, IGRP, EIGRP, OSPF, IS-IS...).
Il existe 2 types de protocoles IGP :
On peut diffuser une route statique via un protocole à route dynamique avec la commande
En mode de configuration du terminal (conf t) :
Au lieu de l'ip du prochain routeur, on peut aussi utiliser directement le nom d'une interface, par exemple "Dialer1" ou "Serial0/0/0" lorsqu'on a une connexion point à point. En ethernet, il peut y avoir plusieurs périphériques accessibles par l'interface, donc on doit préciser une ip. Pour éviter que le routeur ne lise l'ip de la passerelle puis chercher à quelle interface elle est directemenbt connectée (recherche récursive), on peut utiliser la commande
On peut aussi utiliser l'adresse "Null0", qui est une interface qui ne mène nulle part. les paquets seront détruits.
Si l'interface qu'utilise une route statique est désactivée, la route disparaitra dans
Impossible de modifier une route statique, il faut la supprimer en ajoutant "no" devant la commande, par exemple
Pour faire une route par défaut :
-Cisco :
-Windows/linux/MacOS :
Protocole de routage à vecteur de distance créé en 1988 qui utilise le nombre de sauts entre chaque routeurs pour la métrique. Nombre de saut maximum : 15. Fonctionne par classe IP (sans VLSM, les masques de sous-réseau de longueur variable) via le protocole UDP (port 520). Utilise le découpage d'horizon et découpage d'horizon avec antipoison. S'appuie sur l'algorithme Bellman-Ford.
Mises à jour envoyées aux voisins toutes les 30 secondes ("minuteur de mise à jour") via broadcast (255.255.255.255, risque de sécurité) ou lors d'évènements tels que la réception d'une nouvelle route, une interface se désactivant, une route devient inaccessible. Lorsqu'un routeur démarre, il va faire une requête aux routeurs adjacents pour récupérer les tables (indique 1 dans le champ "commande" du paquet RIP).
Si une mise à jour n'est pas reçue après 180 secondes la route est indiquée non-valide ("minuteur de temporisation", métrique passe à 16). Après 60 secondes de plus sans réponse, elle est effacée ("minuteur d'annulation"). Pour voir le temps écoulé depuis la dernière mise à jour,
Lorsqu'un routeur reçoit l'information d'une route désactivée, il lance un "minuteur de mise hors service" : il ignorera les infos des autres routeurs avec une métrique supérieur qui lui disent (de façon erronée) que le réseau n'est pas désactivé. Par contre, si un routeur avec une métrique inférieure (donc plus proche de la panne) lui dit que la panne est résolue, il l'écoutera.
En résumé :
-Minuteur de mise à jour : 30s.
-Minuteur d'annulation ("invalid timer") : 180s.
-Minuteur de mise hors service ("holddown timer") : 180s.
-Minuteur d'annulation ("flush timer") : 240s.
Les réseaux directement connectés auront une métrique de 0, un réseau inaccessible aura une métrique de 16.
Comme RIPv1 fonctionne sans VLSM, si un réseau utilisé un masque différent de sa classe (par exemple 172.18.1.0/24 et 172.18.2.0/24), RIPv1 fera de lui même un résumé de route en indiquant une route vers 172.18.0.0. Dans le schéma, tous les routeurs utilisent RIP. Les 2 routeurs dans le résumé 172.18.0.0 n'ont pas besoin de RIP pour connaitre les masques de 172.18.1.0, 172.18.2.0 et 172.18.3.0, ils peuvent les déduire tout seul d'après leurs propres masques. Entre ces 2 routeurs les routes 172.18.1.0, 2.0 et 3.0 seront envoyés en rip. Au routeur restant ne sera envoyé qu'une route vers 172.18.0.0. Le routeur entre le "super-réseau" 172.18.0.0 et 10.0.0.0 est appelé "routeur de périphérie".
La version 2 (RIPv2) a été publiée en 1993, elle prend en charge les VLSM, un système d'authentification, utilise des adresses de multidiffusion et non plus de diffusion, prend en charge le résumé des routes manuelles. Il y a également dans le paquet un champ "route tag" et un champ "Next Hop". Plus d'infos sur ces 2 champs. Un router compatible RIP v1 pourra lire les paquets RIPv2 (il ignorera simplement les champs supplémentaires du paquet -masque, routage et Next Hop.
Il existe une version pour IPV6 développée en 1997, RIPng, utilisant le port UDP 521. Elle ne prend pas en charge l'authentification.
Pour afficher les informations rip reçues (pas forcément appliquée dans la table de routage) :
Beaucoup plus rapide que de configurer des routes statiques, on indique juste les ip des réseaux des pattes du routeurs.
En mode "conf t" :
On peut aussi utiliser "version 2", ou rien du tout, ou "no version" pour utiliser la 1. La version 2 est plus sécurisée, les paquets listant les réseaux sont chiffrés, elle sais gérer les VLSM et fait un résumé automatique des routes (peut être problématique, un ping sur 2 aboutissant peut être un équilibrage de charge entre 2 routes qu'on croit aller au même réseau alors que non, utiliser
"network 192.168.10.0" indique 1)que l'on enverra aux autres routeurs l'information concernant le réseau 192.168.10.0 et 2)que l'on envoie/reçoit des informations rip sur l'interface connectée à cette route. On pourrait vouloir informer les autres routeurs de l'existence de cette route, mais ne pas utiliser RIP sur cette interface, d'où l'existence de la commande, en mode "router rip",
RIPv1 détermine le masque de sous réseau par la classe, donc on pourrait mettre 10.2.3.0, ce il enregistrera 10.0.0.0 dans la running-config.
Les routeurs Cisco ne font pas la mise à jour exactement toutes les 30 secondes, ils utilisent la technique "RIP_JITTER" qui fait varier de 15 à 20% le temps pour éviter que tous les paquets ne soient envoyés en même temps.
Pour diffuser une route par défaut en RIP, utiliser la commande
Distance administrative de 120.
Routage à état de lien (Open Shortest Path First).
Conçu par IETF et version 1 publiée en 1989, jamais utilisé en production. Version 2 en 1991, mis à jour en 98.
Envoie un paquet IP en multidiffusion sur 224.0.0.5 (adresse définie par IETF), n° de protocole 89.
Diffuse les informations sur l'état de ses liens en cas de changement dans la topologie, mais aussi toutes les 30 minutes, par sécurité (alors qu'en tant que protocole à état de lien il n'aurait pas besoin). Le paquet contient le type du paquet OSPF (1 hello, 2 DBD -liste abrégée de la base de donnée, 3 LSR -link state request, 4 LSU -Link State Update pour répondre aux LSR et rajouter des infos, 5 LSACK -Acknowledgement d'un LSU), l'ID du routeur source, l'ID de la zone, le masque de réseau, intervalle Hello, priorité du routeur, intervalle du routeur, routeur désigné, BDR, liste des voisins.
Etant un protocole à état de lien, le routeur va tout d'abord envoyer un paquet "Hello" à 224.0.0.5, qui comprend l'ID du routeur, le type du réseau et l'intervalle des paquets Hello (10 secondes en point à point ou accès à segment multiple, 30 secondes pour Frame Relay, X.25, ATM).
L'intervalle "dead" est défini comme 4 fois le temps requis pour envoyer un paquet Hello, s'il est atteint, le lien est déclaré hs.
Ces intervalles se changent (en cas de besoin, doivent être changés sur tous les routeurs) avec les commandes
Les paquets "LSU" peuvent contenir 11 différents "LSA" (Link-State Advertisement), c'est à dire 11 types de messages concernant les états des liens. Chaque routeur OSPF a une base de donnée contenant ces LSA. Il créé grâce à cette base et l'aide de l'agorithme Dijkstra une arborescence SPF pour fournir à la table de routage les meilleurs chemins vers le réseau.
La distance administrative d'OSPF est de 110. Le protocole est préféré à RIP (120) et ISIS (115) mais pas à IGRP (100) et EIGRP (90).
Pour configurer ospf, deux étapes :
1)
2)
Une routeur OSPF a besoin d'un identifiant unique pour être identifié. On peut lui donner un identifiant avec la commande
Pour voir les voisins,
Pour débuguer,
On peut toujours utiliser la commande
Pour sa métrique, le RFC de OSPF n'impose rien. Les routeurs Cisco utilisent la bande passante. La formule est "10 puissance 8 divisé par le nombre de bit/s". Une liaison à 10 000 000 bits/s vaudra donc "10", une liaison à 128 Kbit/s (100 000 000/128 000) vaudra 781, etc. Avec ce calcul, les bandes passantes 100 Mb/s et plus seront toujours à 1, néanmoins, on peut changer la bande passante de référence avec la commande
Pour choisir un chemin, OSPF additionne le coût des routes jusqu'à sa destination. La route avec le coût le plus faible sera choisie.
Sur les réseaux à accès multiple (pas point à point), pour réduire le trafic, un routeur est désigné pour envoyer les mises à jours vers les autres routeurs (Designated Router). Il est associé d'un routeur désigné de sauvegarde (Backup Designated Router) qui prendra sa place en cas de défaillance. Sans ça, si 6 routeurs étaient branchés sur un switchs, ils seraient tous voisins les uns des autres et génèreraient beaucoup de trafic pour la diffusion des paquets LSU. Le routeur avec l'interface avec une priorité la plus élevée devient le DR (en cas d'égalité, l'ID du routeur est utilisé). Le BDR est celui avec la priorité/l'ID le plus élevée après le DR. les autres routeurs sont appelés DROTHER. La sélection se fait dès le démarrage d'OSPF, si on veut qu'un routeur soit désigné comme DR, l'allumer en premier. On peut aussi modifier les priorités de son interface avec la commande
Un routeur en périphérie d'une zone, entre un système autonome OSPF et non-OSPF s'appelle un "Autonomous System Boundary Router".
Interior Gateway Routing Protocol.
Protocole propriétaire cisco datant de 1985, à vecteur de distance, remplacé par le EIGRP (lui aussi propriétaire).
Plus évolué que le routage RIP, nombre de sauts maximum : 255. Par contre, il s'agit d'un protocole de routage par classe (pas de VLSM). Mises à jours envoyées aux voisins toutes les 90 secondes par défaut (trois fois plus long que RIP).
La métrique IGRP prend en compte la bande passante, la charge, la fiabilité, le délai (20 000 micro-secondes pour connexion série, 1000 micro-secondes pour ethernet), le temps d'attente.
Utilise lui aussi l'algorithme Bellman-Ford.
Distance administrative de 100.
Enhanced Interior Gateway Routing Protocol.
Protocole propriétaire cisco de 1992, pas de mises à jours régulières des tables de routage : uniquement en cas de changements dans la topologie, seule les informations sur la route concernée sont envoyée (pas toute la table, informations "partielles"), aux seuls routeurs qui en ont besoin ("limitées"). A vecteur de distance.
Contrairement à RIP ou IGRP, qui ne conserve dans leur table que la meilleure route et en attendent une meilleure en cas d'indisponibilité, EIGRP utilise une table topologique pour mémoriser toutes les routes reçues, pas seulement les meilleures, pour disposer de routes de secours (
Evolution de IGRP, prenant en charge les VLSM. Un peu moins de sauts (224 sauts). Peut communiquer avec IGRP.
Métrique basée avant tout sur la bande passante et le délai (temps nécessaire à un paquet pour parcourir une route). La bande passante et le délai ne sont pas mesurés en temps réel, il y a des valeurs types selon les interfaces et l'administrateur peut les changer (commande
Pour changer les métrique, utiliser
Convergence plus rapide que les autres protocoles à vecteur de distance grâce à l'absence de minuteurs de mise hors service.
Utilise l'algorithme DUAL (Diffusing Update Algorithm, c'est pour ça que dans la table de routage, EIGRP est indiqué par un D quand l'algorithme est en train d'être calculé). DUAL permet des chemins sans boucles, des chemins de secours, une convergence rapide, une utilisation minimale de la bande passante car màj limitées. La "distance de faisabilité" est la métrique la plus basse vers un réseau de destination. Un "successeur" est le routeur vers où on doit se diriger pour suivre la route. Les successeurs se voient avec
Utilise Reliable Transport Protocol pour s'échanger des paquet, un protocole fiable, avec accusé de reception, qui peut également fonctionner en mode "non fiable" pour prendre moins de ressources Plus d'infos.
Pour vérifier l'état de ses voisins, utilise toutes les 5 secondes un protocole léger ("Hello"), avec RTP en mode non fiable (sur certains réseaux tels que X.25, les paquets Hello sont échangés toutes les 60 secondes). Pour s'échanger des routes, EIGRP utilise RTP en mode fiable, demandant accusé de reception. Utilise également RTP fiable pour faire des demandes.
En résumé, 5 types de paquets : Hello, envoie de route/accusé de réception, demande de route/accusé de réception.
Si un routeur ne répond pas à un HELLO au bout de 3 fois l'intervalle d'envoi d'un HELLO (15s), la route est déclarée hors service et le routeur cherche un autre chemin.
Peut fonctionner avec IP, IPX, Appletalk.
Distance administrative de 90, la distance administrative du résumé de routes IGRP est de 5, la distance administrative de route EIGRP distantes est de 170.
Paquet IP (EIGRP peut aussi fonctionner sur IPX ou AppleTalk) :
Envoie à l'adresse ip de multidiffusion 224.0.0.10 (protocole EIGRP vaut 88) ainsi qu'à une MAC multidiffusion.
Un en tête de paquet IGRP comprend un code opération (1=màj, 3=demande, 4=réponse, 5=Hello), le numéro de système autonome (doit être le même pour un ensemble de routeur sous une même administration utilisant le même protocole de routage. Même si c'est déconseillé, un routeur peut exécuter plusieurs instances d'IGRP en même temps , il se sert de ce numéro entre 1 et 65535 choisi par l'administrateur pour les différencier). Il comprend aussi les constantes, de K1 à K5, que l'administrateur peut modifier pour donner plus ou moins de priorité à la charge (mesurée de façon dynamique), le délai ou la fiabilité (fréquence de mise hors service d'une liaison, mesuré de façon dynamique) dans le calcul de la métrique. Détails du calcul sur wikipedia. Contient également un champ "temps d'attente", qui spécifie combien de temps attendre le prochain paquet "hello".
Ensuite, il est indiqué une route interne : l'adresse du tronçon suivant, le délai, la bande passante, le MTU (n'influence pas le calcul de la métrique), le nombre de sauts, la fiabilité, la charge, la longueur du préfixe, l'adresse du réseau de destination.
Enfin, il est indiqué les routes externes. Les champs sont les mêmes que les routes internes, auquels on va rajouter tronçon suivant, routeur d'origine, numéro de système autonome d'origine, balise arbitraire métrique de protocole externe, ID d eprotocole externe et indicateur.
Pour configurer eigrp :
On peut utiliser un masque générique pour annoncer certains sous réseaux-spécifiques. C'est l'inverse d'un masque de sous-réseau, par exemple si le masque du sous réseau est 255.255.255.252, le masque sera 0.0.0.3. Certaines versions d'IOS permettent d'utiliser directement 255.255.255.252.
Pour changer la fréquence d'envoi de hello :
Pour changer le temps d'attente de la réponse à un Hello :
Pour voir les voisins ayant répondu à hello :
Il est important que le numéro de système autonome soit le même sur tous les routeurs. Pour le voir, un
EIGRP n'utilise pas plus de 50% de la bande passante par défaut. Cette valeur peut être changée avec
Cisco Discovery Protocol, utilisé par les machines cisco connectées directement entre elles (même segment réseau) pour se reconnaitre. Pour avoir des informations sur le status du protocole :
CDP peut poser de sproblèmes de sécurité en diffusant ainsi les adresses.
Pour désactiver globalement :
Pour désactiver sur une interface, se mettre en mode de configuration de l'interface puis
Grâce au protocole CDP, on peut mapper un réseau inconnu en affichant les adresses des voisins sur un routeur, puis se connectant en telnet et affichant le sadresses des voisins suivants, etc.
La table de routage cisco est hiérarchique. L'organisation de son affichage se fait en se basant sur les classes ip même si concrètement les routeurs ne se basent pas sur ces classes (cette forme d'affichage est un reliquat de l'époque où les classes été utilisées).
On trouve tout d'abord les routes de niveau 1 (qui mènent vers un réseau où le masque est inférieur ou égal au masque de la classe ip, ou bien une route par défaut).
On parle également des "meilleurs routes" ("ultimate route", qui mènent vers une adresse de tronçon suivant "via 1.2.3.4", ou vers une interface, on pourrait traduite ultimate par "finale" vue qu'elles indiquent la sortie).
Il existe aussi les routes parents ("network 1.2.0.0/16 is subnetted, 1 subnet") et les routes enfants (appelée "niveau 2"). Quand une route a un masque supérieur au masque de sa classe, une route parent est créée.
Les routes enfants sont des "ultimate route", car elles envoient vers un tronçon suivant ou une interface.
En résumé :
-Routes de niveau 1 meilleures routes = routes dont le masque est égal ou inférieur la classe ip menant vers une sortie.
-Routes de niveau 1 routes parents = route avec un masque correspondant à sa classe ip, contenant une route enfant.
-Routes de niveau 2 (ou "routes enfants) meilleures routes = un masque supérieur au masque de classe ip (ex /16 pour 10.1.0.0), affichées sous une route parent, indiquant une sortie.
Lorsqu'il doit envoyer un paquet, le routeur vérifie tout d'abord la correspondance avec les routes de niveau 1.
-S'il trouve une route de niveau 1 meilleur route, il enverra le paquet par là. Fin.
-S'il trouve une route de niveau 1 parent, il analyse les enfants.
--Si une route enfant correspond, il envoit vers la sortie qu'elle spécifie. Fin.
-Si une route enfant ne correspond pas, il vérifie s'il travaille en classe ou sans classe.
--S'il travaille sur ses tables de routage avec les classes, il détruit le paquet. Il n'essaye même pas route par défaut. Fin.
--S'il travaille sans classe, il recommence à chercher une route qui correspondrait au niveau 1.
---S'il n'y a pas d'autre route correspondante à part la route 0.0.0.0 (passerelle), il l'envoie vers sa passerelle. Fin.
---S'il n'y a pas de passerelle, il détruit le paquet. Fin.
Donc, par exemple, un paquet peut faire : routes de niveau 1⇒ ya une correspondance, c'est une route parent⇒ route de niveau 2⇒sans correspondance et sans travailler par classe⇒route de niveau 1⇒passerelle.
La "meilleur correspondance" est la route qui ressemble le plus à l'adresse où le paquet veut aller.Un paquet qui veut aller en 1.2.3.4 aura une meilleure correspondance avec 1.2.3.0/24 que 1.0.0.0/8. Est pris en compte le nombre de bits correspondants indiqués par le masque de sous-réseau. Par exemple, un paquet voulant aller en 172.16.0.10 aura une meilleure correspondance avec 172.16.0.0/216 que 172.16.0.0/8.
Correspondance de 1 :
Correspondance de 25 :
Il est possible de demander aux routeurs de consulter leurs tables de routage en travaillant par classe avec la commande
Un routeur peut traiter sa table de routage en utilisant les classes, tout en fonctionnant avec un protocole sans classe comme RIPv2.
DHCP (Dynamic Host Configuration Protocol) est un protocole utilisant UDP sur les ports 67 et 68 pour distribuer adresses ip (selon une plage d'adresse, "pool"), masque, adresse de passerelle, serveurs dns, serveurs de temps, etc. Généralement, l'adresse est "louée" pour un certain temps au pc. C'est une extension du protocole BOOTP, qui avait le même objectif.
Le client envoie un paquet DHCP discover (de source 0.0.0.0 à destination 255.255.255.255, port 67) ⇒ le serveur répond (port 68) par un DHCP offer contenant l'adresse mac du client, une proposition d'adresse ip/masque/bail, sa propre ip ⇒ le client sélectionne le premier serveur dhcp qui répond et lui envoie un paquet DHCP request indiquant qu'il accepte et indiquant par là aux autres serveurs DHCP qu'il refuse ⇒ le serveur lui envoie DHCPACK, un accusé de réception.
Pour communiquer avec le client qui n'a pas d'ip, les 2 machines utilisent leur adresse mac (le paquet est émis vers ff:ff:ff:ff:ff:ff au niveau de la couche réseau mais l'adresse mac est indiquée dans les données).
DHCP ne distribue des ip que dans les segments dans lesquels il est directement connecté, sauf si on utilise un relais dhcp. Un relais DHCP permet de n'avoir qu'un seul serveur DHCP pour plusieurs réseaux (plus facile pour la maintenance).
Si windows n'arrive pas à obtenir une adresse DHCP, il attribuera au PC une adresse APIPA (automatic private internet protocol adressing) entre 169.254.0.0 et 169.254.255.255 ou utilisera la configuration alternative précisée dans les paramètres IPV4.
Les serveurs DHCP font aussi souvent office de serveur BOOTP (protocole similaire à DHCP, moins évolué)
Une attaque courante consiste à se faire passer pour le vrai serveur DHCP : le serveur HDCP privilégié étant le premier qui répond, un pirate peut monter un serveur DHCP qui prendra la place du vrai.
Les commandes, dans l'ordre :
-ip dhcp pool (nom du pool)
-network (le réseau dans lequel vous voulez donner des ip) (masque)
-default-router (adresse de la passerelle par défaut pour le réseau)
-dns-server (adresse du ou des serveurs dns)
-lease (nombre de jours, nombre d'heures, nombre de minutes)
On peut retirer des adresses du pool avec la commande :
ip dhcp excluded-adress (ip) (masque)
On peut vérifier les baux attribués par le routeur avec :
show ip dhcp binding
Et l'activité du serveur avec :
show ip dhcp server statistics
Enfin, l'activité en temps réel avec :
debug ip dhcp server events (ou "debug dhcp")
Les routeurs bloquent les broadcast, donc pour qu'une communication DHCP passe à travers un routeur, il faut le transformer en relais.
Se met sur l'interface de la patte qui va dans le pool :
-
Cette commande remplace les adresses de broadcast par des adresses unicast (vers une machine précise, en l'occurrence, l'autre routeur).
L'adresse sera aussi remplacé pour les protocoles : TFTP (69), DNS (53), Time (37), NetBIOS Name Server (137), NetBIOS Datagram service, BOOTP Server (67, ancienne version de DHCP), BOOTP Client (68), TACACS (49).
Pour ne laisser que les ports nécessaires ouverts, on peut utiliser "no ip forward protocol udp 180" en mode conf t, ou utiliser des ACL.
Une access list (ACL) est un ensemble d'instructions pour autoriser ou refuser des paquets en fonction des adresses de destination ainsi que, pour la version étendue, en fonction de l'adresse d'émission, des ports, du type de paquet (icmp, udp, tcp...).
La seule difficulté est le masque générique, qui fonctionne un peu l'inverse du masque normal : les bits à 0 sont vérifiés, les bits à 1 ignorés.
En configurant les ACL, on leur donne un numéro (ou un nom sur les routeurs récents). S'assurer que le numéro respecte une plage : de 1 à 99=ACL standard, de 100 à 199 IP étendue, 600 à 699=AppleTalk, de 800 à 899=IPX standard, de 900 à 999=IPX étendue, de 1000 à 1099=IPX Service Advertising protocol.
Une ACL permet aussi un logging. PArfois on met un "allow" juste pour voir ce qui passe sur le réseau.
une ACL est assez exigeant en terme de ressource.
ACL standard
Modification de l'access list n°1 :
-access-list 1 deny 1.2.3.4 0.0.0.255 (<=on interdit les paquets provenant de 1.2.3.4)
-access-list 1 permit any (<=on autorise tout le reste, absolument à ajouter car par défaut tout est bloqué.)
Puis, on affecte cette ACL à une interface :
-int f0/0
-ip access-group 1 out
Pour voir les ACL :
show access-list
Pour voir à quel interface sont assignées les ACL :
show run
ACL étendue
Syntaxe :
Router (config)#access-list (numero de la liste) ("permit" ou "deny") (protocole à interdire, udp ou tcp) (adresse d'origine) (masque) (adresse de destination) (masque)(opérande lt , gt, eq ou neq -lower than, greater than, equal, not equal) (port ou non du protocole, par exemple 69 ou "web" ou "tftp").
Création de l'ACL étendue n°100 :
-access-list 100 deny udp host 212.16.23.6 host 10.23.4.6 eq tftp
-access list 100 permit ip any any
Le mot host dans la première ligne permet d'éviter de saisir le masque. Il indique qu'on veut vérifier tous les bits.
"permit ip any any" signifie qu'on autorise n'importe quelle ip vers n'importe quelle autre.
Si on veut bloquer ICMP, pas besoin de préciser le protocole :
access list 100 deny icmp host 1.2.3.4 host 5.6.7.8
Assignation de l'interface :
-int f0/0
-ip access-group 100 in
ACL nommées
Comme une ACL étendue mais avec un nom.
Création de l'ACL :
-access-list extended nom_de_l_acl
-deny udp host 1.2.3.4 host 5.6.7.8 eq tftp
-permit ip any any
Assignation de l'interface :
-up access-group stagiaire out
Bon site sur les VLAN
Défini par la norme 802.1Q. Il existe également d'anciennes normes de vlan, telles que ISL.
Un réseau virtuel permet de diviser logiquement un réseau local en plusieurs domaines de broadcast. Autrement dit, avec des VLAN plusieurs réseaux/sous-réseaux IP peuvent coexister sur le même réseau physique (alors que sans VLAN, un routeur est utilisé pour séparer 2 réseaux). Évidemment, si on veut faire connecter ces VLAN, ils doivent passer par un routeur ou par un commutateur de couche 3 ("Routed VLAN Interface" ou "Switch virtual interface").
Concrètement, cela permet par exemple de faire passer différents réseaux dans un seul câble entre deux bâtiments.
Imaginer 3 VLAN, séparés par deux bâtiments : un seul câble relie les deux bâtiments (cable appelé "trunk" , parfois traduit par "agrégation" car il agrège plusieurs VLAN) et à chaque extrémité du câble se trouve un switch. Les paquets vont tout d'abord normalement du PC jusqu'au switch. Puis, entre les deux switchs, les paquets sont "taggés" selon la norme 802.1Q pour savoir vers où les redistribuer.

Sans VLAN il aurait fallu 3 câbles entre les bâtiments.
Le VLAN 1 est le VLAN par défaut, on ne l'utilise pas.
⇒On peut faire des VLAN par port physique, c'est à dire que les ports 2 à 5 sur un switch seront "isolés" dans le VLAN 3, tandis que les ports 6 à 8 dans le VLAN 5, par exemple. C'est le plus simple et le plus utilisé en PME/PMI. On parle parfois de VLAN de niveau 1 mais c'est discutable car ça utilise la couche ethernet.
⇒On peut aussi faire des VLAN par adresses MAC : telle adresse MAC = tel VLAN.Nécéssite beaucoup d'organisation, tenir la liste des cartes réseaux à jour, etc. donc difficile avec plusieurs milliers de machines. En outre peu de routeurs peuvent tenir à jour la bdd des addresses, il faut utiliser un serveur VMPS. Par contre ça permet de se brancher n'importe où et d'être directement dans le bon VLAN.
⇒VLAN par adresse ip. 172 sur un VLAN et 192 sur un autre. Problème, si quelqu'un change son ip il change de VLAN. Autre problème, DHCP (il faudra lui associer des adresses mac à donner à des ip).
⇒Enfin, VLAN par protocole (IP sur tel VLAN, IPX sur tel autre).
Les VLAN opèrent au niveau 2 de la couche OSI (tag dans la trame ethernet) : même si on décide du tag au niveau de l'IP, c'est quand même au niveau 2 que le tag est mis. Des switchs de niveau 3 et des routeurs peuvent être utilisés pour faire communiquer les VLAN entre eux.
Intérêt des VLANS : augmente la sécurité (séparation du trafic), moins de câbles (coûts diminués), meilleures performances grâces à la réduction des domaines de diffusion, gestion simplifiée.
On peut faire communiquer des vlans entre eux par l'intermédiaire d'un routeur : il n'y a qu'un seul câble, branché sur une seule interface (f0/0) du routeur, mais cette interface est divisée en sous-interface (f0/0.1, f0/0.2, f0/0.3, etc.). A chacune de ces sous-interface est assigné un VLAN.
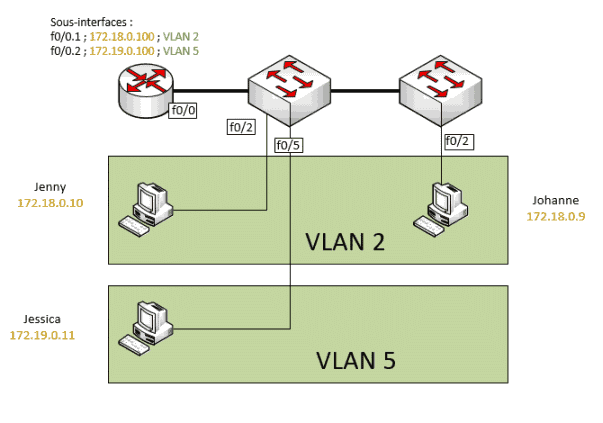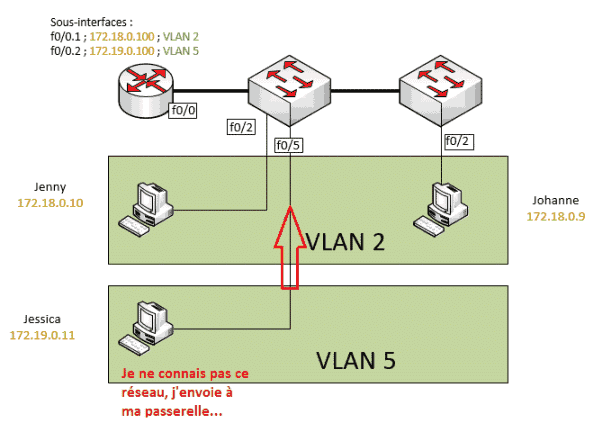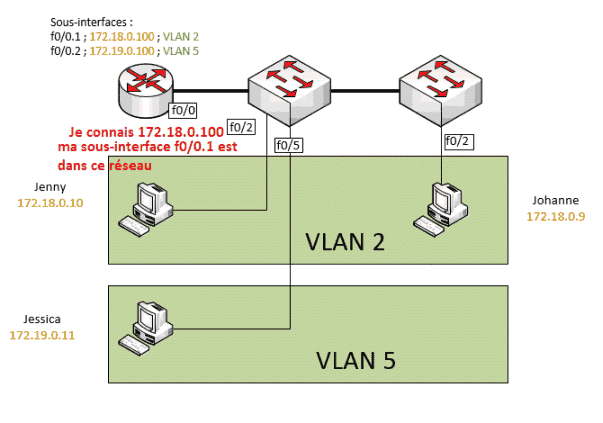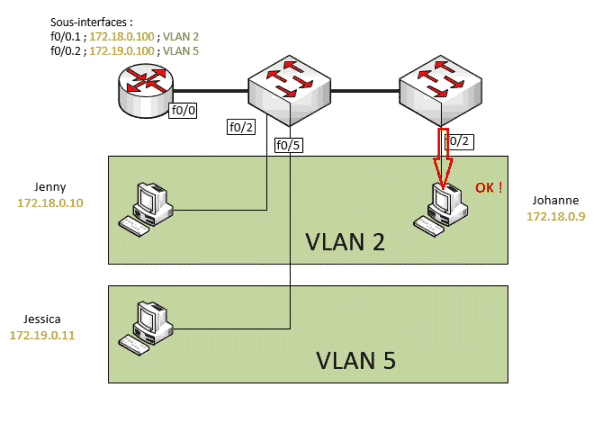
VLAN natif : Le VLAN natif est un VLAN qui n'est pas taggé, pour permettre à des équipements non-compatibles 802.1Q d'être entre deux équipements 802.1Q. C'est à dire que si une trame non taggée arrive sur un trunk, elle ira dans le VLAN natif. C'est souvent le VLAN1. Ne pas confondre "VLAN natif" et VLAN par défaut (qui est le n° du VLAN où sont regroupés tous les ports en cas de reset). Si une trame tagguée arrive sur le VLAN natif (erreur de configuration de la part d'un périphérique), elle sera abandonnée. Explication sur les forums de cisco Explication en français
Les VLAN 1002 à 1005 sont réservés pour Token Ring et fibre.
De 1006 à 4094 on parle de VLAN à plage étendue, qui sont traités différemment par les routeurs Cisco (pas sauvés dans flash:vlan.dat comme les autres, mais dans la running config, moins de fonctionnalités, pas pris en charge par le protocole cisco VTP (VLAN Trunking Protocol).
VLAN de gestion : configuré pour accéder à un commutateur par telnet, voir la section "créer une sous interface pour gérer un switch à distance".
Il existe des VLAN "statiques", créés sur un switch et très rarement des VLAN "dynamiques" configurés à l'aide d'un "VLAN Membership Policy Server" en fonction de l'adresse MAC d'un périphérique qu'on peut connecter sur n'importe quel switch sur lequel sera créé automatiquement le VLAN approprié.
Voir également le protocole EtherChannel qui réduit les risques d'interruption de routage entre 2 vlans.
Pour permettre par exemple à un routeur de faire communiquer plusieurs VLAN entre eux ("Router-on-a-stick "):
Les sous-interfaces d'une même interface ont la même adresse mac.
Pour démarrer :
-Enable.
-Configure terminal (ou "conf t").
Pour créer un vlan (pas obligatoire, il peut se créer quand on met quelque chose dedans), faire
Mettre l'interface fast ethernet 2 dans le vlan 2 :
On peut assigner plusieurs interfaces à la fois à un VLAN :
Pour mettre Fa0/12 en mode trunk :
Le trunk n'est pas obligé d'acheminer tous les vlan , il peut très bien acheminer les vlan 1 et 3 mais pas le 2. par défaut il les achemine tous,
Pour configurer le vlan 99 en mode natif :
Commandes pour vérifications :
En cas de panne, vérifier que les branchements sont bons, avec
Attention les VLAN sont sauvegardés parfois dans un fichier à part, VLAN.dat.
Pour supprimer un port d'un vlan faire
Si vous avez besoin de changer de réseau penser à utiliser
Dans l'interface à configurer,
Pour permettre à 2 ports de négocier automatiquement s'ils se mettent en mode trunk ou non.
Pour éviter d'avoir à modifier la configuration dans chaque switch quand on ajoute un VLAN. Un switch est défini comme le serveur VTP (mode par défaut sur routeurs cisco) qui transmet les infos sur la configuration, les autres comme clients.
Pour échanger des infos, ils doivent faire partie du même domaine VTP. Il peut également exister des switch dits "transparents" : ils laissent passer les paquets VTP mais ne sont pas influencés par eux (ont leur propre config de VLAN différentes des autres switchs du domaine).
Les clients stockent les infos sur les VLAN en mémoire vive (effacées hors tension), impossible de modifier les VLAN en se branchant sur eux directement (modification vient du serveur) par contre on peut modifier leurs ports pour les mettre en mode trunk ou accès. Les assignations de port dans les vlan ne sont pas transmis en VTP : sur le switch A le port 1 peut être dans le vlan 20 alors qu'il sera dans le vlan 30 sur le switch B.
Les infos VTP sont échangés via le trunk.
Lorsque les switchs ont une connexion redondante (plusieurs chemins pour aller d'un switch à l'autre), la transmission des trames VTP (ou "annonces VTP") ne se fait pas dans chaque chemin mais dans un seul, on parle "d'élagage VTP".
Les trames VTP sont envoyées en multicast à "01-00-0C-CC-CC-CC". Sont envoyés le nom du domaine, un MD5, le format de la trame (802.1Q ou ISL), nom du serveur, horodate, numéro de révision VTP (sort de "version" de la configuration VTP, incrémenté à chaque changement de config, pour qu'un switch client sache s'il a déjà reçu ces infos ou non -remis à zéro en cas de changement de noms de domaine VTP).
Au niveau VLAN, leurs noms, leurs ID, leur status, leur type et autres.
3 types d'annonces, tous les messages comprennent le numéro de version de la config :
-Annonce de résumée envoyée toutes les 5 minutes ou lors d'un changement de la config VTP.
-Annonce de type sous-ensemble comprenant toutes les infos sur les VLAN envoyée en cas de modif/changement de status de vlan.
-Requêtes, faites par les clients, lors de l'allumage du commutateur ou lorsque le commutateur reçoit un message d'annonce dont la révision est supérieure à ce qu'il connait ou que le nom VTP a été changé.
Il faudrait toujours avoir au moins 2 serveurs VTP, au cas où l'un d'eux tombe en panne (sans aucun serveur on ne pourrait plus configurer le domaine). Il faudra configurer les 2 serveurs de la même façon. Les serveurs ne se marchent pas sur les pieds car c'est celui qui envoie la plus haute révision qui sera prioritaire.
Avant d'installer un nouveau client qui viendrait d'un ancien réseau, il faut réinitialiser sa configuration VTP (par exemple en changeant temporairement de domaine
Pour configurer un serveur VTP :
On regarde comment il est configuré avec
Pour configurer un client VTP :
On regarde comment il est configuré avec
Les appareils cisco utilisent le fichier "running-config" pour travailler. Si on modifie ce fichier, on modifie le routeur en temps réel.
Le fichier "startup-config" (qui est stocké dans la nvram) est chargé au démarrage, il est copié dans "running-config" (dans la RAM).
Si on change la configuration d 'un routeur, puis qu'on le redémarre, toutes nos modifications seront effacées.
Pour sauvegarder "running-config", il faut donc copier le fichier running-config dans le fichier startup-config, avec la commande : "Copy run start".
On peut programmer un redémarrage du routeur dans les 15 minutes alors qu'on travaille sur startup-config pour que si on est ejecté du routeur, le startup-config nous autorise à y revenir au bout de 15 min avec la commande
L'IOS (système d'exploitation des appareils Cisco, "Internetwork Operating System") est stocké dans la flash, en général copié dans la ram au démarrage ("system:"). Il peut également être cherché à l'extérieur, en tftp avec la commande
Outre les mémoires RAM, NVRAM et Flash, il existe également la mémoire ROM (qui contient le programme d'amorçage, des outils de diagnostique et une version allégée de IOS).
On peut utiliser un server tftp pour exporter/importer le fichier startup-config. Peut être utile pour modifier la configuration plus facilement avec le bloc note (par exemple, si on peut rajouter une ligne dans une ACL).
Sur PC, lancer Solar Wind TFTP server. Vérifier qu'il est lancé, que son ip est bonne.
Pour exporter : depuis le routeur, taper "copy nvram:startup-config tftp", pour copier le fichier startup-config sur le serveur tftp.
Pour importer, c'est l'inverse : "copy tftp nvram:startup-config".
Le fichier startup-config remplacera, comme toujours, le fichier running-config au démarrage.
Certains routeurs peuvent chercher eux même un fichier de configuration sur le réseau, en TFTP, à condition de donner un nom spécifique au fichier Voir le site de cisco.
Si on utilise un client comme Putty, on peut aussi simplement copier le résultat d'un
Retirer le cordon d'alim, relier le port console du switch (prise ethernet spéciale) au port console du pc (port COM). Démarrer une session avec Putty. Laisser appuyer le bouton mode pendant qu'on branche l'alimentation du switch. "flash_init" pour pouvoir modifier la mémoire flash. "load_helper". "dir flash:" pour voir les fichiers dans la mémoire flash. On va renommer le fichier de configuration : "rename flash:config.text flash:config.old". Il contient également les définitions de mot de passe. "boot" pour lancer le switch.
Procédure chez cisco
Au démarrage du routeur, en étant sous Putty, appuyer sur la touche "pause" pour entrer en mode ROMmon, c'est à dire avoir accès à une version basique du système d'exploitation Cisco IOS stocké dans la mémoire morte (ROM). A l'invite "rommon 1>", taper
Pour éviter de démarrer tout le temps en mode ROMmon par la suite, faire
On efface le fichier startup-config, présent en nvram, qui est copié dans le fichier running-config à chaque démarrage avec
On peut aussi effacer la nvram :
La plupart des commandes peuvent être annulées ou inversées en rajoutant
Donner un nom au routeur :
Passer en mode configuration :
Passer en mode privilégié :
Mettre un mot de passe pour le mode privilégié : en mode configuration,
Mettre un mot de passe pour connexion console :
Chiffrer les mots de passe déjà stockés en clair dans le routeur (pour éviter qu'ils soient visibles via
Supprimer un fichier de la mémoire flash :
Désactiver une interface :
Activer une interface :
Donner une description (à une interface, par exemple) :
Passerelle à un switch (pour savoir sur quel port envoyer par défaut) :
Pour donner une passerelle à un routeur, utiliser :
Afficher l'heure :
Afficher la version d'IOS, de l'amorce, la RAM, la NVRAM et la flash disponible, l'état du flag confreg (entre parenthèse indique l'état où il sera au redémarrage), les interfaces, le modèle de la machine :
Se connecter avec telnet :
Afficher les informations sur une route :
Affiche / modifie la taille de / supprime l'historique des commandes (en mode "line console 0" ou "line vty 0 4" :
Pour s'adapter automatiquement à un cable droit ou croisé :
Activer l'authentification sur le serveur http :
Activer le serveur http :
Afficher un message lors de l'allumage du routeur :
Redémarrer :
Désactive le telnet, force le ssh :
Réactiver telnet sur un routeur (car se désactive automatiquement si SSH activé) :
Pour n'accepter les paquets DHCP que sur un seul port :
Pour n'accepter les paquets DHCP que sur un seul VLAN :
Ajouter manuellement une adresse mac à un port :
N'autoriser que 2 adresses mac sur un port :
N'autoriser qu'une adresse mac sur un port (config-if) : (
Enregistrer dans la listes des adresses autorisées les adresses déjà présentes et futures de la table mac (mode sticky)(config-if) :
Ajouter une adresse quand la machine est en mode sticky (config-if) :
Voir la configuration de sécurité d'un port :
Voir les macs autorisées :
Configurer plusieurs interfaces à la fois :
Il faut un mot de passe pour pouvoir utiliser telnet.
Il faut donner un nom et un domaine au routeur :
Puis, effacer les éventuelles clefs générées
Créer un utilisateur :
Puis activer SSH :
Pour voir si le ssh est activé :
Pour connaitre les ip de la machine,
Status "up" indique que l'interface fonctionne à la couche 1 (après un
Ajouter une route vers 192.168.0.1 en passant par 10.0.0.1 :
Pour faire un ping
Par défaut, les messages de debug ne s'affichent pas en telnet. Il faut les activer avec "terminal monitoring" (ou "terminal monitor").
Pour ne plus avoir "Translating "xxx"...domain server (255.255.255.255)", utiliser la commande
Pour ne plus être perturbé par les messages de debug alors qu'on saisie des commandes :
On peut aussi utiliser "ctrl+r" pour réafficher la ligne qu'on était en train de taper.
Pour interrompre un ping d'un routeur cisco : "ctrl+maj+6" (ou "ctrl+maj+9").
Pour voir les changements dans les tables de routage :
En ligne de commande :
netsh wlan set hostednetwork mode =allow ssid="nompointaccess" key="motdepasse"
Puis pour le lancer, ce qui devrait créer une nouvelle connexion réseau :
netsh wlan start hostednetwork
Pour voir qui est connecté :
netsh wlan show hostednetwork
Pour partager, clic droit sur la connexion qui va sur internet, propriété, onglet partage, autoriser d'autres connexions à passer par celle-là. Décocher la case dessous.
L'ip de la connexion wifi va changer (ex : 192.168.137.1). Plus qu'à connecter l'appareil au point d'accès et lui mettre une ip dans le même réseau.
Mettre à 1 la clef IPEnableRouter dans "HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters".
Pour connecter GNS3 dessus, par exemple.
Gestionnaire de périphérique, ajouter un périphérique, suivant, manuellement, carte réseau, carte de bouclage Microsoft. Puis, partager la connexion internet en utilisant cette carte de bouclage. Une IP privé lui sera attribuée (192.168.20.1 par exemple), l est désormais possible de se connecter à cette ip privée pour aller sur internet.
Pour qu'on puisse se connecter sur f0/0 et avoir internet, il faut activer le nat :
La ligne "ip nat inside.." permet de contacter une machine derrière le nat. Par exemple, pour contacter depuis l'adresse publique 92.89.166.97 la machine 10.0.0.1 qui héberge un site internet, faire :
Si un PC avec ip privée 10.0.0.1 est branché sur un routeur se connectant à internet, le PC ne pourra pas avoir accès à internet : il pourra faire un ping vers 8.8.8.8 mais 8.8.8.8 ne saura pas comment revenir à l'adresse 10.0.0.1.
PC A[(eth0)10.0.0.1]----[10.0.0.2(f0/0)]Routeur[(f0/1)92.65.2.1]----internet
Il faut donc mettre en place du NAT. Le plus simple est la traduction statique :
On peut faire aussi une "traduction dynamique simple" ou encore une "traduction dynamique overload".
A[192.168.19.3] ---- [192.168.19.4]B[10.0.0.1] ---- [10.0.0.2]C
Windows est sur A, B est un routeur, C est un linux.
On doit configurer une stratégie de sécurité ip dans
Clic droit⇒propriétés, ajouter, nouvelle règle. "Cette règle ne spécifie aucun tunnel", toutes les connexions réseaux, ajouter un filtre ip. Ajouter un filtre ip, cocher "miroir" pour qu'il s'applique dans les 2 sens. Indiquer les ip des machines à relier avec Ipsec.
Créer un nouveau filtre, personnalisé. Par défaut pour OpenSWAN, algorithme d'intégrité MD5, algorithme de chiffrement 3DES. Penser à cocher utiliser la session de clef principale. L'assistant devrait demander d'entrer la clef partagée (ou le certificat). Clic droit sur la stratégie, puis "attribuer".
Lancer ip sec sous linux :
Si la communication est crypté, en faisant un ping, on ne devrait plus voir passer des paquets ICMP mais des paquets ESP .
Ou "tunneling". Encapsulation, souvent chiffrée (on peut encapsuler de l'ip dans l'ip ou utiliser openVPN sans chiffrer mais c'est peu utilisé), des paquets entre 2 machines dans le but d'établir une "connexion locale" virtuelle entre 2 machines non-directement connectées. On pourra avoir 2 machines distantes sur internet qui communiquent avec des ip privées.
Un VPN permet de connecter 2 sites de façon sécurisée et indépendante des protocoles.
Exemples : une compagnie qui veut connecter deux lieux de travail, dans 2 villes différentes ; une entreprise qui se connecte à un datacenter via VPN.
Dans windows, centre réseau et partage, configurer une nouvelle connexion VPN.
Les 2 côtés du VPN [url=https://technet.microsoft.com/en-us/library/cc984423.aspx]doivent connaitre la "pre-shared key"[/url], (essentiellement, c'est un mot de passe pour se connecter au VPN).
Pour traverser un NAT, ça peut être encapsulé sur UDP.
On peut faire un VPN de site à site ou un VPN multi-sites (qui permet plusieurs connexions à un seul virtuel). Au lieu d'avoir le bureau principal qui se connecte aux data center et les bureaux secondaires qui se connectent au bureau principal, chaque bureau secondaire+le principal se connectent directement au data center.
D'après le TP chez cath.milard.free.fr
Autre tutorial
Permet d'établir un réseau privé virtuel entre 2 machines, fonctionne en architecture client/serveur, doit être installé aux deux extrémités, peut être non-chiffré ou chiffré avec clefs asymétriques ou symétriques.
Par exemple, selon le schéma suivant :
A[10.1.0.1] ---- [10.1.0.2]B[10.2.0.2] ---- [10.2.0.1]C
Tunnel :
A[172.16.0.2] --- [172.16.0.1]C
On ajoute le groupe "openvpn"
Pour lancer Open VPN :
On peut aussi forcer open vpn à se lancer en forçant un fichier de config :
Pour tester, voir si l'interface est apparue (ifconfig), faire un ping sur l'interface virtuelle (172.16.0.1).
Pour voir le log :
Du côté du client, dans un fichier à créer nommé "C:Program Files\OpenVPN\config\client.ovpn" :
Lancer OpenVPN GUI en tant qu'administrateur, clic droit sur l'icône dans la barre des tâches, "connect". Une nouvelle interface devrait apparaitre avec l'ip en 172.
Sur le serveur linux se trouvent des scripts pour gérer les certificats, dans le dossier "/usr/share/doc/openvpn/examples/easy-rsa/2.0/". Copier le contenu de ce dossier à un autre endroit.
1. Lancer le script "vars" (avec
2. Lancer "clean-all" pour créer un sous-dossier "keys" vide.
3. Lancer "build-ca" pour créer une clef privée et son certificat.
4. "build-key-server nom_du_serveur"
5. "build-key nom_du_client"
6. "build-dh" pour créer une clef partagée entre les 2.
Vous devriez avoir dans le dossier "keys" : "ca.crt", "ca.key", "nom_du_serveur.crt", "nom_du_serveur.key", "dh1024.pem", "nom_du_client.crt", "nom_du_client.key".
Dans le dossier /etc/openvpn, copier ca.crt, ca.key,nom_du_serveur.crt, nom_du_serveur.key et dh1024.pem.
Sur le client, dans c:program filesopenvpnconfig, copier ca.crt, "nom_du_client.crt", "nom_du_client.key".
Dans le fichier de configuration d'openvpn, rajouter :
Dans le fichier de configuration windows, ajouter :
Il faut ajouter la ligne
Le serveur OpenVPN peut envoyer les routes de son réseau privé à une machine qui se connecte vers le réseau public, par exemple :
Réseau privé [192.168.1.1]---[192.168.1.2]OpenVPN[10.0.0.1]---[10.0.0.2]Client VPN
Du côté du serveur, ajouter
Dans chaque ICMP il y a un champ "ID" qui identifie le paquet. Le routeur mémorise le numéro, change l'ip source, envoie lef paquet paquet. Quand il revient, il le renverra à la machine qui l'a envoyé.
http://linuxfr.org/users/edouard/journaux/nat-et-icmp
http://www.cisco.com/c/en/us/support/docs/ip/network-address-translation-nat/13771-10.html
http://superuser.com/questions/135094/how-does-a-nat-server-forward-ping-icmp-echo-reply-packets-to-users
http://tools.ietf.org/html/rfc3022
L'ADSL est Asymétrique : upload et download pas identique.
Entre 512 et 20 megabits en download, 1 mega en upload diviser par 8 pour avoir le débit en octet.
Multiplexage fréquentiel : plusieurs signaux sur un même support à des fréquences différentes. C'est ce qui se passe aussi avec la radio et la télé. Tous les signaux sur le même support passent sans se perturber l'un l'autre. De 300 à 3400 hertz pour la voix. La partie transmission de données va être transférée entre 130khz et 1Mhz, donc beaucoup plus.
Boucle locale : liaison téléphonique, ce qui relie l'abonné, avec une paire torsadée sur les poteaux, avec le DSLAM qui se trouve dans un rayon de 5 km de l'abonné. Le DSLAM se connecte au BAS (Broadband Access Server, qui fait l'authentification).
ATM : protocole destiné à transférer ce qu'on veut, des données, de la voix, de la vidéo, etc. Permet d'établir des circuit virtuels, c'est à dire qu'on aura un circuit commuté, mais virtuel, le chemin peut changer. Il enregistre le fait que les 2 extrémités sont connectées et simule un circuit. C'est le coeur de réseau de France Télécom. Certaines entreprises pourraient fonctionner en interne avec ATM. 3 couches ATM : physique (2 sous-couches, Tranmission Convergence pour contrôle des données/adaptation des débits/délimitation des cellules et Physical Medium pour l'accès au support physique et les mécanismes de synchronisation), ATM (multiplexage, génération/extraction des en-têtes, acheminement des cellules) et AAL (qui peut servir à simuler de l'Ethernet, divisé en 2 sous-couches, Segmentation And Reasembly Sublayer pour ségmenter/réassembler les cellules pour les couches supérieures et Convergenge Sublayer pour la synchronisation de l'horloge). Plus d'infos sur le site de l'université de Toulouse Plein d'infos sur le wiki de cisco
Modem à l'origine c'était transformation de signaux numérique en analogique, maintenant on appelle toujours ça pas abus de langage un modem mais il s'agit d'un boitier ATM.
On peut se connecter de 2 façons :
PC[adresse privée]-----[adresse privée]box[adresse publique]-----internet
PC[adresse publique]----adaptateur-----internet
PPP : Point-to-Point Protocol, s'utilise avec le protocole chap ou pap qui utilise mot d'utilisateur et mot de passe, pour une connexion entre 2 hôtes. Pour se connecter sur le réseau mondial. Au début prévu pour mettre sur des liaisons de niveau 2 de réseau WAN (les protocoles HDLC, PPP, SDLC, LAPD sont des exemples de protocoles de niveau 2, maintenant on a quasiment plus que de l'éthernet). Etant un protocole point à point, l'adressage au niveau de la couche 2 est facultatif (une seule destination possible).
PPPoA (PPP over ATM) ou PPPoE (PPP over ethernet) : on établit la connexion directe avec le BAS. PPP est un protocole de niveau 2 donc il peut transporter de l'ip (comme ethernet), mais il peut être transporté sur une autre couche : on peut avoir de l'ethernet qui contient de l'ip qui contient du PPP qui contient de l'ip (à cause des multiples étapes avant d'arriver sur internet).
L2TP est un protocole permettant de transporter un autre protocole de niveau 2 de façon chiffrée.
CHAP (challenge handshake authentification protocol) : CHAP va vérifier plusieurs fois en cours de route l'identité des communiquants. Serveur envoie un mot de passe au hasard que le client va chiffrer avec son mot de passe et le renvoyer.
PAP est un plus vieux protocole, plus simple (pas de vérification une fois la communication établie, mot de passe pas crypté....). Certains équipements ne permettaient pas le CHAP donc les FAI ouvrent PAP et CHAP.
Le problème est la taille du MTU, puisqu'on rajoute PPP à ethernet, ça peut ne plus marcher. A niveau de la machin client on peut aller dans le registrre et réduire la taille des paquets. La deuxième solution est au niveau du routeur, pour réduire la taille du MTU (fragmentation). Ca pose les mêmes problèmes en VPN, sur open VPN on peut choisir la taille du MTU. On choisis 1462 au lieu de 1500 pour ne plus avoir ce problème.
On parle d'équipement terminal de circuit de données (ETCD, "DCE" en anglais) pour le périphérique qui se connecte sur le réseau étendu (à un autre ETCD). Il fait une conversion du signal et doit faire office d'horloge pour un autre périphérique, l'équipement terminal de traitement de données (ETTD, "DTE" en anglais). Par exemple, une carte ADSL sera ETCD, le routeur (qui héberge la carte) sera ETTD, ou bien un modem sera ETCD et un PC ETTD. Lorsqu'on connecte 2 routeur ensemble avec un câble série (câble V.35), l'un devient DTE et l'autre DCE. On peut changer les rôles et la fréquence de l'horloge (
http://www.securite-informatique.gouv.fr/
Cours et exercices sur la sécurité informatique
http://xenod.free.fr/index.htm
Guide gouvernemental d'intégration de la sécurité des systèmes d'information dans les projets
http://guide-wifi.blogspot.fr/
1. Généralités
2. Sécurité
3. Types de réseaux
4. Protocoles
5. Modèles
- Couches OSI
- Couches TCP/IP
- TCP et UDP
- Protocole UDP
- Modèle de réseau hiérarchique
6. IPV4
- Adresse réseau
- Adresses réservées
- Adresses publiques
- ICMP
7. IPv6
8. Couche 2 du modèle OSI
- Trame Ethernet
9. Couche 1 du modèle OSI
10. Materiel réseau
- Hub
- Pont
- Switch
- STP (Spanning Tree Protocol)
- Routeur
11. D'un réseau à un autre
- RIP
- OSPF
- Routage Cisco
12. DHCP
- Serveur DHCP (Cisco)
- Relais DHCP (Cisco)
13. Access list
- Vlan
- Sauvegarde des modifications (Cisco)
- Exporter/importer la configuration (Cisco)
- Reset switch Cisco
- Reset routeur cisco
- Commandes diverses(Cisco)
- Windows
14. Configurer connexion ADSL cisco
- NAT avec routeur Cisco
- Faire fonctionner windows 7 avec OpenSWAN
15. VPN
- Open VPN
- Comment ICMP traverse un NAT ?
- DSL
16. Liens intéressants
Généralités
Les quatre éléments d'un réseau de données :
| Support (câbles ou ondes). | ⇒ | Le codage du signal est différent selon le support : impulsions électriques sur du metal, impulsions de lumières, ondes... Différents avantages et inconvénients : coût, distance de transport des données (100m pour un cable ethernet "cables à paires torsadées"), sécurité... |
| Protocoles | ⇒ | Les "règles", "langages" utilisés. Il y a différents niveau de protocoles qui s'emboitent entre eux. Par exemple, on peut avoir un protocole pour que 2 machines se reconnaissent (Ethernet) + un protocole qui demandera un accusé de réception (TCP) + un protocole affichant une page web (HTTP). Pour que 2 ordinateurs discutent via des protocoles, on peut utiliser du matériel physique (carte ethernet) ou des programmes. Par exemple, un service FTP installé sur une machine permettra à un autre machine de s'y connecter pour envoyer des fichiers, en respectant les "règles FTP" (le protocole FTP). Ce protocole FTP pourra être acheminé par le protocole Ethernet qui définit la manière dont le matériel physique communique. |
| Périphériques | ⇒ | Routeurs, pc, téléphones, imprimantes... Il envoie les signaux numériques sur les supports. Un hôte (host) est un "périphérique final" : soit la machine source du message, soit la machine de destination. Un hôte peut être serveur (machine équipée d'un programme -service- qui envoie des infos, par exemple page web), soit client (demande une page web au serveur et va l'afficher), soit les deux. On parle aussi de DCE (Data circuit-terminating equipment, transmet les données- modem) et de DTE (Data Terminal Equipment -périphérique final). On parle aussi de "noeud" pour les périphériques. |
| Messages | ⇒ | Echange d'information tel que lecture de mail, de page web, envoi de message instantané...). Un message est formaté selon les règles puis converti en signaux numériques par les périphériques réseaux. Sans messages, le réseau serait inutile . |
Réseau convergent :
Autrefois, on avait plusieurs réseaux différents pour la téléphonie, la télévision et internet. Ce n'était pas les mêmes câbles, pas les mêmes protocoles. Un réseau convergent permet d'utiliser un seul réseau au lieu de trois. Baisse les coûts de déploiement et de maintenance.
Réseau à commutation de circuits :
Pour établir une communication entre deux machines, il existe de nombreux chemins possibles, mais un seul est sélectionné durant toute la durée de l'appel. Si le chemin est coupé, la communication est interrompue.
Réseaux à commutation de paquets :
Les messages sont découpés en petits paquets, qui peuvent chacun parcourir un chemin différent pour arriver à destination. Meilleure tolérance aux pannes.
QoS :
La QoS (Quality of Service, Qualité de service), permet de rendre certain types de communication prioritaires par rapport à d'autre. Par exemple, sur un réseau où on trouve à la fois de la téléphonie, de la tv et du web, on pourrait vouloir rendre la téléphonie ou la TV prioritaire par rapport au web. Le routeur transmettra d'avantage de paquets TV que de paquets web (les pages web s'afficheront avec un peu de retard mais l'image de la TV sera meilleure).
Plusieurs niveaux ("tier" en anglais) pour les FAI (fournisseurs d'accès à internet) :
- Niveau 1 (tier 1) : assurent les connexions nationales et internationales. Se connectent avec les autres FAI de niveau 1 gratuitement, car ils ont autant besoin d'accéder à leur réseau qu'eux aux leurs. Parfois, des FAI de niveau 1 ne se considèrent plus comme égaux et l'un demande une compensation financière à un autre. Exemple, Cogent et Telia ont rompu leurs connexions, obligeant les paquets à emprunter une autre route (source 1, source 2). Retenir que les niveau 1 peuvent se connecter à tous les réseaux d'internet sans devoir payer. Coût très élevé si une entreprise veut se brancher directement sur eux, mais pas de goulot d'étrangelement car accès direct donc connexion plus rapide et plus fiable.
- Niveau 2 (tier 2) : payent certains FAI de niveau 1 pour avoir accès au réseau (orange).
- Niveau 3 (tier 3) : payent des FAI de niveau 2 (wifirst).
Ont un impact sur la qualité du réseau : l'envoi d'un accusé de réception, la qualité de la ligne, le nombre de fois où le message doit changer de forme, le nombre d'autres communications sur le réseau, temps alloué.
Multiplexage :
On parle de multiplexage lorsqu'on transmet plusieurs signaux indépendants sur un même support de transmission. Exemple, une ligne téléphonique en Y, les deux extrémités hautes vont chacun chez un client puis se rejoignent sur un seul fil. Plusieurs communications téléphoniques sur un seul fil. Egalement appelé "AMRF Accès Multiple par Répartition de Fréquences" ou "FDM : Frequency Division Multiplexing". Impossible de mettre l'ADSL sur un câble téléphone qui utilise du multiplexage car les fréquences utilisées par l'ADSL sont utilisées par d'autres abonnées. Dans une ligne ADSL, 4 Khz pourront être utilisées par la voix et 1 Mhz par les données. Plus d'infos(( An analog signal's infinite number of variations makes it impossible to reproduce exactly. An analog signal will go only so far in copper wire; to go further the signal must be regenerated electronically with a device called a repeater. The repeater converts the weak input signal to a stronger output signal, unavoidably distorting it in the process. Each regeneration degrades the signal a bit more (in the same way that photocopies of photocopies get worse at each iteration). In a large telephone network, the "copy of a copy" problem becomes very expensive to solve, requiring sophisticated equipment and costly cabling.
Digital signals, on the other hand, are easy to regenerate precisely. Because there are only two possible states for the signal, even a heavily degraded signal can be regenerated into an exact copy of the original. What's more, the cost (and complexity) of equipment to regenerate digital signals is trivial compared with that for analog. Not surprisingly, telephone companies recognized this cost advantage a long time ago and have since converted all long distance transmission to digital signaling. When a subscriber makes a long-distance call, the central office (CO) converts the analog signal to digital using a technique called sampling (see "Analog-to-Digital Conversion Diagram"), in which the state of the analog signal is captured about 8,000 times per second. Each state is converted to an 8-bit binary number, and the resulting string of binary numbers becomes a digital data stream at 64 Kbps. This digital stream is routed along the long-distance network, being regenerated as needed. Each regeneration produces an exact copy of the original digital data stream, so no information is lost. When the destination CO receives the digital data stream, it reverses the sampling process and transmits the resulting analog signal to the receiving subscriber. (On a side note, many local telephone companies are converting to digital switching, even for local calls).))
Ne pas confondre avec le multiplexage sur la couche transport de tcp/ip (divisions en ports 80, 21, etc).
Segmentation :
Les communications sont découpées en petits paquets. Les paquets sont tous envoyés sur la même ligne. Pas de limite de communication simultanées, contrairement au multiplexage qui nécessite une fréquence libre pour chaque communication.
RNIS :
Reseau numérique à intégration de servis ("numeris" chez France Telecom). Plusieurs canaux logiques dans une même ligne. Numérique d'un bout à l'autre, pas de transformation analogique : en transformant la voix en signal numérique, le signal est facilement régénéré. On dit que c'est une technologie à large bande car elle utilise plusieurs canaux. Numeris est un réseau à commutation de circuits (contrairement à ADSL). On paye durant tout le temps que la communication est établie. Bon site sur ISDN
Sécurité
La sécurité s'occupe de 3 points :
* Assurer la confidentialité des données. Système d'authentification des utilisateurs pour s'assurer qu'il va à la bonne personne, chiffrement des données pour que n'importe qui ne puisse pas les lire.
* Garantir l'intégrité des données, c'est à dire que les données ne doivent pas avoir été modifiée entre l'envoi et la réception, ou ce qui a été enregistré ne doit pas avoir été modifié une fois sur le support.
* Assurer la disponibilité. Lutter contre les attaques de type DoS (deny of service), les sabotages, etc. Mettre en place des sauvegardes. Délai suffisant de disponibilité (pas le même délai acceptable pour téléphonie et web). Pour gérer ça, mise en place d'enregistrement du trafic pour prévoir un risque.
On peut ajouter "authentification" (être sûr que la personne à qui on parle est celle que l'on veut) et "non-répudiation".
Répudiation : pouvoir nié avoir pris part à une transaction. La sécurité informatique peut avoir besoin de mettre en place un système de "non-répudiation" par exemple lorsqu'on met en place un système de signature électronique.
Utiliser des sites généralistes comme [http://web.nvd.nist.gov/view/vuln/search|nist.gov] ou les sites des constructeurs/développeurs pour repérer les dernières failles.
Types de menaces :
-Naturelles 26%. 13% pour incendie, explosion, dégâts des eaux, pollution, catastrophe naturelle 2% pour arrêt de service électricité ou télécom. 11% de pannes systèmes : panne informatique, panne réseaux internes, saturation des réseaux.
-Humaines 74% :17% pour erreurs humaines (8% conception, 9% exploitation). 57% pour la malveillance. 2% pour vol, sabotage. 18% pour fraude. 12% pour intrusion, virus. 14% copie de logiciel, 10% vol de ressource, 1% démission, grève, absence.
Origine des menaces :
Menaces la plupart du temps interne.
-Divulgation de la part d'employés autorisés : 54 %
-Employés non-autorisés : 22 %
-Anciens employés : 11%
-Pirates : 10%
-Concurrence 3%
Attaques physiques :
-Interception de signaux électromagnétiques (cf la norme TEMPEST, Telecommunications Electronic Material Protected from Emanating Spurious Transmissions).
-Brouillage.
-Ecoute.
-Piégeage.
-Micros et caméras espions.
Attaques physiques :
-Social Engineering (faire révéler des infos à quelqu'un en se faisant passer pour quelqu'un d'autre), le plus utilisé. "Bonjour, c'est XXX de Tour, on s'est vu à la réunion tu te rappelles ? Je suis embêté ya plus personne dans le bâtiment et j'ai oublié le mot de passe de...".
-Fouille des dossiers.
-Attaque sur les mots de passes.
-Backdoor (créé par le concepteur du logiciel ou la maintenance).
-Déni de service.
-Virus, ver, cheval de Troie.
Attaques sur les mots de passe :
-Dérober un mot de passe (Social Engineering, vol).
-Deviner un mot de passe (question secrète, date de naissance, noms des proches, mots courants, sportif, voiture, vedette, lieu, injure...).
-Renifler un mot de passe (le prendre alors qu'il transit).
-Cracker un mot de passe (brute force, dictionnaire...).
Le piratage téléphonique - Phreaking, pour utiliser une autre ligne que la sienne, ou pour pirater un modem derrière les pare-feus.
Virus : se cache dans un .exe, .doc, .xls... Peut se recopier seul.
Si le lanceur a été écrit pour se mettre à un endroit particulier d'un code, une mise à jour d'un logiciel, même si elle ne s'attaque pas directement à une faille, permet de perturber le fonctionnement du virus. Le virus ne peut plus s'intégrer au code comme prévu.
Ver : ne se joint pas à un programme, se reproduit seul, utilise en général des failles.
Bombe logique : fonction ajouté à un programme qui se déclenche à un moment donné.
Cheval de troie : un logiciel en apparence bienveillant qui cache un virus.
IP spamming : innonder de message un serveur.
IP sniffing : écouter le trafic réseau.
Ip Spoofing : voler une adresse ip.
Source Routing : forcer à utiliser une route plutôt qu'une autre.
Attaque par fragmentation (teardrop) : envoyer des paquets volontairement impossibles à remettre dans le bon ordre pour bloquer l'appareil (dépassé).
Man in the Middle : A communique avec C en croyant qu'il s'agit de B, B communique avec C en croyant qu'il s'agit de A. C voit toutes les informations passer, A et B pensent communiquer directement.
Pour définir une politique de sécurité, il y a plusieurs entités à prendre en compte :
-L'organisation, définir les responsabilités, les procédures.
-Le personnel, définir les droits, sensibiliser les chefs/techniciens/utilisateurs, former.
-La zone physique, définir un contrôle d'accès, penser au ménage, à l'environnement (inondation, incendie, etc).
-Le matériel, définir une méthode de gestion du parc, protéger contre le vol, penser à la maintenance, l'homologation...
-Le logiciel, contrôle d'accès, imputabilité ("non-répudiation"), audit (qui a accédé à quoi), développement, maintenance, archivage.
-Le support, gestion des enregistrements sur support physique, de la destruction, reproduction, conservation, marquage...
En priorité, la sécurité physique (quelqu'un qui a accès physiquement à une machine peut très facilement la craquer), les sauvegardes. Ensuite, les mots de passes, les comptes, les bases de définition des virus. Pas de bidouilles sur système en production.
Surtout : sécuriser les personnes et les sauvegardes.
Authentification par ce qu'on sait (mot de passe), ce qu'on détient (jeton), ce qu'on est (biométrique)
Il ne faut pas que la sécurité soit trop forte ou les utilisateurs passeront au travers. Si on met trop de chose ce n'est plus maintenable. Il y a un équilibre à trouver entre facilité d'utilisation et sécurité. Autre problème, les hackers vont vérifier si une machine est particulièrement protégée, signe qu'elle protège quelque chose.
SOCKS (Socket Secure) : Protocole qui route les paquets entre client et serveur à travers un proxy. Au niveau 5 de la couche OSI (session). SOCKS ne sert pas uniquement pour le HTTP mais pour n'importe quel service, écoutent en général sur le port 1080.
Zone démilitarisé : où on met les serveurs accessibles par le public.
Callback : pour éviter que quelqu'un se fasse passer pour nous (faux N° de tel envoyé), on appelle un téléphone ip, lui demande de nous rappeler.
ARP spooffing : Lorsqu'on fait une requête ARP, on demande l'adresse du routeur. Si quelqu'un répond avant, il peut se faire passer pour le routeur.
Attaque par fragmentation : on regarde les paquets fragmentés passer et on envoie des paquets qui disent faire partie de cette fragmentation.
Source routing : on change son ip source quand on envoie une demande au routeur.
Chiffrement : par exemple, on mélange les bits selon un algorithme et une clef, on peut déchiffrer avec une clef.
Clef symétrique : même clef pour chiffrer/déchiffrer.
Clef asymétrique : A et B génèrent chacun une paire de clef générée ensemble, une permet de crypter, l'autre de décrypter. Basé sur l'impossibilité de factoriser les nombres premiers de grandes dimensions. On envoie la clef qui permet de crypter à l'autre, il crypte, nous envoie le message, on décrypte. En envoyant sa clef publique, on accepte que des hackers puissent nous envoyer des messages (<-à vérifier, me semble que c'est la privée qui permet d'envoyer des messages).
SSL permet de faire appel à des organismes officiels auprès desquels les clefs publiques ont été diffusé. Si on va chez paypal, le navigateur va consulter un tier pour demander si la clef publique reçue correspond bien à une clef de type paypal.
Quand on fait un ping dans un VPN, le TTL du ping ne pas avoir décrémenté, car le paquet ping est chiffré, donc le routeur ne l'a pas décrémenté.
Attention : si on fait des choses trop complexes on fait des choses qu'on ne gère plus et on fait donc des failles de sécurité.
Pare feu
Matériel : difficile de désassembler le code (processeur spécial...), moins vulnérable aux virus qu'un pare-feu installé sur un linux...
Un parefeu doit être invisible pour un attaquant extérieur. Si on fait son parefeu avec un routeur, ou un linux avec iptable, il faut le cacher.
Même si l'un des avantages d'un pare-feu est de centraliser les règles de filtrage, on peut mettre plusieurs pare-feux, mieux vaut avoir de la redondance.
La priorité de la sécurité, c'est l'accès et les personnes : si un employé peut faire un point d'accès avec son téléphone le pare-feu ne sert à rien.
Dans un système "stateful", on peut n'ouvrir les ports que si il y a établissement d'une connexion TCP, pour éviter de les laisser tout le temps ouvert.
Avec ses analyses, le pare-feu peut réduire la bande passante.
Le pare-feu peut servir à faire de la répartition de débit. Il peut faire de la QOS pour réserver de la bande passante selon les personnes ou les entreprises.
Pare-feu bridge : fonctionne au niveau 2, pas avec l'ip. N'a pas d'adresse ip ni mac, donc invisible.
On peut tester sa sécurité avec NMAP, NPING2 ou NESSUS ou via des sites internet.
Schéma 1 :
Internet---routeur1----proxy----parefeu----routeur2----LAN de l'entreprise
.............[.....DMZ...........]........................................
Les ordinateurs du réseau lan de l'entreprise vont faire leur demande sur internet en passant par le proxy. Le proxy va faire les demandes à notre place. Les réponses iront au proxy. Le routeur 2 peut faire du NAT pour supprimer les adresses ip.
Si un ordinateur de l'entreprise est piraté (trojan), le proxy le rend difficile à contrôler.
Le pare-feu est un filtre, le proxy est un outil qui fait des demandes à la place de l'utilisateur.
Types de réseaux
Identifié selon : la zone qu'il dessert, la façon dont sont stockées les données, la manière dont sont gérées les ressources, son organisation, le type de périph, le moyen utilisé pour les connecter entre deux.
Réseau local (LAN : Local Area Network) : généralement une zone restreinte et un seul groupe d'administration. Peut contenir d'autres LAN.
WLAN : réseau local sans fil (wireless LAN), utilise les ondes radio (d'une dizaine de mètres de portée à plusieurs dizaine de kilomètres en Wimax). Les périphériques se connectent sans fil au points d'accès, qui sont eux mêmes connectés à internet via des câbles.
PAN : Réseau personnel (personal area network), souris, smartphone, tablettes connectées, généralement en Bluetooth (7 periph maximum, fréquence radio de 2.4 à 2.485ghz, technologie adaptative AFH pour réduire les interférences). Généralement symétrique, les appareil communiquent entre eux contrairement au wifi où c'est généralement client/serveur.
MAN : Réseau métropolitain (metropolitain area network), optimisé pour une zone géographique plus large que le LAN. Lignes appartiennent généralement à un consortium d'utilisateur ou à un FAI.
WAN : Réseau étendu (wide area network), relie ensemble des réseaux plus petits (interréseaux). Des entreprises privées peuvent aussi metrte en place leur WAN pour relier deux sites distants avec des lignes louées. Internet est un réseau WAN.
SAN : Réseau de stockage (Storage Area Network), utilisant par exemple ISCSI. Une unité de stockage SAN est désignée par un numéro LUN (Logical Unit Number). Dans un réseau SAN, on a accès au disque en mode block, comme s'il était directement connecté au PC, et pas en mode fichier (contrairement à un NAS).
Réseau P2P : Pas de serveur dédié ni de hierarchie entre les PC. Pas d'administration centralisée, pas de sécurité centralisée, plus il y a de PC, plus la complexité du réseau augmente. Pas forcément de sauvegarde centralisée.
Intranet : Réseau interne à une entreprise.
Extranet : accès limité au réseau intranet d'une entreprise via l'extérieur.
Protocoles
Un protocole est une règle de communication, une sorte de langage commun que 2 programmes utilisent pour communiquer. Lors d'une communication, il existe plusieurs programmes qui vont discuter entre eux. Par exemple, imaginons un navigateur qui veut consulter une page internet.
-Premier programme, le navigateur (Internet Explorer). Il sait demander une page internet à un serveur web 1.2.3.4 selon le protocole HTTP ("donne moi s'il te plait la page index.htm, si elle a été modifiée après le 10 juin 2014, je m'appelle internet explorer."
Mais pour que ce texte, ces données, arrivent jusqu'au service web du serveur, il faut qu'il voyage sur le réseau.
-Deuxième programme (ou plutôt, une "blibliothèque"), winsock, qui va découper les données en segments. Il va utiliser le protocole IP (pour envoyer le message vers 1.2.3.4.) ainsi que le protocole TCP pour demander un accusé de réception et préciser le port où écoute la machine (un "port" permet de filtrer ce que l'ordinateur reçoit -tel port est destiné à tel programme, cela lui permet d'éviter se se mélanger quand il reçoit, par exemple, à la fois une page web et un fichier).
-Troisième programme, le pilote de notre carte réseau, qui va utiliser le protocole Ethernet et transformer le tout en impulsions électriques. Le protocole ethernet permet à des machines de communiquer entre elles d'après leur adresse MAC. Si on disait que l'adresse IP serait le numéro de téléphone, l'adresse MAC serait le numéro de série du téléphone. Notre ordinateur ne connait pas toutes les adresses MAC de tous les PCs sur internet : il ne connait que les adresses macs des machines connectées à lui (commande "arp -a" pour les voir).
En résumé : 1)Ethernet pour communiquer avec la machine directement connectée à nous, 2)IP pour communiquer avec une machine plus loin, 3)TCP pour demander un accusé de réception et préciser un port, 4)HTTP pour demander telle page web.
On a ici 4 protocoles différents, "encapsulés" les uns dans les autres : dans un seul paquet, on aura "[ethernet[ip[tcp[données]]]]". On parle aussi de "couches".
Avoir des couches distinctes permet :
* une plus grande flexibilité. On peut très bien avoir du HTTP sur la première couche mais pas de l'Ethernet sur la dernière, ou bien autre chose que du http ou du TCP/IP mais toujours de l'ethernet.
* de concevoir des nouveaux protocoles plus facilement, qui s'encapsulent avec d'autres, ce qui encourage la concurrence.
* si un protocole devient obsolète, les protocoles des autres couches peuvent continuer à être utilisés.
Mis à part la couche 1 et 2, les protocoles sont en général définis par des organisations telles que l'IETF (Internet Engineering Task Force), par les constructeurs ou les créateurs de programmes. Les couches 1 et 2, très liées au matériel, voient leurs protocoles en grande partie définis par des organisation internationales de normalisation comme l'IEEE (Institue of Electrical and Electronics Engineering).
Modèles
Couches OSI
L'organisation internationale de normalisation (ISO) propose un standard pour les couches de protocoles, en proposant 7 parties. Néanmoins, beaucoup de protocoles ne collent pas vraiment à ces 7 parties (voir la Tentative de séparer de sprotocoles selon ces 7 couches).
Modèle OSI chez cisco, Modèle OSI chez webopedia.
| Nom de la couche | Explication |
|---|---|
| 7. Application | Les protocoles utilisés par les application, par exemple HTTP, FTP. |
| 6. Présentation | Formate les données. Protocoles de chiffrement, de compression, par exemple JPEG, ASCII, MPEG. |
| 5. Session | Gère les connexions entre applications, ouvertures/fermetures de sessions, etc. |
| 4. Transport | Garantit l'intégrité des données, filtre les données qui arrive grâce aux ports, par exemple TCP ou UDP |
| 3. Réseau | Défini l'adresse d'une machine dans un réseau distant. IP. |
| 2. Liaison | Divisé en MAC et LLC. Exemple IEEE 802.3 (ethernet), Token ring. Prépare les données pour le support physique. |
| 1. Physique | Les supports. Signaux électriques ou lumineux. Niveau des voltages, taille maximum des câbles, types de connecteurs etc. |
Première sous-couche de la couche liaison ⇒ LLC (Logical link control) : Des mécanismes de multiplexage, par exemple en utilisant le champ VLAN (si on utilise la norme 802.1Q) ou bien le champ "type" d'une trame ethernet (qui indique quel protocole est en train d'être transporté, par exemple IP ou ARP). Inclus aussi les acquittement et le contrôle d'erreur (4 octets à la fin d'une trame ethernet).
Seconde sous-couche de la couche liaison ⇒ MAC (media access control) : Accès au support, adresses physique des machines.
Un navigateur web comme Internet Explorer intègre les couches 5, 6 et 7.
Protocol Data Unit : On appelle PDU le fragment d'une donnée. Par exemple, le PDU de la couche 1 est le bit (la donnée a été découpée en bits). Le PDU de la couche 2 est appelé une trame. Le PDU de la couche 3 est appelé un paquet. Le PDU de la couche 4 est appelé un segment pour TCP et un datagramme pour UDP. Plus d'info sur wikipedia
Moyen mnémotechnique : "Après Plusieurs Semaines Tout Respirait La Paix".
Couches TCP/IP
Il existe également le modèle TCP/IP ("modèle internet"), finalisé avant le modèle OSI, qui lui ne propose que 4 parties. Ne pas confondre le protocole TCP et le protocole IP : un protocole peut utiliser un système en couche similaire à celui du modèle TCP/IP mais ne pas utiliser le protocole TCP (par exemple, UDP à la place de TCP).
Comparaison des couches dans les modèles OSI et TCP/IP :
| Modèle TCP/IP | Modèle OSI |
|---|---|
| Couche Application | Couche Application |
| " | Couche Présentation |
| " | Couche Session |
| Couche Transport (TCP) | Couche Transport |
| Couche Internet (IP) | Couche Réseau |
| Couche Accès réseau | Couche Liaison données |
| " | Couche Physique |
Protocoles utilisant le modèle TCP/IP (source de l'image inconnue) :
ICMP est en dessous de TCP et UDP : il n'y a pas de notion de port avec ICMP (on ne peut pas "ping" un port).
La couche 3 utilise 3 processus de base : l’adressage (assignation d'une adresse à un hôte), l'encapsulation ("création" du paquet comprenant les données des couches précédentes + adresses ip source et dest), le routage (sélectionner le chemin), la désencapsulation (on transmet le contenu du paquet à la couche supérieure).
Moyen mnémotechnique : Le prénom "Rita".
Client / Serveur / P2P
Le périphérique qui demande l'information est appelé le client, celui qui répond est appelé serveur. Un serveur contient des informations qu'il va partager à de multiples clients, par exemple, plusieurs clients vont demander une page web au même serveur. Un serveur d'impression va transmettre les demandes d'impression des clients à une imprimante.
Dans un réseau P2P (peer to peer) il n'y a pas de notion client/serveur. Chaque périphérique peut jouer le rôle de serveur ou de client. Par exemple, un PC directement connecté à un autre, ou bien deux PC sur un grand réseau partageant des fichiers entre eux.
Il existe aussi des systèmes hybrides, où les fichiers ne sont pas centralisés mais où l'index des fichiers est centralisé.
TCP et UDP
Les deux protocoles les plus utilisés. L'un s'assure de l'intégrité des données au prix d'une lourdeur de mise en place, l'autre privilégie la vitesse au risque de perdre des données.
Ils utilisent tous les deux la notions de port. Un port permet de filtrer ce que reçoit l'ordinateur. Pour que le client sache vers quel port envoyer ses données, il est défini du côté du serveur (80 pour http, 20/21 pour ftp...). En dessous de 1023, on parle de ports reconnus/réservés. De 1024-49 151 on parle de ports réservés définis par l'Internet Assigned Numbers Authority. Au dessus (jusqu'à 65 535), on parle de port dynamique.
Il n'y a aucune obligation d'utiliser tel port pour tel service. On peut très bien avoir un serveur HTTP qui écoute sur le port 81 au lieu du port 80, mais les clients ne pourront pas deviner où le serveur écoute et ne pourront donc pas accéder au site web. Attention : deux services ne peuvent pas écouter sur le même port.
Le port est aléatoire au niveau du client (par exemple le client ouvre le port aléatoire 50654 et le serveur le 80 pour HTTP afin d'établir une communication).
La commande netstat permet de voir les ports ouverts sur sa machine.
Protocole TCP
TCP est un protocole établissant une connexion full duplex entre 2 applications dialoguant sur 2 ordinateurs ("circuit virtuel"), chaque connexion correspond à un port.
Détection et traitement des erreurs, compression des données, sélection de la méthode de division des données, adressage des paquets de données, retransmet les paquets perdus, garantit la transmission dans l'ordre. Toutes ces fonctionnalités (notamment l'accusé de réception et la retransmission en cas d'erreur) imposent donc une surcharge sur le réseau.
Le récepteur doit aussi garder en mémoire les paquets arrivés dans un mauvais ordre pour les réassembler. C'est le numéro de séquence (ou numéro d'ordre) qui indique l'ordre des paquets. Ce numéro est incrémenté du nombre d'octet ayant été transmis. Par exemple, en commençant par l'octet 1, un PC indique qu'il envoie 10 octets. Le prochain numéro de séquence sera donc 11. S'il envoie là aussi 10 octets, le prochain numéro de séquence sera 21, etc. Normalement, il faudrait un accusé de réception à chaque fois, mais on peut demander un accusé après X données, c'est la "taille de la fenêtre". Augmenter cette taille peut faire baisser l'encombrement sur le réseau car moins d'accusés sont envoyés, attention quand même sur des réseaux peu fiable peu faire augmenter le nombre de paquet retransmis pour cause de défaillance. La taille de fenêtre est géré de façon automatique, selon le nombre de pertes ("fenêtre coulissante").
Le client envoie par exemple 3 segments, le serveur répond avec un accusé de réception. S'il n'a pas reçu cet accusé, le client renvoie les 3 paquets. Il existe aussi un système d'accusés de réception "sélectifs", qui ne redemande que les paquets perdus.
Protocole "fiable", un peu lourd, utilisé avec des protocoles nécessitant que les données arrivent exactement dans leur état d'origine, avec des données très longues, comme HTTP, POP3, FTP.
Les segments TCP comportent un en-tête (avec port source 16 bits, port destination 16 bits, n° de séquence 32 bits, n° d'accusé de reception 32 bits, longueur de l'entête + divers flags tels que ACK pour indiquer qu'il s'agit d'un accusé, SYN utilisé pour l'établissement d'une connection, FIN pour la fermeture de connexion, RST reset de connexion, PSH remise des données à la couche supérieure, URG pour indiquer données urgentes -le tout pour 16 bits, un champ windows pour indiquer le nombre d'octets que la session peut recevoir sans accusé de réception ("contrôle de flux") 16 bits, un checksum de 16 bits, la position urgente de 16 bits), des options facultatives sur 0 ou 32 bits et enfin un champ de données de taille variable. L'ensemble est passé à la couche inférieure (IP), puis inséré dans une trame.
Exemple de trame ethernet contenant du TCP :
08 00 2B E5 BF 8B 00 00 E8 C7 49 6A 08 00 45 00
00 35 00 04 00 00 3C 06 80 B9 7E 00 00 04 7E 00
00 00 00 00 00 00 00 00 0C 09 11 84 60 3B 50 18
0B 40 1E A3 00 00 00 00 00 00 00 00 6F 6C 6F 6D
62 0D 0A
La trame est convertie en hexadecimal pour que ça soit plus facile à lire.
E5 en hexadécimal est équivalent à 1110 0101 en binaire :
1110 devient 14 en décimal, qui devient donc E en hexadécimal.
0101 devient 5 en décimal, qui reste à 5 en hexadécimal.
Penser qu'un symbole hexa est équivalent à 4 en binaire, donc "sur 4 bits". les symboles hexa sont regroupés par 2 car on travaille souvent en octets (sur 8 bits). 08 en hexadécimal vaut 0000 01000 en binaire.
Exemple :
| Décimal | Binaire | Hexadécimal |
|---|---|---|
| 0 | 0000 | 0 |
| 1 | 0001 | 1 |
| 2 | 0010 | 2 |
| 3 | 0011 | 3 |
| 4 | 0100 | 4 |
| 5 | 0101 | 5 |
| 6 | 0110 | 6 |
| 7 | 0111 | 7 |
| 8 | 1000 | 8 |
| 9 | 1001 | 9 |
| 10 | 1010 | A |
| 11 | 1011 | B |
| 12 | 1100 | C |
| 13 | 1101 | D |
| 14 | 1110 | E |
| 15 | 1111 | F |
Pour distinguer les notations décimales/hexadécimales des chiffres de 0 à 9, on ajoute "0x" devant le chiffre. Par exemple, "0x8" indique qu'on travaille en notation hexadécimale (il vaut 8 en décimal et 1000 en binaire).
Plus d'informations sur frameip.com
D'autres infos sur lovemytool.com
Autres explications sur packetlife.net
*Entête Ethernet
Adresse MAC destination : 08 00 2B E5 BF
Adresse MAC source : 00 00 E8 C7 49 6A
Indique qu'il s'agit du protocole IP : 08 00
Entête IP
Version : 4
IHL ("Internet header lengh", longueur de l'entête ip) : 5
Type de Service (TOS, Type Of Service) : 00
Longueur totale du paquet ip : 00 35
Numéro d'identification du paquet (en cas de fragmentation plus tard) : 00 04
Flags (indique si sera suivi d'un autre paquet, si fragmentation autorisée) : 00
Position fragment : 00
TTL (durée de vie maximale du paquet décrémenté d'un chaque routeur, ici à 60 en décimal) : 3C
Protocole utilisé (01 ICMP ; 02 IGMP ; 06 TCP ; 17 UDP) : 06
Checksum (qui devra être recalculé à chaque routeur car TTL change) : 80 B9
IP source (126.0.0.4) : 7E 00 00 04
IP destination (126.0.2.2) : 7E 00 02 02
En image sur sixscape.com
Entête TCP
Port source (en binaire 0000 0000 0000 0000, en décimal 1024+1 = port 1025) : 04 01
Port destination (en binaire 0000 0000 0000 0000, en décimal 16+4+1 = port 21): 00 15
n° de séquence : 00 08 0C 09
n° de reçu : 11 84 60 3B
Longueur de l'entête + réservé + bits de code : 50 18
Champ windows : 0B 40
Checksum : 1E A3
Champ urgent : 00 00
Données
Se traduisent par "User Colomb" : 55 53 45 52 20 63 6F 6C 6F 6D 62 0D 0A
Couche transport dans le modèle TCP/IP et OSI.
Pour établir une connexion TCP :
1) Le client envoie au serveur un SEQ numéro de séquence (aléatoire) contenant le flag SYN (disons, 100).
2) Le serveur répond avec les flags SYN et ACK (avec le numéro d'ordre+1, n° de reçu, donc 101) et génère un nouveau numéro de SEQ (200).
3) Le client répond avec le numéro de séquence égal au numéro d'ordre (101) et le numéro de reçu égal au numéro de SEQ+1 (201).
L'attaque SYN flood se passe lorsque le client saute volontairement l'étape 3, pour laisser le serveur en attente d'une réponse. Un
netstat où beaucoup de connexions sont dans l'état "SYN_RECEIVED" est révélateur de cette attaque.Pour fermer la connexion TCP, 4 étapes :
1)Le client envoie FIN.
2)Le serveur répond avec un ACK.
3)Le serveur envoie à son tour un FIN.
4)Le client répond avec un ACK.
Bonne explication sur firewall.cx
Protocole UDP
Protocole simple, sans connexion, pas de négociation, pas d'accusé de réception, pas de numéro d'ordre pour les datagrammes (les données peuvent arriver dans un ordre différent de l'ordre d'envoi, par exemple si elles ont pris des chemins différents).
Utilisé dans des applications nécessitant de la vitesse et moins de lourdeur, par exemple la lecture de video, la téléphonie sur IP ou les jeux en lignes : si un paquet n'arrive pas, c'est quasiment invisible vu le nombre de données envoyées. Il est également utilisé pour les DNS (sauf dans le rare cas où une réponse dépasse 512 octets, à ce moment TCP est utilisé), TFTP, RIP, SNMP, DHCP.
Le datagramme UDP est composé uniquement du port source, port destination, longueur du message UDP en octet, checksum. Chacun de ces champs est sur 16 bits, ils sont suivis des données.
Attention, UDP n'est pas fiable mais ça ne signifie pas que les applications qui l'utilisent ne le sont pas. Il est tout à fait possible de mettre en place une système de vérification des données dans la couche supérieure. Pour certains protocole ,par exemple pour DNS, la requête est réémise en cas d'absence de réponse.
Modèle de réseau hiérarchique
Plus simple à gérer et à dépanner. 3 couches distinctes : couche d'accès (les périphériques finaux et les switch/hub/où ils se branchent, établissement de VLAN), couche de distribution (délimite les domaines de diffusion, fait de la QoS...) et le coeur du réseau (la voie principale empruntée par le trafic, se connecte éventuellement à internet).
Il existe un modèle plus simple, le "modèle fédérateur", qui regroupe la couche de distributions et le cœur du réseau.
C'est une séparation logique : au niveau physique, la couche d'accès et la couche de distribution pourraient très bien être dans le même local technique.
Un modèle de réseau hiérarchique est plus simple à faire évoluer, redondant (sauf la couche d'accès en général), plus facile à gérer, maintenir, sécuriser et rendre performant.
Le diamètre maximal du réseau est le nombre maximal de périphériques entre une machine et une autre. Ce diamètre est à prendre en compte lors du plan : on peut fait en sorte que la couche d'accès de l'équipe des graphistes ait un faible diamètre jusqu'au serveur qui leur est réservé. Il faut analyser les besoins des communautés d’utilisateurs pour faire un agencement physique et logique cohérent.
On peut agréger la bande passante en connectant deux switchs avec plusieurs câbles (technologie EtherChannel chez Cisco). Dans un plan logique de réseau on utilise un ovale sur un lien pour indiquer une agrégation de bande passante. On peut créer de la redondance en créant différents chemins entre les switchs de la couche de distribution ou du coeur : par exemple, pour aller de la machine A à C, on pourrait mettre un lien direct ET un lien qui passe par B. Si un chemin est en panne, l'autre est utilisé.
Pour la couche de distribution ou le coeur du réseau il faudrait donc dans l'idéal un switch capable de redondance, QoS, agréagation de liaison, ACL, composants redondants (double alimentation pour en remplacer une si l'autre grille), disposant d'un débit élévé.
il y a des besoins différents pour la couche d'accès : aggrégation, PoE, sécurité des ports (quel périphérique peut se connecter à ce port), VLAN.
IPV4
Le protocole ip fonctionne sans connexion : elle n'est pas établie avant l'envoi de données, l'hôte ne sait pas à l'avance que le paquet arrive et l'expéditeur ne sait pas si l'hôte est là/si le paquet arrive. Le protocole IP est "non fiable" (pas d'accusé de réception, de renvoi de paquets, d'assemblement dans le bon ordre...), il ne garantit pas l'envoie des paquets, c'est le travail des couches supérieures comme TCP.
Il est indépendant du support de transmission des données (wifi, fibre optique, ethernet...). Le support détermine néanmoins la taille maximale tu paquet (MTU). La couche liaison de donnée passe à la couche réseau la taille maximum du paquet. Parfois, lors d'un changement de réseau, un routeur doit "fragmenter" le paquet, c'est à dire le découper en plusieurs paquet (avec chacun sa propre entête IP). La couche TCP peut spécifier un "Maximum Segment Size" (mss). Plus d'infos sur nain-t.net
L'adresse ip permet d'identifier un hôte au niveau de la couche 3. L'adresse ip est en quelque sorte l'adresse postale de l'ordinateur (l'adresse mac serait son nuémro de sécurité social).
Le protocole ip permet l'établissement d'un réseau logique, à ne pas confondre avec un réseau physique (deux appareils ou plus connectés à un support commun). Deux machines peuvent être dans le même réseau logique sans être sur le même emplacement géographique (VPN).
Une adresse IPv4 comporte 32 bits, 4 fois 8 bits (4 fois 8 bits) : 00000000 00000000 00000000 00000000
On peut convertir cette adresse en décimal pour que ça soit plus facile à lire.
Par exemple, pour le premier octet :
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
On a 128+64+0+0+0+0+0+0=192.
Pour le deuxième octet :
| 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
On a 128+0+32+0+8+0+0+0=168.
En décimal, elle se lit donc : 192.168.2.1
Adresse réseau
Une partie de cette adresse indique le réseau, une autre partie indique l'hôte. On peut choisir quelle partie indique quoi avec un masque de sous réseau. Selon les situations, on pourra vouloir peu de réseaux avec beaucoup d'hôtes, ou beaucoup de réseaux avec quelques hôtes.
Diviser un grand réseau en plusieurs permet d'améliorer les performances. On peut diviser un grand réseau en plusieurs selon différents critères : géographique (si la distance est grande), par secteur d'activité (un même secteur génère un trafic réseau proche, par exemple le secteur des graphistes va échanger de lourdes données / le secteur des vendeurs en échangera moins), par besoin d'accès (on peut vouloir se connecter depuis l'extérieur à ce réseau mais pas celui-là).
Masque réseau
Un masque de sous-réseau indique quelle partie de l'adresse IP représente le réseau.
Par exemple, pour l'ip 00001001.00000000.00000000.00000001, autrement dit "11.0.0.1". On pourrait décider que les 8 premiers bits indiqueraient le réseau (et donc les 24 derniers indiquent l'hôte sur ce réseau). Ce qui s'écrit simplement "11.0.0.1/8". On parle de "préfixe /8", c'est la notation CIDR (Classless Inter-Domain Routing).
Le masque pourrait également se noter en décimal "255.0.0.0". Ce qui donne, en binaire : 11111111.00000000.00000000.00000000, ce qui revient au même que de noter "/8". Dans cet exemple, il y a donc 255 réseaux possibles. Dans un seul de ces réseaux, il peut y avoir (256*256*256) 16 777 216 machines (moins 2 pour l'adresse réseau et celle de broadcast, voir plus bas).
On pourrait aussi mettre un masque en 255.255.255.0 (autrement dit, préfixe /24). Dans ce cas là, il y a 16 777 214v réseaux possibles et 255 hôtes dans chacun de ces réseaux.
/8 (autrement dit 255.0.0.0 ou 11111111.00000000.00000000.00000000), /16 (autrement dit 255.255.0.0 ou 11111111.11111111.00000000.00000000) et /24 (autrement dit 2555.255.255.0 ou 11111111.11111111.11111111.00000000) sont des masques très utilisés.
Le masque donne le nombre de machines qui nous entourent.
Classes
Les IP sont divisés en classes A, B, C, D et E. Autrefois, cela dispensait d'utiliser les masques réseaux pour certains protocoles. On pouvait déduire l'adresse réseau selon sa classe. C'est "l'adressage par classe". Par le passé, une entreprise se voyait attribuer un bloc d'adresse d'une classe. Certaines entreprises possèdent encore des ip de classe A et ont donc à leur disposition 16 millions d'adresses.
Une ip de classe A (de 1.0.0.0 à 127.0.0.0 -soit les adresses commençant par 0 en binaire, "bits d'ordre haut") avait un masque de 255.0.0.0, une B de (128.0.0.0 à 191.0.0.0 -adresses dont les bits d'ordre haut commencent par 10) avait un masque de 255.255.0.0, une C (192.0.0.0 à 223.0.0.0 -commençant par 110 en binaire) avait un masque /24.
Plus d'infos sur wikipedia
Aujourd'hui, tous les protocoles récents supportent les masques réseau, donc la notion de classe n'est plus aussi importante. On retrouve tout de même cette notion encore aujourd'hui dans windows par exemple quand on renseigne une ip : le sous-réseau proposé automatiquement est celui de la classe de l'ip qu'on vient de taper.
Masque de sous-réseau variable
Ou "VLSM" (Variable Length Subnet mask).
On est pas obligé de se limiter à /8 (255.0.0.0), /16 (255.255.0.0) ou /24 (255.255.255.0). On peut très bien indiquer que les 25 premiers bits indiquent le réseau. On aura donc : 11111111.11111111.11111111.100000 ou 255.255.255.128, autrement dit /25. Ici, si on applique ce masque à une adresse de type 192.168.1.x, il y aura 2 sous réseau : un premier de 192.168.1.1 à 192.168.1.127, un deuxième de 192.168.1.128 à 192.168.1.255.
Cette technique permet de donner le nombre exact d'ip nécessaires pour un réseau.
Par exemple, imaginons que l'on veuille faire 3 sous réseau avec 100 hôtes dans le premier, 50 dans le deuxième et 25 dans le troisième.
On aura :
-192.168.9.0/25
-192.168.9.128/26
-192.168.9.192/27
Il existe finalement assez peu de VLSM possibles :
00000000 = 0
10000000 = 128
11000000 = 192
11100000 = 224
11110000 = 240
11111000 = 248
11111100 = 252
11111110 = 254
11111111 = 255
Un calculateur de VLSM
Adresse réseau
L'adresse réseau est la première adresse du réseau.
Par exemple, l'adresse réseau de la machine 192.168.2.1/24 est 192.168.2.0, l'adresse réseau de la machine 10.2.3.4/8 est 10.0.0.0.
Dans une adresse réseau, tous les bits représentant l'hôte sont à 1. Elle est toujours paire.
Domaine de broadcast
Ou "domaine de diffusion". Un broadcast est un message envoyé à tous les membres d'un réseau. En général, il s'agit du message d'un ordinateur qui veut communiquer avec une machine dont l'adresse ip lui indique qu'elle se trouve sur le réseau sans qu'il sache précisément qui elle est. Il envoie alors son message à tout le réseau dans l'espoir qu'elle réponde (voir la partie "requête ARP").
Créer des sous réseau limite la diffusion des messages de broadcast et améliore donc les performances.
L'adresse de diffusion est la plus haute adresse du réseau. Par exemple, l'adresse de diffusion de 192.168.2.1/24 est 192.168.2.255, celle de 10.0.0.0/9 sera 10.127.255.255. Elle est toujours impaire.
Nombre d'hôtes
Pour calculer le nombre d'hôte, on utilise la formule "(2 puissance (le nombre de bits laissés pour les hôtes)) moins 2".
Par exemple, si on a besoin de 1000 hôtes :
2*2*2*2*2*2*2*2*2*2=1024
Il faut donc laisser 10 bits dans l'adresse pour les hôtes. Le réseau sera donc en /22 :
255.255.252.0, par exemple 192.168.0.0/22 (2^6=64 donc 4 sous-réseaux, donc adresse de broadcast 192.168.3.255).
Ensuite, on peut découper encore une fois ce nombre d'hôte, par exemple en 2, pour avoir un réseau 192.168.0.0/23 (255.255.254.0, adresse de broadcast 192.168.1.255 car 2^1=2, donc 128 sous réseaux) contenant 500 hôtes.
On peut encore découper, pour avoir, à la fin, un sous réseau de 500, un autre de 200, un autre de 40, par exemple.
Penser à toujours commencer le découpage par le plus gros. Travailler sur papier et s'assurer que les sous-réseaux ne se superposent pas.
Un outil pour calculer
Premiers exemples
Une adresse 178.155.23.188/18.
1)On calcule à quoi correspond le /18. C'est un /16 (255.255) + 2 bits (128+64).
11111111.11111111.11000000
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
Donc le masque en notation décimale est 255.255.192.0.
2)Combien y a-t-il de sous réseau (sans compter les octets complets) ? 192 est un masque, il faut l'appliquer à l'envers, sans oublier le 0 : 256-192=64. 4 réseaux.
Autre technique plus simple qui exploite le fait que le binaire fonctionne en puissance de 2. Prendre les bits des octets incomplets et mettre en puissance de 2. Ici, il y a 2 bits, on les met en puissance de 2. 2^2 (c'est à dire 2*2) =4 sous-réseaux.
3)On regarde dans quel sous-réseau se situe 178.155.23.188. C'est le "23" qui est à observer ici, il est inférieur à 64, il se situe donc dans le premier sous-réseau.
4)On peut donc déduire l'adresse réseau : 172.155.0.0 et l'adresse de broadcast : 172.155.63.255.
Une adresse 143.254.190.250/29 :
1)/29, c'est /24 plus 5 bits (128+64+32+16+8), donc 248.
2)2^5 (2*2*2*2*2) = 32 sous-réseaux. 256/32=8, tous les 8. C'est aussi là où est le tout dernier bit.
3)On essaye le multiple de 8 qui se rapproche le plus du nombre recherché (250). 8*30=240. On voit qu'on peut rajouter 8, 248, mais pas plus sinon ça dépasse 250. Donc il est dans la tranche 248 et 255.
4)Adresse réseau 143.254.190.248. ; broadcast 143.254.190.255.
Une adresse 179.75.197.132/25 :
1) /25 c'est /24 qui est connu (255.255.255.0) auquel on rajoute 1 bit. Donc 255.255.255.128
2)Combien de sous-réseaux ? 2^1 = 2.
3)Adresse dans le 2e sous-réseau car 132 est supérieur à 128.
4)Adresse réseau : 179.75.197.128 ; broadcast 179.75.197.132
Une adresse 167.55.131.128/22 :
1)/22 ça ressemble à /24 qui est connu. Donc 255.255.255.0 moins 2 bits, c'est à dire 2+1. Donc 255.255.252.0.
2)Combien de sous réseaux ? 2^6=64.
3)C'est tous les 4 (64*4=256). Adresse entre 128 et 132.
4)Adresse réseau : 167.55.128.0 ; Broadcast : 167.55.131.255
2eexemple
On veut faire un réseau de 28 personnes, un autre de 12 personnes, en prenant le moins de place possible. 192.168.1.0
1)28 personnes, il faudra prendre des tranches de 32. 24=tranche de 255, /25=2 tranches de 128... /26 4 tranches de 64... Ce sera donc /27.
192.168.1.0/27
Le réseau ira donc jusqu'à 192.168.1.32.
2)Pour celui de 12 personnes, on va utiliser les tranches de 16, donc 192.168.1.32/16.
3e exemple
On veut deux réseaux. Réseau A avec 110 hôtes utilisant 192.168.7.0 et réseau B avec 54 hôtes.
A) 110 hôtes, c'est proche de 128, or 256-128=128. Le masque sera 192.168.7.0/255.255.255.128. C'est rajouter un bit : /25. L'adresse du routeur pourrait être la dernière, 192.168.7.126.
B) 54 hôtes, c'est proche de 64, or 256-64=192. Le masque sera 192.168.7.0/255.255.255.192. C'est rajouter 2 bits donc : /26. L'adresse du routeur pourrait être 192.168.7.190.
4e exemple
On veut 2 réseaux, un de 174 hôtes et un de 60, en prenant le moins de place possible.
1)192.168.1.0/24, dernière adresse d'hôte 192.168.1.254.
2)192.168.2.0/26, dernière adresse d'hôte 192.168.2.62.
5e exemple
//www.subnettingquestions.com/ posent ce genre de question :
Combien de sous-réseaux et d'hôtes par sous réseau pouvons nous obtenir à partir du réseau 172.28.0.0/26 ?
En /26 (ou 255.255.255.192), le nombre d'hôte est assez évident. Pour le trouver, calculer "256-192" ou compter les bits libres :
11111111.11111111.11111111.11000000 = 6 bits, donc 32+16+8+4+2+1 (+1 pour prendre en compte le 0).
64 emplacements disponibles, auxquels on enlève broadcast et réseau, donc 62 hôtes possibles.
Combien de "sous réseaux" ? La question peut sembler étrange mais c'est un problème de vocabulaire : 172.28.0.0 est un réseau de classe B, sont masque devrait être de /16, donc les 10 bits qui viennent après sont considérés comme étant un "sous-réseau".
Donc en additionnant ces bits pour avoir le nombre maximum de combinaisons qu'il peuvent prendre, on arrive à 512+256+128+64+32+16+8+4+2+1=1023+1 pour prendre en compte le 0=1024.
Donc 1024 subnets et 62 hosts.
Comparaison par bits
Le système utilisé par les machines pour trouver l'adresse réseau avec le masque.
1 et 1 donne 1, 0 et 1 donne 0, 0 et 0 donne zéro.
11000000.00000000.00000000.00000001 #adresse ip : 192.0.0.1
11111111.11111111.00000000.00000000 #masque /16 (255.255.0.0)
-----------------------------------
11000000.00000000.00000000.00000000 #adresse réseau : 192.0.0.0
10001111.11111110.10111110.11111010 #143.254.190.250
11111111.11111111.11111111.11111000 #masque /29 (255.255.255.248)
-----------------------------------
10001111.11111110.10111110.11111000 #adresse réseau : 143.254.190.248
Types de communications IPV4
Les hôtes peuvent communiquer de 3 façon : monodiffusion ("unicast" d'une IP à une seule autre IP), diffusion ("broadcast", à toutes les ip), multidiffusion ("multicast", à plusieurs ip à la fois).
On peut faire un broadcast à un réseau distant (diffusion dirigée, "Directed Broadcast").
On peut effectuer un déploiement windows en multidiffusion pour envoyer les mêmes données à plusieurs machines à la fois, ce qui économise la bande passante car un seul paquet envoyé (et "dupliqué" par le switch).
Adresses réservées
Certaines Ip sont réservées pour les réseaux privés, par exemple un LAN dans une entreprise :
-de 10.0.0.0 à 10.255.255.254 pour la classe A (10.0.0.0 /8),
-de 172.16.0.0 à 172.31.255.254 pour la classe B (172.16.0.0 /12),
-de 192.168.0.0 à 192.168.255.254 pour la classe C (192.168.0.0 /16).
Ces IP ne sont pas routées sur internet (pour y accéder, elle doivent passer par un NAT, qui va convertir l'adresse, par exemple 10.0.0.1 et 10.0.0.2 seront convertis en 81.12.9.1 par la box adsl).
Les IP ci-dessous sont aussi des IP séservées, non-routées sur internet (il n'y a pas de route vers elles sur internet).
-La plage de 224.0.0.0 à 239.255.255.255 est réservée à la multidiffusion. Le Network Time Protocol fonctionne avec 224.0.1.1. Cette plage-ci, contrairement aux autres réservées, peut être utilisée sur internet, par exemple pour la télévision sur ip ou certaines webradios.
-De 240.0.0.0 à 255.255.255.254, il s'agit d'une plage spéciale d'adresses expérimentales (pour la recherche), peut être utilisées sur internet dans le futur.
-Impossible d'utiliser une adresse commençant par 0 (sauf 0.0.0.0 qui sert à indiquer une route par défaut).
-L'adresse 127.0.0.1 est une adresse de bouclage ("loopback adress"), c'est à dire l'adresse qu'un hôte utilise pour rediriger du trafic vers lui même. Pratique quand on héberge un serveur sur son PC. L'intervalle 127.0.0.0-127.255.255.255 ne doit pas être utilisé. On peut définir d'autres adresses comme étant adresses de bouclage, 127.0.0.1 est celle par défaut.
-De 169.254.0.0 à 169.254.255.255, il s'agit d'adresses APIPA (Automatic Private Internet Protocol Addressing), appliquées lorsque le PC demande une adresse à un serveur mais qu'il n'obtient pas de réponse.
-Les adresses de 192.0.2.0 à 192.0.2.255 sont des adresses pédagogiques, qui servent aux étudiants.
Adresses publiques
Les adresses routables et accessibles sur internet, elles sont uniques mondialement. Attribuée par l'IANA (Internet Assigned Numbers Authority) et les registres internet régionaux (AfriNIC -African Network Information Centre, APNIC -Asia Pacific Network Information Centre, ARIN -American Registry for Internet Numbers, LACNIC -Latin-American and Caribbean IP Address Registry), RIPE NCC). Le FAI prête des adresses à ses clients. En général, pour les particuliers, on a une adresse par ligne téléphonique.
ICMP
ICMP (Internet Control Message Protocol) sert à véhiculer des messages d'erreurs et de contrôles entre les hôtes. L'utilitaire ping utilise le protocole ICMP et les messages Echo Request/Echo Reply. Il existe également le message "ICMP Destination Unreachable" qui peut être envoyé si un hôte ne sait pas où envoyer le paquet. Le message "Time Exceeded" indique que le TTL du paquet ip que le routeur vient de recevoir est à 1, il le décrémente à 0 et envoie le message. Un message "Route redirection" peut aussi être émit pour indiquer qu'une meilleur route est disponible.
Route redirection (Redirection de la route). Un hôte peut aussi indiquer "Source Quench" pour dire qu'il commence à saturer et demander que l'envoyeur baisse la fréquence d'émission des messages.
IPv6
IPv6 a plusieurs avantages par rapport à IPV4 :
-Adressage sur 128 bits, donc beaucoup plus d'adresse disponibles.
-Entête simplifiée.
-Un emplacement dans l'entête pour étiquetter le flux afin de faire de la QOS.
-Element d'entête facultatif sur 8 bits pour évolution future ou personnalisation.
-Pensé pour la sécurité (IPsec a été penser en premier lieu pour marcher avec IPV6).
IPv6 s'inscrit dans toute une suite de protocoles, par exemple ICMPv6.
Une adresse IPv6 se compose de 8 champs de 16 bits exprimés en hexadécimal, par exemple :
2001:0db8:0000:85a3:0000:0000:ac1f:8001
Couche 2 du modèle OSI
Elle prépare les données pour le transfert sur le support physique. Elle permet au protocole de la couche supérieure (IPv4, par exemple) de ne pas se soucier du support sur lequel il est transporté (éthernet, wifi, fibre...) Les protocoles de cette couchent spécifient le format de la trame qui va encapsuler un paquet. Les trames seront différentes selon les supports. Un routeur peut modifier la trame. Une séquence de bits détermine le début et la fin de la trame (diverses techniques sont utilisée pour éviter que les données ne soient vues comme des délimiteurs, "delimiter collision", voir cette page bien détaillée en japonais.
Divisée en 2 sous-couches :
-LLC (Logical link control) : indique les VLAN, type de protocole encapsulé, aquittement, contrôle d'erreur, QoS, indication d'encombrement).
-MAC (Media Access Control) : assure l'adressage, formate les données de manière appropriée selon le support, place/récupère les données sur les supports, encapsulation, détection des erreurs, détermine si la trame peut être envoyé, s'il n'y a pas eu de collision avec d'autres trames.
Le champ contrôle d'erreur (checksum) est calculé lors de l'émission de la trame selon le contenu puis recalculé à l'arrivé selon la même formule, si le résultat n'est pas le même, les données ont été corrompues pendant le voyage et la trame est ignorée. On peut aussi parfois utiliser un CRC (Cyclic Redundancy Check, contrôle de redondance cyclique, un peu plus complexe qu'un checksum) pour contrôler l'intégrité des données. La quantité d'informations de contrôle requise dépend du support : par exemple, moins de contrôle nécessaire sur un support par câble que par ondes satellites.
Contrairement à beaucoup de protocoles de la couche supérieure, les protocoles de cette couche ne sont pas décrits dans un RFC (un document décrivant le protocole, "Request For Comments") mais par des organismes internationaux de normalisation car elles sont très liées au matériel tel que les carte réseau (en anglais "NIC", Network Interface Card). Ainsi, les normes wifi sont gérées par l'IEEE.
Quelques organismes :
UIT : Union internationale des télécommunications, département des nations unies.
IEEE : Institue of Electrical and Electronics Engineering, élabore les normes informatiques et électronique (IEEE 802 pour les LAN et MAN).
ISO : organisation internationale de normalisation. A créé la norme OSI (système de couches).
IAB : Internet Architecture Board, supervise développement technique et structurel d'internet.
CEI : Commission Electronique Internationale.
ANSI : American National Standard Institute.
TIA/EIA : Telecommunication Industry Association et Electric Inustrie Alliance, met en place des normes concernant l'industrie électronique.
En Full Duplex les périphériques peuvent écouter et recevoir en même temps, en Half Duplex ils ne peuvent que recevoir ou que écouter.
| Topologies | ⇒ | Topologie physique : la manière dont sont agencés physiquement entre eux. Topologie logique : la façon dont le réseau transfert les trames d'un périphérique à un autre. C'est elle qui influence le type de trame réseau. On pourra avoir, en topologie logique, 2 PC connectés l'un à l'autre, alors qu'ils sont physiquement séparés par des centaines de périphériques (VPN). |
| IEEE 802.3 | ⇒ | "Norme Ethernet", norme internationale que les constructeurs de périphérique Ethernet doivent respecter. Ethernet fonctionne selon la méthode d'un accès multiple au support : lorsqu'une machine veut envoyer une trame à une autre, toutes les machines du "domaine de collision" (c'est à dire "partageant le même support", se gênant les unes les autres) voient la trame. Seul la machine à qui est destinée la trame la traite. Sur un domaine de collision, un seul périphérique peut envoyer un message à la fois. IEEE 802.3 impose la prise en charge du CSMA/CD (Carrier Sense Multiple Access with Collision Detection). Avec CSMA, chaque station écoute le cable et vérifie qu'une autre machine n'est pas en train d'émettre. Si 2 machines émettent en même temps, il se produit une collision et une perte de données. Les machines peuvent détecter les collision (Collision Detection), le cas échéant elle enverra aux autres un signal de bourrage (Jam Sequence), puis les périphériques attendent un temps aléatoire avant de reémettre. Le débit peut être réduit de 40% s'il y a beaucoup de collision. Le matériel réseau de niveau 2 ou supérieur permet de réduire ou même supprimer les risques de collision (en séparant les stations, elles n'utilisent plus le même support). Il existe aussi la technique CSMA/CA (Carrier Sense Multiple Access with Collision Avoidance), qui, au lieu d'écouter les collisions, demande à la destination s'il peut envoyer. Utilisé dans le wifi. La norme Ethernet fut publiée en 1980 par un consortium de Digital Equipment Corporation, Intel et Xerox (DIX), inventée dans les années 70 par Robert Metcalfe (fondateur de 3COM). Inspirée de "Alohanet", un réseau radio numérique entre îles hawaiennes où la communication se faisait sur la même fréquence (donc nécessité de contrôle ⇒ CSMA). Au début, la topologie physique était en bus (les PC branchés à un cable les traversants, utilisant une "Attachment Unit Interface"), mais devant les contraintes physiques la topologie en étoile (PC branchés à un concentrateur) s'est répandue. Actuellement, c'est la 2e version du protocole Ethernet qui est utilisée ("DIX Ethernet" ou "Ethernet II" -DIX signifiant "Digital Equipment Corporation, Intel et Xerox"). La taille minimale d'une trame (préambule et délimiteur de début de frame non-inclu) selon la norme IEEE 802.3ac, est de 64 octets (en dessous, la trame est abandonnée), la maximale étant de 1.522 octets. La taille maximale a été augmentée en IEEE 802.3ac pour inclure le champ VLAN (de la norme 802.1q). Pour Ethernet des débits de 100 Mbits/s ou supérieur, l'implémentation est dite "synchrone". Les 64 bits de préambules ne seraient plus nécessaires (mais sont gardés pour compatibilité) car en mode synchrone le récepteur attend la trame. Sur Ethernet 10 Mbits/s, il faut 100 nanosecondes (ns) pour transmettre un bit au niveau de la couche MAC. À 100 Mbits/s, il lui faut 10 ns pour procéder à la transmission. À 1 000 Mbits/s, il lui faut seulement 1 ns pour procéder à la transmission. Un espacement intertrame est une durée entre chaque trame pour laisser le temps à un périphérique de se préparer à la suivante. Il est de 96 bits, autrement dit 9,6μs à 10 Mbit/s, 0,96μs à 100 Mbit/s, etc. |
| Fenêtre de collision | ⇒ | Ou "slot time". Le temps nécessaire pour qu'une impulsion électrique parcoure la distance maximale possible entre 2 noeuds. Correspond également au temps d'attente d'un périphérique avant d'essayer d'émettre suite à une collision. En d'autre termes : il y a émission une fois qu'on est sûr que la trame soit arrivé à destination (en attendant le temps maximum que prendrait une trame à aller vers un périphérique le plus loin possible). Un bit met environ 20,32 cm par nanoseconde pour se propager sur un câble UTP. Le nombre de bits qui peuvent être envoyés durant la fenêtre de collision est de 512 bits sur du 10Mbit/s en 51,2 micro-secondes. Il faut 100 nanosecondes pour mettre un bit sur un support 10Mbit/s. Pour du 100Mbit/s, qui envie un bit en 10 nanosecondes, la fenêtre de collision sera de 512 bits, et durera 5,12μ s. Si une collision se produit, elle sera détectée dans les 512 premiers bits. Sur du 1Gbit/s, elle fera 4096 bits en 4,096μs (un bit par nanoseconde). Bonne explication et schéma chez guill.net Problèmes : -Ici, un périphérique double le temps de la fenêtre de collision avant de renvoyer son paquet : http://searchnetworking.techtarget.com/definition/slot-time -Ici, la fenêtre de collision est égale à 2 fois le temps qu'il faudrait à une impulsion pour traverser 100m. http://en.wikipedia.org/wiki/Slot_time http://cvardon.fr/collisions.pdf -Chez cisco, la fenêtre de collision ET le temps d'attente est égal au temps qu'il faudrait à une impulsion pour traverser 100m. "Durée nécessaire pour qu'une impulsion électrique parcoure la longueur de la distance théorique maximale séparant 2 noeuds. Il s'agit également de la durée d'attente d'une station émettrice avant qu'elle ne tente une retransmission à la suite d'une collision. -La fenêtre de collision n'étant pas la même pour du 1Gbit/s, cela signifie-t-il que la taille minimal d'un paquet est plus grand (512 octets au lieu de 64 octets ?) ? Mon opinion : la fenêtre de collision vaut un peu plus que le double du temps nécessaire à un aller retour sur 100m. Cela permet d'interrompre l'envoie d'une trame dès qu'une collision est détectée. Exemple perso (pas sûr que de sa validité) : 1. la station A envoie une trame à la station B. 2. la station B envoie juste avant de recevoir la trame. 3. la station B reçoit la trame de A, elle détecte une collision, elle envoie un signal de 32 bits indiquant bourrage. 4. la station A reçoit le signal de B alors qu'elle allait presque finir sa trame, elle se rend compte qu'il y a eu collision et qu'elle va devoir va réémettre sa trame. |
| Adresse MAC | ⇒ | "Media Access Control", 12 chiffres hexadécimaux pour identifier une carte réseau. Exemple : "00:24:2c:2c:e2:85". Les 3 premiers octets sont l'identifiant du fabriquant de la carte (OUI, "Organizationally Unique Identifier"). Codée dans la mémoire morte (ROM)) de la carte, sert "d'empreinte digitale". Un système d'exploitation peut néanmoins tricher et assigner une fausse MAC à une carte (dans le gestionnaire de périphérique sous windows, propriétés de la carte). ipconfig /all ou ifconfig pour afficher son adresse MAC. arp -a pour afficher les adresses MAC des ordinateurs sur le même domaine de broadcast.Pourquoi a-t-on besoin d'une adresse MAC ET d'une adresse IP ? Le périphérique a besoin d'une adresse MAC pour trouver les autres machines sur le domaine de broadcast. Il va faire la demande "qui a telle ip ?", une machine va répondre en donnant l'adresse mac correspondant à l'ip (requète ARP). Avoir une adresse ip et une adresse mac est pratique quand on change de réseau. L'adresse MAC permet d'orienter la trame à l'intérieur d'un domaine de broadcast (elle change à chaque routeur), l'IP permet de l'orienter au delà. L'adresse MAC rajoute un système d'adressage, ce qui permet d'avoir différents systèmes d'adressage de couche 3, par exemple de passer à IPV6 sans changer de matériel. Egalement, certains protocoles de couche 3 n'utilisent pas IP et fonctionnent grâce à l'adresse MAC (IPX, partie réseau+adresse MAC). DHCP (un système d'acquisition automatique d'une IP) a besoin d'identifier l'ordinateur avant de lui donner une ip, il le fait avec son adresse MAC. Explications en anglais L'adresse MAC permet la monodiffusion (unicast, envoie de trame à une adresse mac précise), la diffusion (broadcast, envoie de trame à FFFFFFFFFFFF, toutes les machines sur le domaine de broadcast la reçoivent) et la multidiffusion (multicast). Pour désigner un groupe de machines avec une adresse MAC, un OUI spécial a été créé : "01-00-5E". Ces 3 octets désignent une adresse mac multidiffusion. Les 23 bits le plus à droite de l'adresse MAC sont remplis avec les 23 bits les plus à droite dans l'adresse IP multicast. Par exemple, l'adresse MAC "01-00-5E-00-00-01" sera associée à l'adresse ip de milticast "224.0.0.1". Le dernier bit, entre le OUI et les 23 bits, est un 0. Avec 23 bits, il peut arriver que certaines machines reçoivent un paquet multicast qui ne leur est pas destiné. Plus de détails |
| IEEE 802.5 | ⇒ | Token ring. Norme mettant en place un accès contrôlé au support au support pour éviter les collisions : un paquet parcourt l'anneau. Si un hôte veut émettre, il ajoute ses données au paquet avec l'adresse. Pose des contraintes au niveau de la topologie physique (il faut faire une boucle avec les hôtes). Token ring n'a plus eu d'intérêt une fois que les switchs (qui limitent les domaines de collision) se sont démocratisés. Placer les données sur le support s'appelle le "contrôle d’accès au support". On peut contrôler beaucoup avant de placer (plus de surcharge, Token Ring), ou contrôler moins (détection de collision). |
| IEEE 802.11 | ⇒ | Normes pour le wifi. 802.11a=54Mbit/s / bande de 5GHz / 45,7m / Non-compatible b, g et n. 802.11b=11Mbit/s / 2,4GHz /91m / Compatible 802.11g. 802.11g=54 Mbit/s / 2,4 GHz / 91m / Compatible avec b. 802.11n=600Mbit/s / 2,4GHz ou 5 GHz/ 250m / Compatible avec tout. Pour éviter les collisions, le wifi utilise CSMA/CA (Collision Avoidance) et non pas un système de détection de collision. D'une part car l'hôte A peut voir B mais ne peut pas forcément voir que B est en train d'écouter C (A ne voit pas C car il est trop loin, par exemple). D'autre part car le wifi est half-duplex, contrairement à un câble, il ne peut pas écouter et émettre en même temps (son antenne est un émetteur-récepteur, "transreceiver") ce qui lui permettrait de reconnaitre les collisions et d'arrêter d'émettre. Ils doivent attendre que le support soit libre avant d'émettre, demander si ils peuvent envoyer (Demande pour émettre/Prêt à émettre), puis un accusé de réception doit être envoyé. Un ensemble de services de base ("BSS") est l'ensemble formé par le point d'accès et ses clients. Egalement appelé "Basic Service Area". Identifiés par un BSSID (correspondant à l'adresse mac du point d'accès). Un reseau "ad hoc" permet à 2 machines de communiquer entre elles en wifi sans avoir besoin de machine tierce. On parle parfois de IBSS (ensemble de service de base indépendant). S'il y a plusieurs points d'accès, on parle de ESS, éventail de services étendus, s'étendant sur une "Extended Service Area". On dit généralement qaue les points d'accès sans fil fonctionnent au niveau de la couche physique. Le point d'accès emet régulièrement une trame "Beacon" pour annoncer sa présence. Puis, le client fait une "analyse" avec une requète d'infos sur un réseau, éventuellement désigné par un ssid. Suivi par une authentification (défi de clef wpa) et enfin une association durant laquelle sont échangées les addresses mac et où le point d'accès donne au client un "Association Identifier", port logique. 802.11i=norme WPA2, chiffrement AES. Fonctionne avec clef pré-partagée (Pre Shared Key). Sur certain modèles on peut aussi s'authentifier en PK2 via un serveur différent du point d'accès (option "PSK2 entreprise" sir les Linksys). Cacher le SSID ou filtrer avec les adresses mac ne sont pas des moyens de sécurités appropriés (trafic visible et adresse mac se change). Pour se connecter à un SSID caché, il faut le saisir manuellement dans les propriétés de la connexion réseau sans fil. Il y a 13 canaux en europe, 11 aux USA. Les canaux 1, 6 et 11 ne se chevauchent pas. Les appareils électroménagers perturbent souvent les canaux autour du canal 6. Plus d'infos sur le site univ-mlv.fr |
| IEEE 802.15 | ⇒ | Bluetooth. Vitesse inférieure à 1 Mbit/s. De 1 à 100m. 7 périphériques maximum, fréquence radio de 2.4 à 2.483,5 Ghz. Technologie adaptative (AFH, Adaptive Frequency Hopping) pour réduire les interférences. |
| IEEE 802.16 | ⇒ | Wiimax. | Pour la version 802.16e, 2-6 GHz, 30 Mbit/s sur 3,5 km. |
Trame Ethernet
Une trame de type Ethernet II, encapsulant un datagramme IP encapsulant lui même de l'ICMP :
AA AA AA AA AA AA AA AB 00 24 2c 2c e2 85 54
04 a6 63 ca 77 08 00 45 00 00 3c 32 c3 00 00
80 01 84 93 c0 a8 01 0e c0 a8 01 0c 08 00 4d
2f 00 01 00 2c 00 00 00 00 00 00 00 00 69 6a
6b 6c 6d 6e 6f 00 00 00 00 00 00 00 00 61 62
00 00 00 00 00 00 00 00 45 AA B1
[Trame Ethernet]
AA AA AA AA AA AA AA : Préambule (7 octets). Chaque A représente "10101010" en binaire.
AB : "Start of Frame delimiter", "SoF" (1 octet), "10101011", sert de délimiteur pour annoncer la trame.
00 24 2c 2c e2 85 : Adresse MAC de destination.
54 04 a6 63 ca 77 : Adresse MAC source.
08 00 (2 octets) : indique ici type de protocole encapsulé (IP). Ce champ peut aussi être utilisé pour indiquer la taille de la trame (si inférieur à 1500 en décimal).
[Datagramme IP]
45 : longueur de l'en-tête.
00 : Type de Service (TOS, Type Of Service).
00 3C : Longueur totale du paquet ip (60 octets).
32 C3 : Numéro d'identification du paquet (en cas de fragmentation plus tard).
00 : Flags (indique si sera suivi d'un autre paquet, si fragmentation autorisée).
00 : Position fragment.
80 : TTL (durée de vie maximale du paquet décrémenté d'un chaque routeur, ici à 128 en décimal).
01 : Protocole utilisé (01 ICMP ; 02 IGMP ; 06 TCP ; 17 UDP)
84 93 : Checksum (qui devra être recalculé à chaque routeur car TTL change).
C0 A8 01 0E : IP source (192.168.1.14)
c0 a8 01 0c : IP destination (126.0.2.2)
A noter : en ethernet, on a destination puis source, en IP on a d'abord la source puis la destination.
[Segment ICMP]
08 : Type de requète ICMP, ici une demande d'echo.
00 : code d'erreur.
4D 2F : Somme de contrôle.
00 01 : identifiant (n° du ping, varie selon les versions de Windows, assigné à un processus sous linux).
00 2C : Numéro de séquence (nombre aléatoire qui reset au démarrage de windows).
00 00 00 00 00 00 00 00 69 6a 6b 6c 6d 6e 6f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 69 : Pour remplir le paquet (si le datagramme est plus petit que 28 octets il est invalide).
[/Segment ICMP]
[/Datagramme IP]
18 45 AA B1 : Séquence de contrôle de la trame (exemple fictif)
[/Trame Ethernet]
Couche 1 du modèle OSI
La couche physique créé les signaux électriques, lumineux, ondes radios représentant les bits. Elles peut ajouter ajouter un signal pour indiquer le début d'une trame de couche 2 (en plusn par exemple du préambule Ethernet lui-même, la couche 1 créé ses propres séparateurs). Ce sont les mêmes organisations internationales de normalisation que celles de la couche 2 qui définissent les protocoles. Ils définissent les propriétés électriques/mécaniques, définissent la façon dont sont envoyés les informations de contrôle, la représentation du binaire (durée d'un bit, puissance du signal..."méthode de signalisation" ou "codage"), les voltages, les types de connecteurs, etc. de façon à ce que le matériel reste compatible.
Un bit peut être représenté de différentes façons : par variation de la tension, par variation de la fréquence (fréquence basse+0, élevée=1 par exemple), variation de phase. Les hôtes utilisent une horloge pour mesurer ces variations.
Différents exemples de codages chez workig.free.fr
La méthode non-retour à zéro ("NRZ") utilise la variation de tension. Elle est sensibles aux interférences, ne peut pas être utilisé pour les connections à haut débit. Lorsque plusieurs 0 sont envoyés à la suite, aucun signal n'est transmis, ce qui peut être interprété comme une perte de connexion. Lorsque plusieurs 1 ou 0 sont transmis à la fois, difficile de savoir combien ont été envoyés car il n'y a pas de séparation.
Le Codage Manchester utilise les transition de tension. Par exemple, une transition d'une tension faible vers une tension élevée peut représenter le 1. Une transition d'une tension élevée vers une tension faible représenterait le 0. Pour envoyer une suite de 5 zéro, on pourrait baisser la tension 5 fois. Utilisé pour l'Ethernet 10BASE-T (câbles cat 3).
Parfois, une séquence de signaux n'est pas égal à la même séquence de bits. On parle de "groupe de code". Par exemple, la séquence "1010101010" pourrait être codé "10011001100", ou bien "1111111" être codé en "1010110001" afin de réduire les erreurs, améliorer la détection des bits de données et limiter l'énergie transmise sur le support (si on utilise le codage Manchester pour envoyer des paquets de 1, la tension ne cesserait de monter). Voir par exemple le groupe de code "4B/5B".
| Bande passante et débit | ⇒-Bande passante : la quantité d'information pouvant circuler d'en endroit à un autre pendant un instant donné. Se mesure en Kbits/s, Mbits/s, Gbits/s... Un octet valant 8 bits, 1Mo/s=8Mbit/s. -Débit : mesure du transfert de bit à un moment donné. Le débit se dégrade en fonction du nombre de périphériques utilisants le support, le type de trafic... S'il y a plusieurs segments réseau, le débit ne pourra pas dépasser le plus lent de ces segments. La bande passante est la largeur du tuyeau où passent les paquets. C'est la vitesse maximale théorique de transfert des informations. Le débit est la vitesse réelle. -Débit applicatif : calcule le transfert de données utilisables, c'est à dire le débit des données une fois qu'elles sont désencapsulées des multiples couches, sans prendre non plus en compte les accusés de reception, et les processus d'établissement de connexion. Trop d'encapsulation peut grandement réduire le débit applicatif (20% par exemple). La latence est le temps nécessaire pour parcourir la distance d'un point A à un point B (peu d'influence sur le téléchargement, influence le jeu en ligne, la transmisison de voix et de vidéo). |
Materiel réseau
| Cables | ⇒ | Choisir les câbles en fonction de la bande passante, du débit, du coût. Installation couteuse mais peu de maintenance. Le filaire est plus sécurisé que le sans fil (car n'importe qui peut capter les données radios). Il vaut parfois mieux choisir du matériel surdimensionné pour réduire le coût lors d'évolutions futures. Câblage vertical/backbone/rocade : Utilisé pour interconnexion réseau ou connecter différents bâtiments entre eux. Entre les étages (d'où le terme de vertical). Câblage horizontal : Dans les plénums, lien entre les salles de télécommunications et chaque connecteur individuel dans les bureaux. Câblage horizontal : des armoires de répartition aux zones de travail (PC utilisateur). |
| Cables Coaxiaux | ⇒ | Cuivre ou aluminium, pour les sociétés de TV. Données sous formes de signaux électriques, plus résistants que les câbles UTC (Unshielded Twisted Pair, paires torsadées non-blindées) grâce à leur blindage permettant un meilleur rapport signal/bruit et donc de transporter d'avantage de données. Un seul conducteur cuivre au centre du câble, isolé par du plastique, dans un blindage en cuivre tressé, dans une gaine. Le connecteur central est l'axe, les autres éléments l'entourent : on parle donc de câble "coaxial". Progressivement abandonnés car chers et difficiles à réparer contrairement à un câble UTP. Normes utilisant un cable coaxial : Ethernet épais (Thicknet), "10BASE5", 10Mbit/s, longueur maximum de 500m. Ethernet fin (Thinnet), 10BASE2, 10Mbit/s, longueur maximum de 185m. Thicknet et Thinnet sont les premiers supports pour ethernet (néanmoins non-valable d'après la norme 802.3). Types de câbles : RG-59, pour la TV par câble aux USA. RG-6, meilleure quealité que le RG-59. Pas de bande passante maximale pour les câbles coaxiaux, dépend du type de signal utilisé. Connectique : "Type F" (bout en métal qui se visse) Type BNC (à baïonnette, pour un usage militaire). |
| Câbles à paires torsadées | ⇒ | Utilisés pour la téléphonie et Ethernet. Fils de cuivre recouverts d'un plastique isolant coloré. Ces fils sont eux-mêmes dans une gaine. La torsade permet d'éviter les interférences extérieures, le courant électrique circule en circuit dans 2 fils ayant des champs magnétiques opposés, "effet d'annulation" évitant les interférences. Lors d'une interférence, le récepteur la traite de manière égale mais opposé, donc annulation. Permet aussi d'éviter la diaphonie (interférences internes). 2 types : -Non-blindés (UTP "Unshielded Twisted Pair"), jusqu'à 100m, le plus courant. -Blindé (STP "Shielded.."), chaque paire de fils dans un film métallique pour réduire les interférences. 100m également + doivent être mis à la terre (sinon, jouent le rôle d'antenne). Il existe plusieurs catégories selon le nombre de cables dans le fil et le nombre de torsade. -UTP catégorie 3 : 10Mbit/s à 16MHz. Anciens réseau locaux Ethernet ou ligne téléphonique (en général connecteur RJ11). -UTP catégorie 5 : 100 Mbit/s à 100MHz, normes plus rigoureuses que le 3 (connecteur RJ45) -UTP catégorie 5e : 1000Mbit/s à 100Mhz, d'avantages de torsades pour moins d'interférences. -UTP catégorie 6 : 1000Mbit/s à 250 Mhz, plus de torsades. -UTP catégorie 6a : 1000Mbit/s à 500 Mhz. -ScTP catégorie 7 : "screened twisted pair", 10Gbit/s à 600Mhz, moins flexibles. Les bâtiments neufs sont souvent équipés de câbles UTP reliant les bureaux à un répartiteur central (MDF, Main Distribution Facility). Au delà de la limite de 100m, on utilise un répéteur. Il existe aussi des câbles spéciaux conçus pour circuler dans les plé,ums (faux plafonds) faits d'un plastique spécial pour retarder l'incendie. Il y a 2 schéma de câblage (ordre des fils en sortie) T568A et T568B. Les fils sont numérotés de gauche à droite, clip vers le dessous, câble vers le bas. T568A : 1+2=vert ; 3+6=orange ; 4+5=bleu ; 7+8=marron. (vert et orange inversé par rapport au B). T568B : 1+2=orange ; 3+6=vert ; 4+5=bleu ; 7+8=marron. ("On Va Bien Manger"). Si un connecteur est mal branché, il peut se produire une perte de signal. -Câble droit : même schéma de câblage des 2 côtés. Un câble droit est utilisé entre 2 appareils différents, par exemple de PC à switch. On utilise généralement T568B des 2 côtés. Attention à l'exception, entre un routeur et un PC on a un câble croisé (assez rare d'avoir cette configuration, généralement on a routeur---switch---pc). -Câble croisé : 2 schéma de câblage différents selon les côtés, s'utilise lorsqu'on veut brancher un switch à un autre switch, ou de PC à PC. Certains périphériques détectent les broches et peuvent s'adapter (fonctionner avec droit comme croisé dans la même situation). Ces schémas sont définis dans les normes TIA/EIA-568 (qui définit les types de câbles, les méthodes de test, les connecteurs, etc). Un nouveau schéma, T568C, vise à remplacer T568B. Se teste avec un multimètre réseau. |
http://en.wikipedia.org/wiki/Rollover_cable|Plus d'info
| Câbles renversement Cisco | ⇒ | Câble bleu ^propriétaire cisco se branchant d'un côté sur le port série d'un PC, de l'autre au port console type RJ45 d'un routeur. Appelé "renversement" ou "rollover cable". Les branchement sont opposé d'un côté par rapport à l'autre. On peut aussi les brancher sur le port AUX d'un cisco (mais moins de messages de debug sont affichés par défaut, les ports AUX servent aussi à travers un modem).Plus d'info |
| Fibre optique | ⇒ | Support en verre ou plastique transmettant des infos via la lumière. Pas effecté par les perturbations électromagnétiques ou radio. Signaux convertis en impulsions lumineuses par laser ou LED. Plusieurs km de distance. Peut atteindre 100GBit/s. Vitesse limitée par les périphériques et les impuretés intérieures au câble. A l'arrivée, des photodiodes détectent la lumière qui est reconvertie en données. Plus couteux que le cuivre. Connecteurs : SC (Suscriber Connector, emboût avec un bouton pression qui s'enclenche en poussant, embout de 2,5mm), ST (Straight Tip, baïonette à ressort), LC (Lucent Cnnector, bouton pression, embout de 1,25mm). 2 types de cables : Multimode (plus facile à produire, peut utiliser LED, plusieurs rayons de lumière, fonctionne sur 2km à cause de la distorsion modale -les différents rayons se déforment) et monomode (100km, utilise lasers). On utilise un réflectomètre optique pour tester la fibre. On peut aussi vérifier si la lumière traverse d'un bout à l'autre avec une lampe de poche. |
| Technologies de fréquence | ⇒ | 10BASE-T : 10 Mbits/s en bande de base (Baseband, technique de transmission du signal), cable croisé catégorie 3, sur 100m. 100BASE-TX : cat5, 100Mb/s, sur 100m. 100BASE-FX : 100Mb/s, Fibre multimode, helf duplex sur 400m, full duplex sur 2km et 200Mb/s. 1000BASE-T : cat 5 et 6, 1Gbit/s, sur 100m. 1000BASE-CX : 1GB/s, STP (câble blindé), 25 m. 1000BASE-T : 1GB/s, UTP (cat5 et sup), 100m. 1000BASE-SX : 1GB/s, fibre multimode, 550m. 1000BASE-LX : multimode sur 550m, monomode sur 10km. 10GBASE-ZR : 10Gb/s, fibre monomode sur 80km. 10G BASE-T : Cat6a et 7, 10Gbit/s, sur 100m. On parle de "Fast Ethernet" pour 100Mb/s, de Gigabit Ethernet au delà. |
LLDP (Link Layer Discovery Protocol )
Le matériel réseau peut s'échanger des informations avec le protocole LLDP. Pour connaitre le numéro du port et le nom du routeur sur lequel on est branché, lancer wireshark et filtrer en utilisant "lldp" ou un programme du type haneWIN LLDP Agent. Peut poser des risques de sécurité (trop d'infos diffusée ou construction de faux paquets LLDP par un pirate).
Hub
Attention : lorsqu'on parle de "port" ci-dessous, on parle de port physique, c'est à dire là où se branchent les cables RJ45. Ce ne sont pas les ports logiciel (port HTTP, port Telnet...).
Un concentrateur (ou HUB) renvoie les données reçues sur un port à tous les autres ports. Il peut aussi servir de répéteur pour augmenter la puissance du signal. De moins en moins utilisé car il ne segmente pas le trafic donc diminuent la bande passante disponible. Le débit du HUB est le débit divisé par le nombre de ports. Pas de mémoire, moins cher. Un PC connecté à un HUB verra tout le trafic entre tous les PC.
Cela pose des problèmes d'encombrement du réseau, les PC sont tous dans le même "domaine de collision" (ils se gênent quand ils communiquent). Un seul PC peut communiquer à la fois.
Pont
On appelle pont de "niveau 1" (niveau 1 de la couche OSI) un adaptateur entre 2 supports différents, par exemple un adaptateur fibre à CPL, ou un convertisseur Fast Ethernet / Fibre optique. Il ne s'intéresse pas aux protocoles de couche 1.
Possède donc 2 ports.
Un pont de niveau 2, ou "pont éthernet", est une frontière entre un segment de réseau physique et un autre. Ne diffuse pas une trame si il voit qu'elle n'est pas destinée à une adresse mac connue branchée à un de ses ports.
Un pont permet de partager un domaine de collision en 2 (par contre, il ne sépare pas les domaines de broadcast).
Il peut lire les informations ethernet mais pas les modifier.
Très répandu dans les réseaux sans fil.
Switch
Ou "commutateurs".
On peut considérer un switch comme un "pont multiport" (donc niveau 2 de la couche OSI). Il sait lire les paquets et déterminer sur quel port renvoyer une trame selon son adresse MAC.
Il encombre moins le réseau qu'un Hub car sépare les domaines de collisions. Il utilise les adresses MAC pour diriger les données.
Pour savoir sur quels ports sont quels MAC, il écoute les trames (mémorise que telle adresse mac vient d'arriver sur tel port). Quand il ne sait pas où renvoyer une trame, il la renvoie sur tout ses ports avec une machine connectée (LED allumée) sauf celui d'entrée pour éviter les boucles.
Des boucles infinies peuvent néanmoins de former si les commutateurs sont reliés entre eux par de multiples liaisons (redondance) : le switch A envoie à tous ses ports sauf celui où il a reçu, le B fait de même, le C aussi... et la trame revient au A. On parle de "tempête de broadcast" quand cette situation empêche le réseau de fonctionner. utiliser le protocole STP (Spanning Tree Protocol) pour éviter les boucles.
Un switch a besoin de mémoire pour faire une table de correspondance mac/port (en général on parle de mémoire CAM, "mémoire adressable par contenu"). On appelle cette table "table de commutation" ou "table de pont" ou encore "table MAC", elle peut être commune à tous les ports ou bien chaque port entrant peut avoir sa mémoire réservée.
show mac-address-table pour l'afficher sous Cisco IOS ("Cisco Internetwork Operating System", le système d'exploitation du matériel cisco). Un compte à rebours est lancé pour chaque adresse MAC dans la table, après un certain temps (variable selon la mémoire la machine), elle est effacée. On peut aussi renseigner cette table de façon statique (mac-address-table static adresse_MAC vlan de_1_a_4096_ou_ALL interface id_interface chez cisco), voir même n'autoriser que certaines adresses mac (switchport port-security adresse_mac_a_autoriser). Chez Cisco les actions à entreprendre se définissent par protect (protège en n'acheminant pas) / restrict (+laisse un message dans les logs) / shutdown (+arrêt total du port) avec switchport port-security violation shutdown par exemple.Une attaque courante consiste à inonder un switch de fausses adresses MAC : le pirate va envoyer un maximum de fausses adresse mac au switch, ce qui va remplir sa table et lui faire oublier sur quels ports sont branchées les vraies machines. Le switch est alors forcé d'émettre ses paquets sur tous les ports pour les retrouver. En émettant sur tous les ports, il devient alors aussi transparent qu'un HUB, ce qui permet au pirate de lire les paquets.
Il utilise aussi sa mémoire pour réaliser une opération de commutation dite "store and forward" (stockage et retransmission) : il retient la trame envoyée, recalcule son checksum pour voir si elle contient des erreurs (Frame Check Sequence, FCS) puis l'envoie au port correspondant à la MAC du périphérique désigné. Si plusieurs trames doivent être envoyée au même port, il les envoie les unes après les autres.
Certains switchs ne lisent que l'adresse sans calculer le CRC pour ne pas perdre de temps (commutation "cut-through fast forward"). Ils transmettent plus rapidement mais envoient parfois des trames endommagées sur le réseau, qui seront ignorées par la carte réseau à l'arrivé. Il existe une méthode un peu entre les deux, "cut-through fragment-free", qui vérifie uniquement les 64 premiers octets de la trame car c'est souvent là que sont les erreurs. Un switch peut également combiner ces méthodes, et s'adapter selon un seuil d'erreur défini.
Utiliser un switch à la place d'un hub permet de partager le domaine de collision en autant de ports que comporte le switch. En effet, si un PC est connecté à un switch, sur le support qui va jusqu'au PC n'arrivent que des informations destinées à ce PC.
Il ne filtre pas les domaines de diffusion (domaines de broadcast). Un switch enverra un broadcast sur tous ses ports (excepté le port d'origine du broadcast) : si le switch est branché à un autre switch, ce dernier enverra lui aussi un broadcast sur tous ses ports (excepté le port d'origine du broadcast). Un routeur ou la mise en place de VLAN permet de limiter les domaines de diffusion. Schéma explicatif
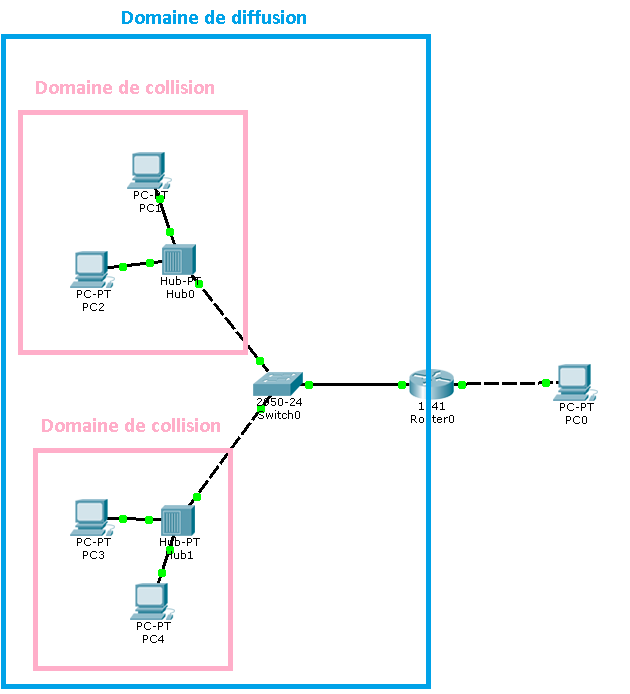{kind=link}
S'il est full-duplex, c'est à dire que le support peut émettre et renvoyer en même temps (il utilise 2 paires de fils, une paire pour envoyer et une pour recevoir -il faut au minimum une paire de fil pour fonctionner pour établir un courant, un half-duplex utilise une paire, un full-duplex 2 paires), il n'y a plus du tout de problème de collision car les données "aller" ne circulent pas sur la même paire que les données "retour". On parle aussi de "communication bidirectionnelle simultanée".
Un commutateur peut bloquer une trame si le FCS n'est pas bon, si elle est incomplète ou selon des règles programmées.
A noter que certains switch peut opérer au niveau 3 de la couche OSI (couche réseau) s'il analyse les paquets pour faire de la QoS ou des ACL. Même si c'est assez contre-intuitif, il est possible de donner une addresse IP à certain switchs pour les gérer à distance.
Choisir un switch
Au niveau des coûts, considérer qu'il peut être moins couteux et plus efficace de prendre plusieurs commutateur qu'un seul gros. Plusieurs commutateurs permettent d'avoir de la redondance (plusieurs chemins d'un PC à un autre, passant par des switchs différents), mais il faut prendre en compte qu'il faut
La plupart des commutateurs peuvent s'empiler sur un rack (chassis), leur hauteur est indiqué en "rack unit". Il existe des commutateurs de configuration fixe, d'autres modulaires (qui viennent avec leur propre chassis qur lesquels on rajoute des options). Il existe également des "Commutateurs empilables", qui se connectent entre eux pour fonctionner comme un seul gros switch.
Pour une même taille, deux switchs peuvent avoir une densité de ports différentes (24 ports contre 48 par exemple).
Forwarding Rates/debit de transfert/Capacité de commutation : la quantité maximale de données par secondes pouvant être traitées par le switch. Un switch gigabit 24 ports devra pouvoir traiter 48 Gbits/s en mode bidirectionnel simultané. Si son débit de transfert est de 12 Gbits/s il ne pourra pas fonctionner avec tous ses ports en gigabit. C'est un point important à prendre en compte. Il existe aussi la notion de "fond de panier" pour indiquer la vitesse du bus principal Sur cette page les 2 termes sont utilisés. On peut privilégier un port par rapport à un autre (par exemple donner 1 Gbits/s sur le port d'un serveur et 100 Mbits/s pour les clients, "commutation asymétrique").
Un switch peut également envoyer du courant (Power over Ethernet, PoE, 48 V de tension) pour alimenter un téléphone, une caméra ou un point d'accès sans fil.
STP (Spanning Tree Protocol)
Bonnes infos sur STP
802.1D.
STP garantit un chemin unique entre plusieurs switch en bloquant les chemins redondants. Lorsqu'un port est bloqué par STP, rien ne passe sauf les paquets STP, les BDPU (Briged Protocol Data Unit).
Utilise l'algorithme "Spanning Tree" : un commutateur est élu comme base, comme "pont racine" (choisi avec son adresse mac, une valeur de priorité et éventuellement un ID système) puis le protocole calcule pour toutes les destination un chemin vers le pont racine. Il est recommandé de choisir soit même le pont racine en donnant une valeur de priorité basse à un switch pour éviter que ça ne soit décidé avec l'adresse mac. Les ports des autres commutateurs ayant un coût moindre vers ce pont racine sont les "ports racines" (un seul port racine par commutateur). Les ports qui ne sont pas des ports racines et qui acheminent du trafic, ou qui sont sur le pont racine, sont les "ports désignés" (un seul port désigné par lien). Enfin, les ports n'acheminant pas de trafic sont les "ports non désignés".
Au départ, tous les ports sont bloqués pendant 20 secondes pour éviter une boucle avant l'élection du pont racine, chaque commutateur s'identifie comme pont racine en envoyant toutes les deux secondes (hello time) un paquet contenant son id, l'id de pont racine et le coût vers la racine. S'il reçoit un paquet avec un pont racine inférieur, il changera le contenu de son paquet pour y mettre ce nouvel id. Au final, l'ID le plus faible devient le pont racine.
On peut forcer un commutateur à être pont racine sur les cisco avec la commande
spanning-tree vlan id_de_vlan root primary : sa priorité deviendra 24 576, et si une valeur inférieur est détectée sur le réseau, elle se définira à 4 096 en dessous de cette valeur. On peut forcer un pont racine secondaire avec spanning-tree vlan id_de_vlan root secondary (en cas de panne du premier). Alternativement, on peut faire spanning-tree vlan id_de_vlan priority valeur_de_priorité (avec une valeur entre 0 et 65 536 par palier de 4 096.Le coût d'un chemin est calculé d'après le nombre de ports traversés et la vitesse de chacun, STP prend le chemin le moins coûteux. Plus la vitesse du port est haute, moins il est coûteux. Le système de coût a été révisé : autrefois, un port avec une vitesse de plus de 100 Mbits/s valait 1, 100 Mbits/s valait 10, 10Mbits/s valait 100. Désormais, un port 10 GBits/s vaut 2, 1Gbits/s vaut 4, 100Mbits/s vaut 19, 10Mbit/s vaut 100. On peut configurer manuellement le coût d'une interface en mode config-if avec la commande
spanning tree cost 123 (pour donner un coût de 123). show spanning-tree detail pour afficher tous les coûts. Si deux ports ont le même coût, leur id est utlisé, ainsi que la valeur de priorité qui peut être configuré avec spanning-tree port-priority valeur_de_priorité. Sinon, se base sur l'adresse mac.Un switch stocke les infos d'un paquet BDPU selon un timer "Max Age" de 20 secondes. Au bout de ces 20 secondes, sans nouveau BDPU reçu, un nouveau processus d'élection est lancé.
Les ports passent par 4 étapes :
Blocage, n'achemine rien sauf les trames BDPU. Ecoute, se prépare à acheminer, prévient autours de lui (reste 15 secondes dans cet état de "forward delay"). Apprentissage, apprend les adresses mac (reste également 15 secondes dans cet été de "forward delay"). Acheminement, où il fonctionne pleinement. La technologie PortFast de Cisco permet de ne pas passer par l'état d'apprentissage ou d'écoute (s'utilise sur les ports d'accès)
spanning-tree portfast.Le STP a été optimisé pour un réseau de diamètre de 7 switchs. On peut changer le diamètre avec la commande
spanning-tree vlan ID_de_réseau_local root primary diameterEn cas de changement de topologie, un paquet TCN (Topology Change Notification) est envoyé par le commutateur concerné et le timer "max age" tombe à 15 secondes.
Protocoles similaires
Rapid spanning tree protocol (RSTP), reprend certaines idées du rapide PVST+ pour convergence plus rapide. La nouvelle norme qui remplace STP. N'utilise pas de minuteurs, convergences très rapides. Introduit la notion de "Ports d’extrémité", des ports qui ne sont pas reliés à un switch mais à un hôte. Les ports n'étant pas des ports d'extrémités sont des liasons point à point (périphérique à un autre) ou partagée (avec un hub). Les états "blocage" et "écoute" ont été fusionnés dans un état "mise à l'écart".
Per-VLAN spanning tree protocol, qui génère un arbre pour chaque VLAN, PVST+ qui prend en charge l'aggrégation 8021.Q (et non plus uniquement ISL comme son prédécesseur), rapid PVST+ avec des technologies telles que portfast pour une convergence plus rapide.
spanning-tree mode rapid-pvst.Multiple STP (MSTP), associe plusieurs réseaux virtuels à la même instance d'arbre, moins de spanning tree nécessaire.
Routeur
Un routeur fait transiter les paquets d'une interface réseau vers une autre selon des règles. Les routeurs travaillent avec le protocole IP. Ils sont souvent des passerelles d'un réseau vers un autre. Ils peuvent lire et modifier les informations de couche 2 (Ethernet, ils y changent notamment les adresses MAC). Il peut lire les informations de couche 3 (ip) mais ne modifie pas les adresses, sauf s'il s'agit d'un routeur doté de fonctions avancées comme un système de pare-feu ou un NAT (un NAT peut lire/modifier les couches supérieures à 3, on parle de passerelle applicative, "application layer gateway").
Un routeur modifie toutefois dans le paquet IP le champ "TTL".
A chaque routeur traversé, le TTL (Time To Live) d'un paquet ip diminue de 1. Lorsqu'un routeur reçoit un paquet avec un TTL de 1, il le décrémente, le détruit et renvoie un paquet "Temps dépassé" (schéma), ceci afin d'éviter d'avoir un paquet qui tourne indéfiniment en rond.
Un routeur peut servir à connecter des réseaux utilisant différentes technologies. On peut par exemple ajouter une carte ADSL ou une carte fibre à un routeur, pour connecter un réseau local (les PC d'une habitation) à un réseau étendu (WAN, à son FAI).
Lorsqu'un réseau n'est atteignable que par une seule route (un seul routeur dans ce réseau), on parle de "réseau d’extrémité".
ARP
ARP (address resolution protocol) permet d'associer une ip à une adresse mac.
Requète ARP
Une requête ARP sert à récupérer une adresse MAC selon une ip.
Un PC demande à tous les autres PC si leur IP est celle voulue. Sans réponse à sa requête, un PC enverra alors le paquet à sa passerelle.
Le résultat des requêtes ARP est stocké dans la table ARP,
arp -a sous windows, show arp sous cisco. On peut aussi ajouter manuellement des entrées (qui n'exprirent jamais) dans la table ARP, ou en supprimer. Les entrées sont stockées 2 minutes, 10 minutes si cette entrée réapparait, sur windows. Il n'y a pas de commande pour exécuter une requête ARP, elle se fait automatiquement (lié au protocole IPV4).Un nombre important de périphériques faisant une requête ARP (allumer un groupe de PC qui veulent trouver la MAC de leur passerelle par exemple) peut ralentir le réseau pendant un bref instant.
Empoisonnement ARP : Un pirate peut émettre continuellement des fausses réponses à une requête ARP pour que lorsqu'une machine cible fasse une requête ARP, elle reçoive la réponse du pirate. La machine victime communiquera avec le pirate en pensant que son ip est celle voulue. Une table ARP avec des adresses fixes permet d'éviter un empoisonnement.
Un routeur bloque les requêtes ARP entre 2 réseaux, sauf si il est configuré pour agir en tant que proxy ARP (un proxy ARP répond en utilisant l'adresse MAC d'une de ses propre interfaces, il se fait "passer" pour le périphérique au delà).
Adresse à une interface (Cisco)
Pour donner une adresse à une patte sur un routeur cisco :
-"enable" (rentrer dansle routeur en tant qu'admin)
-"conf t" ("configure terminal", configurer le routeur)
-"interface f0/0" (configure la patte fast ethernet 0/0)
-"ip address 1.2.3.4 255.0.0.0".
On peut aussi définir des adresses de loopback, en utilisant "lo1", "lo2", "lo3" etc. par exemple
int lo1, ip address 1.2.3.4 255.0.0.0.D'un réseau à un autre
Un hôte ne peut pas connaitre les adresses de toutes les machines existantes. Lorsqu'il ne connait pas une adresse, il demande à sa passerelle, un routeur.
Exemple :
A[10.0.0.1] --- [10.0.0.2]B[11.0.0.1]
La machine A veut aller sur le réseau distant 11.0.0.1 qu'elle ne connait pas, elle interroge le routeur B qui est sa passerelle par défaut : le routeur connait ce réseau, car il est connecté directement dessus. Il va modifier dans la trame l'adresse mac de l'expéditeur et la remplacer par la sienne, puis va envoyer la trame vers l'autre réseau.
Plutôt que d'utiliser toujours la même machine pour atteindre un réseau inconnu, on peut aussi indiquer que pour aller à tel réseau, il faudra utiliser telle machine : c'est ce qu'on appelle une route. Dans la mémoire de B (sa "table de routage") est inscrit la route vers 12.0.0.0 : "pour aller au réseau 12.0.0.0, il faut passer par C".
[10.0.0.2]B[11.0.0.1] --- [11.0.0.2]C[12.0.0.1]
Bien penser qu'un paquet peut réussir à faire le chemin de B vers C mais ne réussira pas forcément le chemin inverse. Dans l'exemple ci-dessus, il faut ajouter une route à B mais aussi à C pour qu'un paquet puisse faire l'aller-retour.
Un périphérique ajoute automatiquement à sa table de routage les réseaux sur lesquels il est directement connecté. Les routes peuvent être ajoutés manuellement ("routage statique", pour les petits réseaux, difficile à maintenir, risques d'erreurs) ou échangées de façon automatique entre les routeurs ("routage dynamique" : protocoles RIP, IRGP, OSPF... moins sécurisé car échanges d'infos entre les routeurs, plus facile à mettre en place, utilise ressources système et réseau). Certains routeurs ont une table de routage indiquant plusieurs centaines de milliers de réseaux.
En résumé :
-Le routeur supprime l'encapsulation de la couche 2 (adresse mac).
-Il lit l'adresse de la couche 3 (ip) et regarde s'il connait une route vers le réseau.
-Il met sa propre adresse mac et envoie le paquet.
Une passerelle est donc simplement une route par défaut (on parle aussi de route vers le réseau 0.0.0.0). Il est possible de donner une route par défaut à un routeur, pour lui dire par exemple "si tu dois atteindre un réseau inconnu, passe par tel routeur" ou "si réseau inconnu, envoie via ton interface ADSL".
Il peut exister plusieurs routes pour suivre un même chemin. On privilégiera tout d'abord les routes les plus précises : pour aller à 1.2.3.4 on prendra la route 1.2.3.0 avant la route 1.2.0.0.
Si 2 routes sont identiques, on utilisera alors un chiffre, la métrique. Selon les protocoles, la métrique peut prendre en compte le nombre de routeur à traverser, la bande passante, le coût (valeur que met un administrateur pour privilégier une route), la fiabilité, la charge... La route avec la métrique la plus basse est privilégiée.
Il existe aussi une autre valeur, la distance administrative, qui compare plusieurs protocoles entre eux. Par exemple, une route statique, entrée manuellement par un administrateur, aura une distance administrative plus basse qu'une route envoyée par un routeur inconnu. Seul un réseau directement connecté possède une distance administrative de 0. La valeur de la distance administrative de toute route statique (y compris les routes connectées à une interface) est de 1. Une route avec une distance administrative de 255 ne sera jamais utilisée par le routeur (elle sera absente de la table).
show ip protocols pour afficher la distance administrative d'un protocole sous cisco IOS.Par exemple, dans cette route statique, la métrique est de 0, la distance administrative à 1.
S 192.168.1.0/24 [1/0] via 192.168.3.105Dans le cas où il y a deux routes strictement identiques, un routeur divise équitablement les paquets entre les 2 routes, pour ne pas en surcharger une. On parle "d'équilibrage de charge à coût égal" (il existe aussi, avec les protcoles EIGRP et IGRP, "l'équilibrage de charge à coût inégal", diviser les paquets non-équitablement entre 2 routes avec la commande
variance).On peut aussi programmer une route, avec une métrique volontairement assez forte pour qu'elle ne soit pas utilisée en première. Elle ne sera utilisée que si la route habituelle disparait (par exemple, l'interface passe down), on parle de "Routes statiques flottantes".
Si un routeur n'a pas de route vers le réseau demandé ni de passerelle par défaut, il détruit simplement le paquet.
EGP et IGP
Pour interconnecter 2 réseaux utilisant des protocoles de routage différents( ex: RIP et IGRP), on utilise un protocole EGP (Exterior Gateway Protocol, par ex BGP), dit "protocole à vecteur de chemin". S'oppose aux Interior Gateway Protocol (RIP, IGRP, EIGRP, OSPF, IS-IS...).
Il existe 2 types de protocoles IGP :
| Protocoles de routage à vecteur de distance | ⇒ | Les machines envoient de façon périodique le contenu de leurs tables de routage à leur voisin. Elles ne connaissent donc que la table de routage de leur voisin et rien d'autre. En cas de problème (un appareil ne répond plus), l'information n'est reçu qu'après une certaine période (par contre s'il s'agit d'un cable débranché l'information est envoyé tout de suite par la machine qui a eu son câble débranché). La convergence du réseau (lorsque les tables de routages sont toutes à jours) est plus longue que sur un protocole à état de lien. Des boucles de routages peuvent se produire si les tables ne sont pas cohérentes entre elles. Exemple : RIP, IGRP et EIGRP (un peu une exception a des fonctions avancées pour faire une convergence rapide, n'envoie pas sa table entière et n'envoie qu'en cas de modifications). Les routeurs n'ont pas de vision d'ensemble, ils ne reçoivent que les informations de leur voisin. On parle parfois de "routage par rumeurs". Le processus : le routeur regarde ses interfaces directement connectées. Il ajoute 1 à la métrique et diffuse les infos aux routeurs voisins. -A l'allumage, il voit les réseaux directement connectées, métrique 0. Il ajoute 1 et envoie aux voisins. -Il reçoit les infos de son voisin. -Il rajoute 1 en envoie aux voisins (sauf à ceux de l'interface d'où il a reçu le message, technique de split horizon : ne pas envoyer des infos sur le port par lequel on a reçu ces mêmes infos). Il peut arriver qu'un routeur envoie une route correcte alors qu'elle ne l'est pas car il n'a pas encore reçu l'information. Un paquet peut alors faire des aller-retours jusqu'à épuisement de son TTL, on parle de boucle de routage. Différentes techniques permettent d'éviter des cas où se feraient des boucles de routage, telles que split horizon, ou la définition d'une métrique maximum (exemple : A reçoit une route avec une métrique de 2, l'envoie à B, B l'envoie à A avec une métrique de 3, A renvoie cette même route avec une métrique de 4... ça pourrait se faire à l'infini si avec RIP on était pas limité à 16). Il existe aussi la technique de "l'empoisonnement de routage" : si une route est non fonctionnelle, on passe la métrique à 16 (c'est ce qui est désigné comme "empoisonnement") et envoie l'info aux voisins. Enfin, existe la technique du "découpage d’horizon avec antipoison". Dans le réseau A---B---C, mettons que le lien vers C soit coupé. B envoie la route vers C empoisonnée (métrique de 16) à A. A renvoie aussitôt la route à B (c'est une exception au split horizon) pour éviter certaines boucles Plus d'infos. |
| Protocoles de routage à état de liens | ⇒ | Chaque machine à une vue de l'ensemble du réseau, et pas seulement des tables de son voisin (demande plus de mémoire). La construction de la topologie demande du temps processeur. Une mise à jour se fait dès qu'un lien change d'état, la convergence est donc rapide, mais ils inondent le réseau avec les infos concernant leurs réseaux directement connectés donc peut prendre de la bande passante si les états changent souvent. Pour les réseaux conçus de manière hiérarchique. En outre, un routeur ayant connaissance de l'ensemble du réseau, il peut choisir le meilleur chemin pour atteindre sa destination. En anglais "Shortest Path First", "SPF protocols". Ils utilisent en général l'algorithme Dijkstra (appelé parfois algorithme SPF), où chaque routeur détermine lui même le coût pour accéder lui-même à un autre. Le routeur qui veut s'y rendre fait la somme des coûts entre les routeurs. Bon article et schéma simple, Schéma et plus d'infos sur wikipedia. "Lien" dans "état de lien" désigne une interface du routeur. 1)Un routeur prend connaissance des réseaux directement connectés ; 2)Ils détectent leurs voisins en envoyant un paquet Hello ; 3)Il envoie à tous ses voisins l'état de ses liens (en donnant un coût à chacun, "Link State Packet", précisant la présence de voisins, le type de réseau...), qui stockent l'info dans leur base ("base de données d'état de liaison") et relaient le emssage à leurs propres voisins (excepté l'interface de réception). ; 4)Une topologie complète du réseau est créée dans chaque routeur. Une fois ces étapes faites, en théorie un routeur a état de lien ne devrait envoyer de nouveaux paquets LSP qu'en cas de changement dans leurs états de lien. Le résumé topologie d'un groupe de routeur est appelé une "zone" ("area"), ce concept avancé peut servir à définir des hiérarchies, faire des résumés de routage, éviter de surcharger des routeurs trop lointain qui n'ont pas d'intérêt à connaitre la hiérarchie exacte d'un réseau distant. Exemple : OSPF (Open Shortest Path First), IS-IS (créé par ISO, Intermediate-System-to-Intermediate-System). |
| Résumé de routage (ou "résumé de réseau", ou "agrégation de préfixes") | ⇒ | Plutôt que de faire une route vers "12.1.2.0/24", "12.1.3.0/24", "12.1.4.0/24... on peut faire une seule route vers "12.1.0.0/16" car ils sont "contigus". Pour les calculer, transformer les adresses réseaux en binaire et prendre les bits qui sont identiques. Exemple : |
On peut diffuser une route statique via un protocole à route dynamique avec la commande
redistribute static sous cisco. Si le protocole dynamique ne prend pas en charge les VLSM, le masque ne sera pas distribué.Route statique (cisco)
En mode de configuration du terminal (conf t) :
ip route 12.1.2.0 255.255.255.0 10.0.0.1 (réseau_à_atteindre masque ip_du_prochain_routeur)Au lieu de l'ip du prochain routeur, on peut aussi utiliser directement le nom d'une interface, par exemple "Dialer1" ou "Serial0/0/0" lorsqu'on a une connexion point à point. En ethernet, il peut y avoir plusieurs périphériques accessibles par l'interface, donc on doit préciser une ip. Pour éviter que le routeur ne lise l'ip de la passerelle puis chercher à quelle interface elle est directemenbt connectée (recherche récursive), on peut utiliser la commande
ip route 12.1.2.0 255.255.255.0 fastethernet 0/1 10.0.0.1.On peut aussi utiliser l'adresse "Null0", qui est une interface qui ne mène nulle part. les paquets seront détruits.
ip route 12.1.2.0 255.255.255.0 null0Si l'interface qu'utilise une route statique est désactivée, la route disparaitra dans
show ip route, mais elle sera toujours présente dans le fichier de configuration et réapparaitra dès que l'interface est de nouveau active.Impossible de modifier une route statique, il faut la supprimer en ajoutant "no" devant la commande, par exemple
no ip route 12.1.2.0 255.255.255.0, puis créer une nouvelle route.Pour faire une route par défaut :
ip route 0.0.0.0 0.0.0.0 Serial0/0/0Voir les routes
-Cisco :
show ip route (ou show run pour voir le routes statiques)-Windows/linux/MacOS :
netstat -r (ou route print sous windows)RIP
Protocole de routage à vecteur de distance créé en 1988 qui utilise le nombre de sauts entre chaque routeurs pour la métrique. Nombre de saut maximum : 15. Fonctionne par classe IP (sans VLSM, les masques de sous-réseau de longueur variable) via le protocole UDP (port 520). Utilise le découpage d'horizon et découpage d'horizon avec antipoison. S'appuie sur l'algorithme Bellman-Ford.
Mises à jour envoyées aux voisins toutes les 30 secondes ("minuteur de mise à jour") via broadcast (255.255.255.255, risque de sécurité) ou lors d'évènements tels que la réception d'une nouvelle route, une interface se désactivant, une route devient inaccessible. Lorsqu'un routeur démarre, il va faire une requête aux routeurs adjacents pour récupérer les tables (indique 1 dans le champ "commande" du paquet RIP).
Si une mise à jour n'est pas reçue après 180 secondes la route est indiquée non-valide ("minuteur de temporisation", métrique passe à 16). Après 60 secondes de plus sans réponse, elle est effacée ("minuteur d'annulation"). Pour voir le temps écoulé depuis la dernière mise à jour,
show ip route ou show ip protocols.Lorsqu'un routeur reçoit l'information d'une route désactivée, il lance un "minuteur de mise hors service" : il ignorera les infos des autres routeurs avec une métrique supérieur qui lui disent (de façon erronée) que le réseau n'est pas désactivé. Par contre, si un routeur avec une métrique inférieure (donc plus proche de la panne) lui dit que la panne est résolue, il l'écoutera.
En résumé :
-Minuteur de mise à jour : 30s.
-Minuteur d'annulation ("invalid timer") : 180s.
-Minuteur de mise hors service ("holddown timer") : 180s.
-Minuteur d'annulation ("flush timer") : 240s.
Les réseaux directement connectés auront une métrique de 0, un réseau inaccessible aura une métrique de 16.
Comme RIPv1 fonctionne sans VLSM, si un réseau utilisé un masque différent de sa classe (par exemple 172.18.1.0/24 et 172.18.2.0/24), RIPv1 fera de lui même un résumé de route en indiquant une route vers 172.18.0.0. Dans le schéma, tous les routeurs utilisent RIP. Les 2 routeurs dans le résumé 172.18.0.0 n'ont pas besoin de RIP pour connaitre les masques de 172.18.1.0, 172.18.2.0 et 172.18.3.0, ils peuvent les déduire tout seul d'après leurs propres masques. Entre ces 2 routeurs les routes 172.18.1.0, 2.0 et 3.0 seront envoyés en rip. Au routeur restant ne sera envoyé qu'une route vers 172.18.0.0. Le routeur entre le "super-réseau" 172.18.0.0 et 10.0.0.0 est appelé "routeur de périphérie".
{kind=link}
La version 2 (RIPv2) a été publiée en 1993, elle prend en charge les VLSM, un système d'authentification, utilise des adresses de multidiffusion et non plus de diffusion, prend en charge le résumé des routes manuelles. Il y a également dans le paquet un champ "route tag" et un champ "Next Hop". Plus d'infos sur ces 2 champs. Un router compatible RIP v1 pourra lire les paquets RIPv2 (il ignorera simplement les champs supplémentaires du paquet -masque, routage et Next Hop.
Il existe une version pour IPV6 développée en 1997, RIPng, utilisant le port UDP 521. Elle ne prend pas en charge l'authentification.
Pour afficher les informations rip reçues (pas forcément appliquée dans la table de routage) :
show ip rip databaseRoutage RIP (cisco)
Beaucoup plus rapide que de configurer des routes statiques, on indique juste les ip des réseaux des pattes du routeurs.
En mode "conf t" :
router rip, network 192.168.10.0, network 192.168.9.0, version 1.On peut aussi utiliser "version 2", ou rien du tout, ou "no version" pour utiliser la 1. La version 2 est plus sécurisée, les paquets listant les réseaux sont chiffrés, elle sais gérer les VLSM et fait un résumé automatique des routes (peut être problématique, un ping sur 2 aboutissant peut être un équilibrage de charge entre 2 routes qu'on croit aller au même réseau alors que non, utiliser
no auto-summary pour désactiver le résumé automatique)."network 192.168.10.0" indique 1)que l'on enverra aux autres routeurs l'information concernant le réseau 192.168.10.0 et 2)que l'on envoie/reçoit des informations rip sur l'interface connectée à cette route. On pourrait vouloir informer les autres routeurs de l'existence de cette route, mais ne pas utiliser RIP sur cette interface, d'où l'existence de la commande, en mode "router rip",
passive-interface eth0. Cette commande empêche une interface d'envoyer des mises à jour RIP.RIPv1 détermine le masque de sous réseau par la classe, donc on pourrait mettre 10.2.3.0, ce il enregistrera 10.0.0.0 dans la running-config.
no router rip pour effacer la configuration du rip.debug ip rip pour afficher les échanges concernant le protocole rip.Les routeurs Cisco ne font pas la mise à jour exactement toutes les 30 secondes, ils utilisent la technique "RIP_JITTER" qui fait varier de 15 à 20% le temps pour éviter que tous les paquets ne soient envoyés en même temps.
Pour diffuser une route par défaut en RIP, utiliser la commande
default-information originate.Distance administrative de 120.
OSPF
Routage à état de lien (Open Shortest Path First).
Conçu par IETF et version 1 publiée en 1989, jamais utilisé en production. Version 2 en 1991, mis à jour en 98.
Envoie un paquet IP en multidiffusion sur 224.0.0.5 (adresse définie par IETF), n° de protocole 89.
Diffuse les informations sur l'état de ses liens en cas de changement dans la topologie, mais aussi toutes les 30 minutes, par sécurité (alors qu'en tant que protocole à état de lien il n'aurait pas besoin). Le paquet contient le type du paquet OSPF (1 hello, 2 DBD -liste abrégée de la base de donnée, 3 LSR -link state request, 4 LSU -Link State Update pour répondre aux LSR et rajouter des infos, 5 LSACK -Acknowledgement d'un LSU), l'ID du routeur source, l'ID de la zone, le masque de réseau, intervalle Hello, priorité du routeur, intervalle du routeur, routeur désigné, BDR, liste des voisins.
Etant un protocole à état de lien, le routeur va tout d'abord envoyer un paquet "Hello" à 224.0.0.5, qui comprend l'ID du routeur, le type du réseau et l'intervalle des paquets Hello (10 secondes en point à point ou accès à segment multiple, 30 secondes pour Frame Relay, X.25, ATM).
L'intervalle "dead" est défini comme 4 fois le temps requis pour envoyer un paquet Hello, s'il est atteint, le lien est déclaré hs.
Ces intervalles se changent (en cas de besoin, doivent être changés sur tous les routeurs) avec les commandes
ip ospf hello-interval secondes et ip ospf dead-interval secondes.Les paquets "LSU" peuvent contenir 11 différents "LSA" (Link-State Advertisement), c'est à dire 11 types de messages concernant les états des liens. Chaque routeur OSPF a une base de donnée contenant ces LSA. Il créé grâce à cette base et l'aide de l'agorithme Dijkstra une arborescence SPF pour fournir à la table de routage les meilleurs chemins vers le réseau.
La distance administrative d'OSPF est de 110. Le protocole est préféré à RIP (120) et ISIS (115) mais pas à IGRP (100) et EIGRP (90).
Pour configurer ospf, deux étapes :
1)
router ospf 1, le "1" représente le numéro local, il n'a pas besoin d'être unique à une zone, il n'a qu'une signification locale, pour permettre aux routeurs d'identifier le processus OSPF avec lequel travailler.2)
network adresse_réseau masque_générique area numéro_de_zone, le masque générique sert à annoncer certains sous réseaux-spécifiques, c'est l'inverse d'un masque réseau, 255.255.255.252 aura pour masque 0.0.0.3. Le numéro de zone permet à différents routeurs de travailler ensemble.Une routeur OSPF a besoin d'un identifiant unique pour être identifié. On peut lui donner un identifiant avec la commande
router-id (nouveauté). Sans identifiant, il prendra l'adresse ip la plus élevée de ses interfaces de bouclage (pratique car ne tombe pas en panne). Sans interface de bouclage, il prendra l'ip la plus élevée de ses interfaces activée (pas besoin qu'elle soit intégrée à OSPF). On peut voir l'identifiant avec les commandes show ip protocols ou show ip ospf interface. L'id du routeur est sélectionnée lors du démarrage d'OSPF, pour changer sa source, faire clear ip ospf process.Pour voir les voisins,
show ip ospf neighbor. Pour que 2 routeurs soient voisins, ils doivent être sur le même réseau, avoir des intervalles Hello identiques, avec le même type de réseau, être sur la même zone, que la commande la commande "network" ait été exécuté sur les 2.Pour débuguer,
show ip protocols (montre id du routeur, du process, de la zone, les routes annoncées, les ip des voisins), show ip ospf (montre id du routeur, du process, de la zone -l'indication "SPF schedule delay" indique le temps de calcul de l'algorithme Dijkstra, pour éviter de calculer en permanence et surcharger le processeur il y a également un délai de 10 secondes), show ip ospf interface (montre les timers Hello et Dead).On peut toujours utiliser la commande
passive-interface eth0 pour qu'une interface ne participe pas à OSPF.Pour sa métrique, le RFC de OSPF n'impose rien. Les routeurs Cisco utilisent la bande passante. La formule est "10 puissance 8 divisé par le nombre de bit/s". Une liaison à 10 000 000 bits/s vaudra donc "10", une liaison à 128 Kbit/s (100 000 000/128 000) vaudra 781, etc. Avec ce calcul, les bandes passantes 100 Mb/s et plus seront toujours à 1, néanmoins, on peut changer la bande passante de référence avec la commande
auto-cost reference-bandwidth 1000 (à faire sur tous les routeurs, plus d'info). Pour voir la bande passante d'une interface utiliser show interface (se change avec bandwidth), pour voir le coût d'une interface utiliser show ip ospf interface (on peut définir manuellement un coût avec la commande ip ospf cost).Pour choisir un chemin, OSPF additionne le coût des routes jusqu'à sa destination. La route avec le coût le plus faible sera choisie.
Sur les réseaux à accès multiple (pas point à point), pour réduire le trafic, un routeur est désigné pour envoyer les mises à jours vers les autres routeurs (Designated Router). Il est associé d'un routeur désigné de sauvegarde (Backup Designated Router) qui prendra sa place en cas de défaillance. Sans ça, si 6 routeurs étaient branchés sur un switchs, ils seraient tous voisins les uns des autres et génèreraient beaucoup de trafic pour la diffusion des paquets LSU. Le routeur avec l'interface avec une priorité la plus élevée devient le DR (en cas d'égalité, l'ID du routeur est utilisé). Le BDR est celui avec la priorité/l'ID le plus élevée après le DR. les autres routeurs sont appelés DROTHER. La sélection se fait dès le démarrage d'OSPF, si on veut qu'un routeur soit désigné comme DR, l'allumer en premier. On peut aussi modifier les priorités de son interface avec la commande
ip ospf priority. En mettant cette priorité à 0 on peut empêcher que ce routeur soit sélectionné comme DR ou BDR.Un routeur en périphérie d'une zone, entre un système autonome OSPF et non-OSPF s'appelle un "Autonomous System Boundary Router".
Routage Cisco
Routage IGRP
Interior Gateway Routing Protocol.
Protocole propriétaire cisco datant de 1985, à vecteur de distance, remplacé par le EIGRP (lui aussi propriétaire).
Plus évolué que le routage RIP, nombre de sauts maximum : 255. Par contre, il s'agit d'un protocole de routage par classe (pas de VLSM). Mises à jours envoyées aux voisins toutes les 90 secondes par défaut (trois fois plus long que RIP).
router eigrp numero_de_systeme_autonome, network 192.168.10.0, network 192.168.9.0La métrique IGRP prend en compte la bande passante, la charge, la fiabilité, le délai (20 000 micro-secondes pour connexion série, 1000 micro-secondes pour ethernet), le temps d'attente.
Utilise lui aussi l'algorithme Bellman-Ford.
Distance administrative de 100.
Routage EIGRP
Enhanced Interior Gateway Routing Protocol.
Protocole propriétaire cisco de 1992, pas de mises à jours régulières des tables de routage : uniquement en cas de changements dans la topologie, seule les informations sur la route concernée sont envoyée (pas toute la table, informations "partielles"), aux seuls routeurs qui en ont besoin ("limitées"). A vecteur de distance.
Contrairement à RIP ou IGRP, qui ne conserve dans leur table que la meilleure route et en attendent une meilleure en cas d'indisponibilité, EIGRP utilise une table topologique pour mémoriser toutes les routes reçues, pas seulement les meilleures, pour disposer de routes de secours (
show ip eigrp topology, show ip eigrp topology all-links pour voir mêmes les routes qui ne seront pas utilisées). EIGRP est capable d'obtenir des routes sans boucle grâce à un calcul effectué de façon coordonné par les routeurs (au lieu d'utiliser des techniques telles que les minuteurs de mise hors service).Evolution de IGRP, prenant en charge les VLSM. Un peu moins de sauts (224 sauts). Peut communiquer avec IGRP.
Métrique basée avant tout sur la bande passante et le délai (temps nécessaire à un paquet pour parcourir une route). La bande passante et le délai ne sont pas mesurés en temps réel, il y a des valeurs types selon les interfaces et l'administrateur peut les changer (commande
bandwith 256 par exemple, n'a aucun effet sur la bande passante, c'est juste une indication pour eigrp). formule de calcul pour la métrique. Il est déconseillé d'utiliser la charge. La formule par défaut peut se résumer par "K1*bande passante+K3*délai".Pour changer les métrique, utiliser
metric weights 0 k1 K2 k3 k4 k5. On peut voir les valeurs de K avec show ip protocols.Convergence plus rapide que les autres protocoles à vecteur de distance grâce à l'absence de minuteurs de mise hors service.
Utilise l'algorithme DUAL (Diffusing Update Algorithm, c'est pour ça que dans la table de routage, EIGRP est indiqué par un D quand l'algorithme est en train d'être calculé). DUAL permet des chemins sans boucles, des chemins de secours, une convergence rapide, une utilisation minimale de la bande passante car màj limitées. La "distance de faisabilité" est la métrique la plus basse vers un réseau de destination. Un "successeur" est le routeur vers où on doit se diriger pour suivre la route. Les successeurs se voient avec
show ip eigrp topology (pas dans l'affichage des routes). Dans la table topologique, une route est indiquée comme "P" (passive, aucun calcul n'est en train d'être fait, la route fonctionne) ou "A" (active, le routeur cherche un chemin). On peut voir l'algorithme en action avec la commande debug eigrp fsm.Utilise Reliable Transport Protocol pour s'échanger des paquet, un protocole fiable, avec accusé de reception, qui peut également fonctionner en mode "non fiable" pour prendre moins de ressources Plus d'infos.
Pour vérifier l'état de ses voisins, utilise toutes les 5 secondes un protocole léger ("Hello"), avec RTP en mode non fiable (sur certains réseaux tels que X.25, les paquets Hello sont échangés toutes les 60 secondes). Pour s'échanger des routes, EIGRP utilise RTP en mode fiable, demandant accusé de reception. Utilise également RTP fiable pour faire des demandes.
En résumé, 5 types de paquets : Hello, envoie de route/accusé de réception, demande de route/accusé de réception.
Si un routeur ne répond pas à un HELLO au bout de 3 fois l'intervalle d'envoi d'un HELLO (15s), la route est déclarée hors service et le routeur cherche un autre chemin.
Peut fonctionner avec IP, IPX, Appletalk.
Distance administrative de 90, la distance administrative du résumé de routes IGRP est de 5, la distance administrative de route EIGRP distantes est de 170.
Paquet IP (EIGRP peut aussi fonctionner sur IPX ou AppleTalk) :
Envoie à l'adresse ip de multidiffusion 224.0.0.10 (protocole EIGRP vaut 88) ainsi qu'à une MAC multidiffusion.
Un en tête de paquet IGRP comprend un code opération (1=màj, 3=demande, 4=réponse, 5=Hello), le numéro de système autonome (doit être le même pour un ensemble de routeur sous une même administration utilisant le même protocole de routage. Même si c'est déconseillé, un routeur peut exécuter plusieurs instances d'IGRP en même temps , il se sert de ce numéro entre 1 et 65535 choisi par l'administrateur pour les différencier). Il comprend aussi les constantes, de K1 à K5, que l'administrateur peut modifier pour donner plus ou moins de priorité à la charge (mesurée de façon dynamique), le délai ou la fiabilité (fréquence de mise hors service d'une liaison, mesuré de façon dynamique) dans le calcul de la métrique. Détails du calcul sur wikipedia. Contient également un champ "temps d'attente", qui spécifie combien de temps attendre le prochain paquet "hello".
Ensuite, il est indiqué une route interne : l'adresse du tronçon suivant, le délai, la bande passante, le MTU (n'influence pas le calcul de la métrique), le nombre de sauts, la fiabilité, la charge, la longueur du préfixe, l'adresse du réseau de destination.
Enfin, il est indiqué les routes externes. Les champs sont les mêmes que les routes internes, auquels on va rajouter tronçon suivant, routeur d'origine, numéro de système autonome d'origine, balise arbitraire métrique de protocole externe, ID d eprotocole externe et indicateur.
Pour configurer eigrp :
router eigrp numéro_système_autonome, network 10.0.0.0, network 11.0.0.0.On peut utiliser un masque générique pour annoncer certains sous réseaux-spécifiques. C'est l'inverse d'un masque de sous-réseau, par exemple si le masque du sous réseau est 255.255.255.252, le masque sera 0.0.0.3. Certaines versions d'IOS permettent d'utiliser directement 255.255.255.252.
Pour changer la fréquence d'envoi de hello :
ip hello-interval eigrp numéro_système_autonome secondesPour changer le temps d'attente de la réponse à un Hello :
ip hold-time eigrp numéro_système_autonome secondesPour voir les voisins ayant répondu à hello :
show ip eigrp neighborsIl est important que le numéro de système autonome soit le même sur tous les routeurs. Pour le voir, un
sh run ou show ip protocols.EIGRP n'utilise pas plus de 50% de la bande passante par défaut. Cette valeur peut être changée avec
ip bandwidth-percent eigrp 1 60% (pour mettre 60% au réseau autonome 1)CDP
Cisco Discovery Protocol, utilisé par les machines cisco connectées directement entre elles (même segment réseau) pour se reconnaitre. Pour avoir des informations sur le status du protocole :
show cdp. On peut afficher la liste des voisins avec la commande show cdp neighbors, show cdp neighbors detail et show cdp entry *. Fonctionne au niveau de la couche 2.CDP peut poser de sproblèmes de sécurité en diffusant ainsi les adresses.
Pour désactiver globalement :
no cdp run.Pour désactiver sur une interface, se mettre en mode de configuration de l'interface puis
no cdp enable.Grâce au protocole CDP, on peut mapper un réseau inconnu en affichant les adresses des voisins sur un routeur, puis se connectant en telnet et affichant le sadresses des voisins suivants, etc.
Généralités
La table de routage cisco est hiérarchique. L'organisation de son affichage se fait en se basant sur les classes ip même si concrètement les routeurs ne se basent pas sur ces classes (cette forme d'affichage est un reliquat de l'époque où les classes été utilisées).
On trouve tout d'abord les routes de niveau 1 (qui mènent vers un réseau où le masque est inférieur ou égal au masque de la classe ip, ou bien une route par défaut).
On parle également des "meilleurs routes" ("ultimate route", qui mènent vers une adresse de tronçon suivant "via 1.2.3.4", ou vers une interface, on pourrait traduite ultimate par "finale" vue qu'elles indiquent la sortie).
Il existe aussi les routes parents ("network 1.2.0.0/16 is subnetted, 1 subnet") et les routes enfants (appelée "niveau 2"). Quand une route a un masque supérieur au masque de sa classe, une route parent est créée.
Les routes enfants sont des "ultimate route", car elles envoient vers un tronçon suivant ou une interface.
En résumé :
-Routes de niveau 1 meilleures routes = routes dont le masque est égal ou inférieur la classe ip menant vers une sortie.
-Routes de niveau 1 routes parents = route avec un masque correspondant à sa classe ip, contenant une route enfant.
-Routes de niveau 2 (ou "routes enfants) meilleures routes = un masque supérieur au masque de classe ip (ex /16 pour 10.1.0.0), affichées sous une route parent, indiquant une sortie.
Lorsqu'il doit envoyer un paquet, le routeur vérifie tout d'abord la correspondance avec les routes de niveau 1.
-S'il trouve une route de niveau 1 meilleur route, il enverra le paquet par là. Fin.
-S'il trouve une route de niveau 1 parent, il analyse les enfants.
--Si une route enfant correspond, il envoit vers la sortie qu'elle spécifie. Fin.
-Si une route enfant ne correspond pas, il vérifie s'il travaille en classe ou sans classe.
--S'il travaille sur ses tables de routage avec les classes, il détruit le paquet. Il n'essaye même pas route par défaut. Fin.
--S'il travaille sans classe, il recommence à chercher une route qui correspondrait au niveau 1.
---S'il n'y a pas d'autre route correspondante à part la route 0.0.0.0 (passerelle), il l'envoie vers sa passerelle. Fin.
---S'il n'y a pas de passerelle, il détruit le paquet. Fin.
Donc, par exemple, un paquet peut faire : routes de niveau 1⇒ ya une correspondance, c'est une route parent⇒ route de niveau 2⇒sans correspondance et sans travailler par classe⇒route de niveau 1⇒passerelle.
La "meilleur correspondance" est la route qui ressemble le plus à l'adresse où le paquet veut aller.Un paquet qui veut aller en 1.2.3.4 aura une meilleure correspondance avec 1.2.3.0/24 que 1.0.0.0/8. Est pris en compte le nombre de bits correspondants indiqués par le masque de sous-réseau. Par exemple, un paquet voulant aller en 172.16.0.10 aura une meilleure correspondance avec 172.16.0.0/216 que 172.16.0.0/8.
Correspondance de 1 :
192.168.1.2 = 11000000.10101000.00000001.00000010
172.128.0.0/16 = 10101100.10000000
!
Correspondance de 25 :
192.168.1.2 = 11000000.10101000.00000001.00000010
192.168.1.0/25 = 11000000.10101000.00000001.0
!!!!!!!!.!!!!!!!!.!!!!!!!!.!
Il est possible de demander aux routeurs de consulter leurs tables de routage en travaillant par classe avec la commande
no ip classless. C'était le comportement des routeurs avant IOS 11.3. En mode sans classe, il n'essaiera qu'une seule route de niveau 1 (il n'essaiera donc pas la route par défaut). Au début d'internet, les routeurs n'avaient pas besoin de ça car chaque routeur était supposé connaitre l'intégralité des sous-réseaux de l'entreprise.Un routeur peut traiter sa table de routage en utilisant les classes, tout en fonctionnant avec un protocole sans classe comme RIPv2.
DHCP
DHCP (Dynamic Host Configuration Protocol) est un protocole utilisant UDP sur les ports 67 et 68 pour distribuer adresses ip (selon une plage d'adresse, "pool"), masque, adresse de passerelle, serveurs dns, serveurs de temps, etc. Généralement, l'adresse est "louée" pour un certain temps au pc. C'est une extension du protocole BOOTP, qui avait le même objectif.
Le client envoie un paquet DHCP discover (de source 0.0.0.0 à destination 255.255.255.255, port 67) ⇒ le serveur répond (port 68) par un DHCP offer contenant l'adresse mac du client, une proposition d'adresse ip/masque/bail, sa propre ip ⇒ le client sélectionne le premier serveur dhcp qui répond et lui envoie un paquet DHCP request indiquant qu'il accepte et indiquant par là aux autres serveurs DHCP qu'il refuse ⇒ le serveur lui envoie DHCPACK, un accusé de réception.
Pour communiquer avec le client qui n'a pas d'ip, les 2 machines utilisent leur adresse mac (le paquet est émis vers ff:ff:ff:ff:ff:ff au niveau de la couche réseau mais l'adresse mac est indiquée dans les données).
DHCP ne distribue des ip que dans les segments dans lesquels il est directement connecté, sauf si on utilise un relais dhcp. Un relais DHCP permet de n'avoir qu'un seul serveur DHCP pour plusieurs réseaux (plus facile pour la maintenance).
Si windows n'arrive pas à obtenir une adresse DHCP, il attribuera au PC une adresse APIPA (automatic private internet protocol adressing) entre 169.254.0.0 et 169.254.255.255 ou utilisera la configuration alternative précisée dans les paramètres IPV4.
Les serveurs DHCP font aussi souvent office de serveur BOOTP (protocole similaire à DHCP, moins évolué)
Une attaque courante consiste à se faire passer pour le vrai serveur DHCP : le serveur HDCP privilégié étant le premier qui répond, un pirate peut monter un serveur DHCP qui prendra la place du vrai.
Serveur DHCP (Cisco)
Les commandes, dans l'ordre :
-ip dhcp pool (nom du pool)
-network (le réseau dans lequel vous voulez donner des ip) (masque)
-default-router (adresse de la passerelle par défaut pour le réseau)
-dns-server (adresse du ou des serveurs dns)
-lease (nombre de jours, nombre d'heures, nombre de minutes)
On peut retirer des adresses du pool avec la commande :
ip dhcp excluded-adress (ip) (masque)
On peut vérifier les baux attribués par le routeur avec :
show ip dhcp binding
Et l'activité du serveur avec :
show ip dhcp server statistics
Enfin, l'activité en temps réel avec :
debug ip dhcp server events (ou "debug dhcp")
Relais DHCP (Cisco)
Les routeurs bloquent les broadcast, donc pour qu'une communication DHCP passe à travers un routeur, il faut le transformer en relais.
Se met sur l'interface de la patte qui va dans le pool :
-
ip helper-address (IP du serveur DHCP)Cette commande remplace les adresses de broadcast par des adresses unicast (vers une machine précise, en l'occurrence, l'autre routeur).
L'adresse sera aussi remplacé pour les protocoles : TFTP (69), DNS (53), Time (37), NetBIOS Name Server (137), NetBIOS Datagram service, BOOTP Server (67, ancienne version de DHCP), BOOTP Client (68), TACACS (49).
Pour ne laisser que les ports nécessaires ouverts, on peut utiliser "no ip forward protocol udp 180" en mode conf t, ou utiliser des ACL.
Access list
Une access list (ACL) est un ensemble d'instructions pour autoriser ou refuser des paquets en fonction des adresses de destination ainsi que, pour la version étendue, en fonction de l'adresse d'émission, des ports, du type de paquet (icmp, udp, tcp...).
La seule difficulté est le masque générique, qui fonctionne un peu l'inverse du masque normal : les bits à 0 sont vérifiés, les bits à 1 ignorés.
En configurant les ACL, on leur donne un numéro (ou un nom sur les routeurs récents). S'assurer que le numéro respecte une plage : de 1 à 99=ACL standard, de 100 à 199 IP étendue, 600 à 699=AppleTalk, de 800 à 899=IPX standard, de 900 à 999=IPX étendue, de 1000 à 1099=IPX Service Advertising protocol.
Une ACL permet aussi un logging. PArfois on met un "allow" juste pour voir ce qui passe sur le réseau.
une ACL est assez exigeant en terme de ressource.
Access list (cisco)
ACL standard
Modification de l'access list n°1 :
-access-list 1 deny 1.2.3.4 0.0.0.255 (<=on interdit les paquets provenant de 1.2.3.4)
-access-list 1 permit any (<=on autorise tout le reste, absolument à ajouter car par défaut tout est bloqué.)
Puis, on affecte cette ACL à une interface :
-int f0/0
-ip access-group 1 out
Pour voir les ACL :
show access-list
Pour voir à quel interface sont assignées les ACL :
show run
ACL étendue
Syntaxe :
Router (config)#access-list (numero de la liste) ("permit" ou "deny") (protocole à interdire, udp ou tcp) (adresse d'origine) (masque) (adresse de destination) (masque)(opérande lt , gt, eq ou neq -lower than, greater than, equal, not equal) (port ou non du protocole, par exemple 69 ou "web" ou "tftp").
Création de l'ACL étendue n°100 :
-access-list 100 deny udp host 212.16.23.6 host 10.23.4.6 eq tftp
-access list 100 permit ip any any
Le mot host dans la première ligne permet d'éviter de saisir le masque. Il indique qu'on veut vérifier tous les bits.
"permit ip any any" signifie qu'on autorise n'importe quelle ip vers n'importe quelle autre.
Si on veut bloquer ICMP, pas besoin de préciser le protocole :
access list 100 deny icmp host 1.2.3.4 host 5.6.7.8
Assignation de l'interface :
-int f0/0
-ip access-group 100 in
ACL nommées
Comme une ACL étendue mais avec un nom.
Création de l'ACL :
-access-list extended nom_de_l_acl
-deny udp host 1.2.3.4 host 5.6.7.8 eq tftp
-permit ip any any
Assignation de l'interface :
-up access-group stagiaire out
Vlan
Bon site sur les VLAN
Défini par la norme 802.1Q. Il existe également d'anciennes normes de vlan, telles que ISL.
Un réseau virtuel permet de diviser logiquement un réseau local en plusieurs domaines de broadcast. Autrement dit, avec des VLAN plusieurs réseaux/sous-réseaux IP peuvent coexister sur le même réseau physique (alors que sans VLAN, un routeur est utilisé pour séparer 2 réseaux). Évidemment, si on veut faire connecter ces VLAN, ils doivent passer par un routeur ou par un commutateur de couche 3 ("Routed VLAN Interface" ou "Switch virtual interface").
Concrètement, cela permet par exemple de faire passer différents réseaux dans un seul câble entre deux bâtiments.
Imaginer 3 VLAN, séparés par deux bâtiments : un seul câble relie les deux bâtiments (cable appelé "trunk" , parfois traduit par "agrégation" car il agrège plusieurs VLAN) et à chaque extrémité du câble se trouve un switch. Les paquets vont tout d'abord normalement du PC jusqu'au switch. Puis, entre les deux switchs, les paquets sont "taggés" selon la norme 802.1Q pour savoir vers où les redistribuer.
Sans VLAN il aurait fallu 3 câbles entre les bâtiments.
Le VLAN 1 est le VLAN par défaut, on ne l'utilise pas.
⇒On peut faire des VLAN par port physique, c'est à dire que les ports 2 à 5 sur un switch seront "isolés" dans le VLAN 3, tandis que les ports 6 à 8 dans le VLAN 5, par exemple. C'est le plus simple et le plus utilisé en PME/PMI. On parle parfois de VLAN de niveau 1 mais c'est discutable car ça utilise la couche ethernet.
⇒On peut aussi faire des VLAN par adresses MAC : telle adresse MAC = tel VLAN.Nécéssite beaucoup d'organisation, tenir la liste des cartes réseaux à jour, etc. donc difficile avec plusieurs milliers de machines. En outre peu de routeurs peuvent tenir à jour la bdd des addresses, il faut utiliser un serveur VMPS. Par contre ça permet de se brancher n'importe où et d'être directement dans le bon VLAN.
⇒VLAN par adresse ip. 172 sur un VLAN et 192 sur un autre. Problème, si quelqu'un change son ip il change de VLAN. Autre problème, DHCP (il faudra lui associer des adresses mac à donner à des ip).
⇒Enfin, VLAN par protocole (IP sur tel VLAN, IPX sur tel autre).
Les VLAN opèrent au niveau 2 de la couche OSI (tag dans la trame ethernet) : même si on décide du tag au niveau de l'IP, c'est quand même au niveau 2 que le tag est mis. Des switchs de niveau 3 et des routeurs peuvent être utilisés pour faire communiquer les VLAN entre eux.
Intérêt des VLANS : augmente la sécurité (séparation du trafic), moins de câbles (coûts diminués), meilleures performances grâces à la réduction des domaines de diffusion, gestion simplifiée.
On peut faire communiquer des vlans entre eux par l'intermédiaire d'un routeur : il n'y a qu'un seul câble, branché sur une seule interface (f0/0) du routeur, mais cette interface est divisée en sous-interface (f0/0.1, f0/0.2, f0/0.3, etc.). A chacune de ces sous-interface est assigné un VLAN.
VLAN natif : Le VLAN natif est un VLAN qui n'est pas taggé, pour permettre à des équipements non-compatibles 802.1Q d'être entre deux équipements 802.1Q. C'est à dire que si une trame non taggée arrive sur un trunk, elle ira dans le VLAN natif. C'est souvent le VLAN1. Ne pas confondre "VLAN natif" et VLAN par défaut (qui est le n° du VLAN où sont regroupés tous les ports en cas de reset). Si une trame tagguée arrive sur le VLAN natif (erreur de configuration de la part d'un périphérique), elle sera abandonnée. Explication sur les forums de cisco Explication en français
Les VLAN 1002 à 1005 sont réservés pour Token Ring et fibre.
De 1006 à 4094 on parle de VLAN à plage étendue, qui sont traités différemment par les routeurs Cisco (pas sauvés dans flash:vlan.dat comme les autres, mais dans la running config, moins de fonctionnalités, pas pris en charge par le protocole cisco VTP (VLAN Trunking Protocol).
VLAN de gestion : configuré pour accéder à un commutateur par telnet, voir la section "créer une sous interface pour gérer un switch à distance".
Il existe des VLAN "statiques", créés sur un switch et très rarement des VLAN "dynamiques" configurés à l'aide d'un "VLAN Membership Policy Server" en fonction de l'adresse MAC d'un périphérique qu'on peut connecter sur n'importe quel switch sur lequel sera créé automatiquement le VLAN approprié.
Voir également le protocole EtherChannel qui réduit les risques d'interruption de routage entre 2 vlans.
Créer une sous interface (Cisco)
Pour permettre par exemple à un routeur de faire communiquer plusieurs VLAN entre eux ("Router-on-a-stick "):
int f0/0 ⇒ no shut ⇒ int f0/0.1 ⇒ encapsulation dot1Q 2 (encapsulation signifie mettre un tag, 2 indique le VLAN) ⇒ ip address 1.2.3.4 255.255.255.255 ⇒ Cltr+ZLes sous-interfaces d'une même interface ont la même adresse mac.
Vlan par ports sur switch Cisco
Pour démarrer :
-Enable.
-Configure terminal (ou "conf t").
Pour créer un vlan (pas obligatoire, il peut se créer quand on met quelque chose dedans), faire
vlan 20, puis lui donner un nom name Compta. On peut aussi faire vlan 20,50,78 ou vlan 1-12.Mettre l'interface fast ethernet 2 dans le vlan 2 :
interface Fa0/2 ⇒ switchport mode access ⇒ switchport access vlan2. Ne pas oublier "no shut" pour activer le port. "switchport mode access" (non-obligatoire mais dans les best practices) sert à indiquer clairement qu'un port n'est pas un trunk.On peut assigner plusieurs interfaces à la fois à un VLAN :
interface range f0/1-10Pour mettre Fa0/12 en mode trunk :
interface Fa0/12 ( ⇒ éventuellement switchport trunk encapsulation dot1q pour les vieux) ⇒ switchport mode trunk ⇒ no shut.Le trunk n'est pas obligé d'acheminer tous les vlan , il peut très bien acheminer les vlan 1 et 3 mais pas le 2. par défaut il les achemine tous,
switchport trunk allowed vlan remove 5-10,12 pour enlever les vlan de 5 à 10 et le vlan 12. switchport trunk allowed vlan add 7 pour ajouter un vlan à acheminer.Pour configurer le vlan 99 en mode natif :
switchport trunk native vlan 99Commandes pour vérifications :
show vlanshow vlan briefshow int trunkshow arpshow mac-adress-tableshow int f0/2show int f0/2 switchport (pour vérifier l'état d'une interface)En cas de panne, vérifier que les branchements sont bons, avec
show interfaces f0/3 switchport et les commandes ci-dessus que le vlan native est le même sur les switch, que les trunks soient configurés des deux côtés avec show int trunk, qu'ils agrègent bien les vlans souhaités, que ça ne vienne pas d'un problème d'ip.Attention les VLAN sont sauvegardés parfois dans un fichier à part, VLAN.dat.
delete flash:vlan.dat pour supprimer ces infos.Pour supprimer un port d'un vlan faire
no switchport access vlan en mode de configuration d'interface. Un port ne peut être que dans un seul VLAN à la fois.Créer une sous interface pour gérer un switch à distance (Cisco)
#conf t
(config)#int vlan 99
(config-if)#ip address 192.168.1.1 255.255.255.0
(config-if)#no shut
(config-if)#end
#conf t
(config)#int f0/1
(config-if)#switchport mode access
(config-if)#switchport access vlan 99
Si vous avez besoin de changer de réseau penser à utiliser
ip default-gateway en mode de configuration du terminal.Vlan de voix sur switch Cisco
Dans l'interface à configurer,
mls qos trust cos pour garantir la priorité de ce VLAN, switchport voice vlan 150 pour mettre le VLAN 150 en mode voix.DTP (Dynamic Trunking Protocol)
Pour permettre à 2 ports de négocier automatiquement s'ils se mettent en mode trunk ou non.
switchport mode trunk pour mettre un port en mode trunk sans négocier, switchport mode dynamic auto pour qu'un port indique qu'on est près à se mettre en mode trunk si le port en face fait la demande, switchport mode dynamic desirable pour indiquer qu'on aimerait de préférence se mettre en mode trunk (si le port en face est en "mode access" on restera en accès) et enfin switchport nonegotiate pour désactiver DTP.VTP (VLAN Trunking Protocol)
Pour éviter d'avoir à modifier la configuration dans chaque switch quand on ajoute un VLAN. Un switch est défini comme le serveur VTP (mode par défaut sur routeurs cisco) qui transmet les infos sur la configuration, les autres comme clients.
Pour échanger des infos, ils doivent faire partie du même domaine VTP. Il peut également exister des switch dits "transparents" : ils laissent passer les paquets VTP mais ne sont pas influencés par eux (ont leur propre config de VLAN différentes des autres switchs du domaine).
Les clients stockent les infos sur les VLAN en mémoire vive (effacées hors tension), impossible de modifier les VLAN en se branchant sur eux directement (modification vient du serveur) par contre on peut modifier leurs ports pour les mettre en mode trunk ou accès. Les assignations de port dans les vlan ne sont pas transmis en VTP : sur le switch A le port 1 peut être dans le vlan 20 alors qu'il sera dans le vlan 30 sur le switch B.
Les infos VTP sont échangés via le trunk.
Lorsque les switchs ont une connexion redondante (plusieurs chemins pour aller d'un switch à l'autre), la transmission des trames VTP (ou "annonces VTP") ne se fait pas dans chaque chemin mais dans un seul, on parle "d'élagage VTP".
vtp pruning sur le serveur pour l'activer.Les trames VTP sont envoyées en multicast à "01-00-0C-CC-CC-CC". Sont envoyés le nom du domaine, un MD5, le format de la trame (802.1Q ou ISL), nom du serveur, horodate, numéro de révision VTP (sort de "version" de la configuration VTP, incrémenté à chaque changement de config, pour qu'un switch client sache s'il a déjà reçu ces infos ou non -remis à zéro en cas de changement de noms de domaine VTP).
Au niveau VLAN, leurs noms, leurs ID, leur status, leur type et autres.
3 types d'annonces, tous les messages comprennent le numéro de version de la config :
-Annonce de résumée envoyée toutes les 5 minutes ou lors d'un changement de la config VTP.
-Annonce de type sous-ensemble comprenant toutes les infos sur les VLAN envoyée en cas de modif/changement de status de vlan.
-Requêtes, faites par les clients, lors de l'allumage du commutateur ou lorsque le commutateur reçoit un message d'annonce dont la révision est supérieure à ce qu'il connait ou que le nom VTP a été changé.
show vtp counters pour voir des stats sur les annonces.show VTP status pour plus d'infos (version de la config VTP notamment).Il faudrait toujours avoir au moins 2 serveurs VTP, au cas où l'un d'eux tombe en panne (sans aucun serveur on ne pourrait plus configurer le domaine). Il faudra configurer les 2 serveurs de la même façon. Les serveurs ne se marchent pas sur les pieds car c'est celui qui envoie la plus haute révision qui sera prioritaire.
Avant d'installer un nouveau client qui viendrait d'un ancien réseau, il faut réinitialiser sa configuration VTP (par exemple en changeant temporairement de domaine
vtp domain nouveau_domaine ou mettant temporairement en mode serveur/transparent) car si sa configuration actuelle a un numéro de version supérieur à celui utilisé sur le nouveau réseau, il ne prendra pas la nouvelle config VTP.Pour configurer un serveur VTP :
On regarde comment il est configuré avec
show VTP status, on définit un nom de domaine avec vtp domain nom_de_domaine, on choisit une version avec vtp version 1. On peut configurer un lot de passe avec vtp password pour éviter que des pirates n'envoient de fausses trames vtp à nos client.Pour configurer un client VTP :
On regarde comment il est configuré avec
show VTP status, vtp mode client.Sauvegarde des modifications (Cisco)
Les appareils cisco utilisent le fichier "running-config" pour travailler. Si on modifie ce fichier, on modifie le routeur en temps réel.
Le fichier "startup-config" (qui est stocké dans la nvram) est chargé au démarrage, il est copié dans "running-config" (dans la RAM).
Si on change la configuration d 'un routeur, puis qu'on le redémarre, toutes nos modifications seront effacées.
Pour sauvegarder "running-config", il faut donc copier le fichier running-config dans le fichier startup-config, avec la commande : "Copy run start".
On peut programmer un redémarrage du routeur dans les 15 minutes alors qu'on travaille sur startup-config pour que si on est ejecté du routeur, le startup-config nous autorise à y revenir au bout de 15 min avec la commande
reload in 1 pour redémarrer après une minute.L'IOS (système d'exploitation des appareils Cisco, "Internetwork Operating System") est stocké dans la flash, en général copié dans la ram au démarrage ("system:"). Il peut également être cherché à l'extérieur, en tftp avec la commande
boot nom_de_l_image 1.2.3.4Mémoires
Outre les mémoires RAM, NVRAM et Flash, il existe également la mémoire ROM (qui contient le programme d'amorçage, des outils de diagnostique et une version allégée de IOS).
Exporter/importer la configuration (Cisco)
On peut utiliser un server tftp pour exporter/importer le fichier startup-config. Peut être utile pour modifier la configuration plus facilement avec le bloc note (par exemple, si on peut rajouter une ligne dans une ACL).
Sur PC, lancer Solar Wind TFTP server. Vérifier qu'il est lancé, que son ip est bonne.
Pour exporter : depuis le routeur, taper "copy nvram:startup-config tftp", pour copier le fichier startup-config sur le serveur tftp.
Pour importer, c'est l'inverse : "copy tftp nvram:startup-config".
Le fichier startup-config remplacera, comme toujours, le fichier running-config au démarrage.
Certains routeurs peuvent chercher eux même un fichier de configuration sur le réseau, en TFTP, à condition de donner un nom spécifique au fichier Voir le site de cisco.
Si on utilise un client comme Putty, on peut aussi simplement copier le résultat d'un
show run pour exporter et coller ce résultat en mode "conf t" pour importer.Reset switch Cisco
Retirer le cordon d'alim, relier le port console du switch (prise ethernet spéciale) au port console du pc (port COM). Démarrer une session avec Putty. Laisser appuyer le bouton mode pendant qu'on branche l'alimentation du switch. "flash_init" pour pouvoir modifier la mémoire flash. "load_helper". "dir flash:" pour voir les fichiers dans la mémoire flash. On va renommer le fichier de configuration : "rename flash:config.text flash:config.old". Il contient également les définitions de mot de passe. "boot" pour lancer le switch.
Reset routeur cisco
Sans mot de passe :
Procédure chez cisco
Au démarrage du routeur, en étant sous Putty, appuyer sur la touche "pause" pour entrer en mode ROMmon, c'est à dire avoir accès à une version basique du système d'exploitation Cisco IOS stocké dans la mémoire morte (ROM). A l'invite "rommon 1>", taper
confreg 0x2142. A l'invite "rommon 2>", taper reset. Appuyer sur CTRL+C pour passer les questions, puis enable. Ensuite, on va copier le fichier de configuration dans la NVRAM dans celui en RAM avec copy startup-config running-config.Pour éviter de démarrer tout le temps en mode ROMmon par la suite, faire
conf t, config-register 0x2102, puis un copy run start.Si on connait le mot de passe :
On efface le fichier startup-config, présent en nvram, qui est copié dans le fichier running-config à chaque démarrage avec
erase startup-config, puis on redémarre reload.On peut aussi effacer la nvram :
erase nvram:Commandes diverses(Cisco)
La plupart des commandes peuvent être annulées ou inversées en rajoutant
no devant.Donner un nom au routeur :
hostname nomPasser en mode configuration :
configure terminalPasser en mode privilégié :
enableMettre un mot de passe pour le mode privilégié : en mode configuration,
enable secret mot_de_passeMettre un mot de passe pour connexion console :
line console 0, password mot_de_passe, loginChiffrer les mots de passe déjà stockés en clair dans le routeur (pour éviter qu'ils soient visibles via
show run) : service password-encryptionSupprimer un fichier de la mémoire flash :
delete flash:nom_fichierDésactiver une interface :
shutdownActiver une interface :
no shutdown, attention, si elle ne reçoit pas de signal porteur d'un périphérique avec lequel elle serait connecté, l'interface restera "administratively down" malgré cette commande.Donner une description (à une interface, par exemple) :
description la descriptionPasserelle à un switch (pour savoir sur quel port envoyer par défaut) :
ip default-gateway 10.0.0.1Pour donner une passerelle à un routeur, utiliser :
ip route 0.0.0.0 0.0.0.0 192.168.2.1Afficher l'heure :
show clockAfficher la version d'IOS, de l'amorce, la RAM, la NVRAM et la flash disponible, l'état du flag confreg (entre parenthèse indique l'état où il sera au redémarrage), les interfaces, le modèle de la machine :
show versionSe connecter avec telnet :
telnet adresseAfficher les informations sur une route :
show ip route 1.2.3.4, show ip route static, show ip route connectedAffiche / modifie la taille de / supprime l'historique des commandes (en mode "line console 0" ou "line vty 0 4" :
show history, terminal history size 50, terminal no historyPour s'adapter automatiquement à un cable droit ou croisé :
mdix autoActiver l'authentification sur le serveur http :
ip http authentication enable (on peut utiliser "local" à la place de "enable" si on veut une méthode d'authentification externe)Activer le serveur http :
ip http authentication enableAfficher un message lors de l'allumage du routeur :
banner motdRedémarrer :
reload, reload in 1 pour redémarrer après une minute, Reload cancel pour annuler le redémarrage, Show reload pour voir le temps qu'il nous reste avant le redémarrage auto.Désactive le telnet, force le ssh :
transport input sshRéactiver telnet sur un routeur (car se désactive automatiquement si SSH activé) :
transport input telnetPour n'accepter les paquets DHCP que sur un seul port :
ip dhcp snooping, puis ip dhcp snooping trust dans l'interface du port.Pour n'accepter les paquets DHCP que sur un seul VLAN :
ip dhcp snooping vlan numéro, puis ip dhcp snooping trust dans l'interface du VLAN.Ajouter manuellement une adresse mac à un port :
mac-address-table static adresse_MAC vlan de_1_a_4096_ou_ALL interface id_interfaceN'autoriser que 2 adresses mac sur un port :
switchport port-security maximum 2N'autoriser qu'une adresse mac sur un port (config-if) : (
switchport port-security adresse_mac_a_autoriser).Enregistrer dans la listes des adresses autorisées les adresses déjà présentes et futures de la table mac (mode sticky)(config-if) :
switchport port-security mac-address stickyAjouter une adresse quand la machine est en mode sticky (config-if) :
switchport port-security mac-address sticky adresse_mac_à_ajouter (sinon, il suffit qu'une nouvelle machine fasse un ping sur l'interface si le nombre maximum autorisé n'a pas été dépassé)Voir la configuration de sécurité d'un port :
show port-security nom_de_linterfaceVoir les macs autorisées :
show port-security nom_de_linterfaceConfigurer plusieurs interfaces à la fois :
interface range FastEthernet0/0 – 10 puis no shut par exemple.Activer le telnet
Il faut un mot de passe pour pouvoir utiliser telnet.
conf t, vty 0 4, password motdepasse. Il faudra également un mot de passe sur le routeur enable secret motdepasse.Activer le ssh
Il faut donner un nom et un domaine au routeur :
hostname nom, ip domain name domaine.lan.Puis, effacer les éventuelles clefs générées
crypto key zeroize rsa, générer une nouvelle clef crypto key generate rsa.Créer un utilisateur :
username nom_de_l_utilisateur privilege 15 secret mot_de_passe, line vty 0 4, on indique que l'utilisateur est sur la base de donnée local : login local.Puis activer SSH :
ip ssh version 2, ip ssh rsa keypair-name nom.domaine.lanPour voir si le ssh est activé :
sh ip ssh, pour voir les connexions en cours : sh sshIp
Pour connaitre les ip de la machine,
show interfaces, show ip interface brief ou même show ip interface.Status "up" indique que l'interface fonctionne à la couche 1 (après un
no shut), Protocole "up" indique qu'il fonctionne à la couche 2.Ajouter une route vers 192.168.0.1 en passant par 10.0.0.1 :
ip route 192.168.0.1 255.255.255.0 10.0.0.1. On peut aussi demander à passer par une interface, par exemple "ethernet 1/0".Pour faire un ping
ping 1.2.3.4, un ! indique un succès, un . un échec, un U un message d'inaccessibilité de la part d'un routeur sur le chemin. En faisant un ping, on dit qu'on "teste la pile de protocole" (couche 1, 2, 3). On peut aussi simplement taper ping pour avoir d'avantage d'options.Debug
Par défaut, les messages de debug ne s'affichent pas en telnet. Il faut les activer avec "terminal monitoring" (ou "terminal monitor").
debug all = A ne pas utiliser, trop de messages à la fois, risque de faire planter le routeur. undebug all ou no debug all pour arrêter.Pour ne plus avoir "Translating "xxx"...domain server (255.255.255.255)", utiliser la commande
no ip domain lookup, ou bien ctrl+shit+6 (ou ctrl+shit+9).Pour ne plus être perturbé par les messages de debug alors qu'on saisie des commandes :
line con 0, logging synchronousOn peut aussi utiliser "ctrl+r" pour réafficher la ligne qu'on était en train de taper.
Pour interrompre un ping d'un routeur cisco : "ctrl+maj+6" (ou "ctrl+maj+9").
Pour voir les changements dans les tables de routage :
debug ip routingWindows
Partage connexion wifi (windows 8)
En ligne de commande :
netsh wlan set hostednetwork mode =allow ssid="nompointaccess" key="motdepasse"
Puis pour le lancer, ce qui devrait créer une nouvelle connexion réseau :
netsh wlan start hostednetwork
Pour voir qui est connecté :
netsh wlan show hostednetwork
Pour partager, clic droit sur la connexion qui va sur internet, propriété, onglet partage, autoriser d'autres connexions à passer par celle-là. Décocher la case dessous.
L'ip de la connexion wifi va changer (ex : 192.168.137.1). Plus qu'à connecter l'appareil au point d'accès et lui mettre une ip dans le même réseau.
Routage entre 2 connexions sur windows
Mettre à 1 la clef IPEnableRouter dans "HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters".
Carte de bouclage sur Windows
Pour connecter GNS3 dessus, par exemple.
Gestionnaire de périphérique, ajouter un périphérique, suivant, manuellement, carte réseau, carte de bouclage Microsoft. Puis, partager la connexion internet en utilisant cette carte de bouclage. Une IP privé lui sera attribuée (192.168.20.1 par exemple), l est désormais possible de se connecter à cette ip privée pour aller sur internet.
Configurer connexion ADSL cisco
interface ATM0/1/0
description ATM vers DSLAM FT
bandwidth 256
no ip address
atm vc-per-vp 2048
no atm ilmi-keepalive
!
interface ATM0/1/0.1 multipoint
pvc 8/35 #les fréquences
pppoe-client dial-pool-number 1
!
!
interface Dialer1
description PPOE VERS ORANGE
ip address negotiated #pour obtenir une adresse ip, certains FAI demandent de taper "DHCP" au lieu de "negotiated"
ip access-group netin in
ip access-group netout out
no ip redirects
no ip proxy-arp
ip mtu 1492 #taille max des paquets, peut être changé pour optimisation
ip nat outside #pour qu'un réseau privé puisse aller sur internet
ip virtual-reassembly
encapsulation ppp
dialer pool 1
no cdp enable
ppp authentication chap callin #identificaiton chap
ppp chap hostname xxxxxx
ppp chap password 0 xxxxxx
ppp pap sent-username xxxxxx password 0 xxxxxx #identification pap (moins sécurisé)
!
ip forward-protocol nd
ip route 0.0.0.0 0.0.0.0 Dialer1 #les routes inconnues doivent aller sur internet
!
Pour qu'on puisse se connecter sur f0/0 et avoir internet, il faut activer le nat :
!
interface FastEthernet0/0
ip address 10.10.0.1 255.255.0.0
ip nat inside
ip virtual-reassembly
duplex auto
speed auto
!
ip nat inside source list listnat interface Dialer1 overload
ip nat inside source static tcp 10.10.0.11 5800 92.89.166.97 5800 extendable
!
ip access-list extended listnat
permit ip 10.10.0.0 0.0.255.255 any
!
La ligne "ip nat inside.." permet de contacter une machine derrière le nat. Par exemple, pour contacter depuis l'adresse publique 92.89.166.97 la machine 10.0.0.1 qui héberge un site internet, faire :
ip nat inside source static tcp 10.10.0.11 80 92.89.166.97 80 extendableNAT avec routeur Cisco
Si un PC avec ip privée 10.0.0.1 est branché sur un routeur se connectant à internet, le PC ne pourra pas avoir accès à internet : il pourra faire un ping vers 8.8.8.8 mais 8.8.8.8 ne saura pas comment revenir à l'adresse 10.0.0.1.
PC A[(eth0)10.0.0.1]----[10.0.0.2(f0/0)]Routeur[(f0/1)92.65.2.1]----internet
Il faut donc mettre en place du NAT. Le plus simple est la traduction statique :
(config)#ip nat inside source static 10.0.0.1 92.65.2.1
(config)#interface f0/1
(config-if)ip nat inside
(config)#interface f0/0
(config-if)ip nat outside
On peut faire aussi une "traduction dynamique simple" ou encore une "traduction dynamique overload".
Faire fonctionner windows 7 avec OpenSWAN
A[192.168.19.3] ---- [192.168.19.4]B[10.0.0.1] ---- [10.0.0.2]C
Windows est sur A, B est un routeur, C est un linux.
On doit configurer une stratégie de sécurité ip dans
secpol.msc. Dans "stratégie de sécurité IP sur Ordinateur", créer une nouvelle stratégie IP, l'appeler "pouripsec", ne pas la configurer tout de suite.Clic droit⇒propriétés, ajouter, nouvelle règle. "Cette règle ne spécifie aucun tunnel", toutes les connexions réseaux, ajouter un filtre ip. Ajouter un filtre ip, cocher "miroir" pour qu'il s'applique dans les 2 sens. Indiquer les ip des machines à relier avec Ipsec.
Créer un nouveau filtre, personnalisé. Par défaut pour OpenSWAN, algorithme d'intégrité MD5, algorithme de chiffrement 3DES. Penser à cocher utiliser la session de clef principale. L'assistant devrait demander d'entrer la clef partagée (ou le certificat). Clic droit sur la stratégie, puis "attribuer".
Lancer ip sec sous linux :
/etc/init.d/ipsec restart. Puis lancer la connexion ipsec auto --up maconn. Si elle reste en suspend, il y a une erreur de configuration (ip, clef, chiffrement...).Si la communication est crypté, en faisant un ping, on ne devrait plus voir passer des paquets ICMP mais des paquets ESP .
VPN
Ou "tunneling". Encapsulation, souvent chiffrée (on peut encapsuler de l'ip dans l'ip ou utiliser openVPN sans chiffrer mais c'est peu utilisé), des paquets entre 2 machines dans le but d'établir une "connexion locale" virtuelle entre 2 machines non-directement connectées. On pourra avoir 2 machines distantes sur internet qui communiquent avec des ip privées.
Un VPN permet de connecter 2 sites de façon sécurisée et indépendante des protocoles.
Exemples : une compagnie qui veut connecter deux lieux de travail, dans 2 villes différentes ; une entreprise qui se connecte à un datacenter via VPN.
Dans windows, centre réseau et partage, configurer une nouvelle connexion VPN.
Les 2 côtés du VPN [url=https://technet.microsoft.com/en-us/library/cc984423.aspx]doivent connaitre la "pre-shared key"[/url], (essentiellement, c'est un mot de passe pour se connecter au VPN).
Pour traverser un NAT, ça peut être encapsulé sur UDP.
On peut faire un VPN de site à site ou un VPN multi-sites (qui permet plusieurs connexions à un seul virtuel). Au lieu d'avoir le bureau principal qui se connecte aux data center et les bureaux secondaires qui se connectent au bureau principal, chaque bureau secondaire+le principal se connectent directement au data center.
Open VPN
D'après le TP chez cath.milard.free.fr
Autre tutorial
Permet d'établir un réseau privé virtuel entre 2 machines, fonctionne en architecture client/serveur, doit être installé aux deux extrémités, peut être non-chiffré ou chiffré avec clefs asymétriques ou symétriques.
Par exemple, selon le schéma suivant :
A[10.1.0.1] ---- [10.1.0.2]B[10.2.0.2] ---- [10.2.0.1]C
Tunnel :
A[172.16.0.2] --- [172.16.0.1]C
On ajoute le groupe "openvpn"
addgroup openvpn et l'utilisateur "openvpn" pour plus de sécurité useradd -d /dev/null -g openvpn -s /bin/false openvpn puis on créé le fichier "/etc/openvpn/server.conf".
# Mode tunnel IP
dev tun
# Adresses IP des deux extrémités du tunnel (locale distante)
ifconfig 172.16.0.1 172.16.0.2
# Mode de chiffrement
cipher none
# Mode d'authentification
auth none
# Verbosité du journal
verb 2
# user et group particulier pour le processus
user openvpn
group openvpn
Pour lancer Open VPN :
/etc/init.d/openvpn startOn peut aussi forcer open vpn à se lancer en forçant un fichier de config :
/etc/init.d/openvpn --config /etc/openvpn/server.conf (aura l'air bloqué mais fonctionne tout de même, permet de débgugger car indique les erreurs de conf).Pour tester, voir si l'interface est apparue (ifconfig), faire un ping sur l'interface virtuelle (172.16.0.1).
Pour voir le log :
tail /var/log/syslogDu côté du client, dans un fichier à créer nommé "C:Program Files\OpenVPN\config\client.ovpn" :
# adresse IP du serveur dans le réseau public
remote 10.2.0.1
# Tunnel mode IP
dev tun
# adresses IP des deux extrémités du tunnel (locale distante) :
ifconfig 172.16.0.2 172.16.0.1
# Cipher mode
cipher none
# Authentification mode
auth none
# Log verbosity
verb 2
Lancer OpenVPN GUI en tant qu'administrateur, clic droit sur l'icône dans la barre des tâches, "connect". Une nouvelle interface devrait apparaitre avec l'ip en 172.
Certificats
Sur le serveur linux se trouvent des scripts pour gérer les certificats, dans le dossier "/usr/share/doc/openvpn/examples/easy-rsa/2.0/". Copier le contenu de ce dossier à un autre endroit.
1. Lancer le script "vars" (avec
source ./vars par exemple) pour mettre en place les variables qui seront utilisés par les autres scripts.2. Lancer "clean-all" pour créer un sous-dossier "keys" vide.
3. Lancer "build-ca" pour créer une clef privée et son certificat.
4. "build-key-server nom_du_serveur"
5. "build-key nom_du_client"
6. "build-dh" pour créer une clef partagée entre les 2.
Vous devriez avoir dans le dossier "keys" : "ca.crt", "ca.key", "nom_du_serveur.crt", "nom_du_serveur.key", "dh1024.pem", "nom_du_client.crt", "nom_du_client.key".
Dans le dossier /etc/openvpn, copier ca.crt, ca.key,nom_du_serveur.crt, nom_du_serveur.key et dh1024.pem.
Sur le client, dans c:program filesopenvpnconfig, copier ca.crt, "nom_du_client.crt", "nom_du_client.key".
Dans le fichier de configuration d'openvpn, rajouter :
ca ca.crt
cert LeServeurVPN.crt
key LeServeurVPN.key
dh dh1024.pem
tls-server
Dans le fichier de configuration windows, ajouter :
#clé et certificat du client et certificat du CA
ca ca.crt
cert Client01.crt
key Client01.key
tls-client
OpenVPN derrière un proxy
Il faut ajouter la ligne
http-proxy ip_de_serveur_proxy port_du_proxy ainsi que préciser un port que laisse passer le proxy, par exemple port 443. Puis proto tcp-client sur le client, proto tcp-serveur sur le client.Transmission de routes avec OpenVPN
Le serveur OpenVPN peut envoyer les routes de son réseau privé à une machine qui se connecte vers le réseau public, par exemple :
Réseau privé [192.168.1.1]---[192.168.1.2]OpenVPN[10.0.0.1]---[10.0.0.2]Client VPN
Du côté du serveur, ajouter
push 192.168.1.0 255.255.255.0 et tls-server. Du côté du client, rajouter pull et tls-server.Comment ICMP traverse un NAT ?
Dans chaque ICMP il y a un champ "ID" qui identifie le paquet. Le routeur mémorise le numéro, change l'ip source, envoie lef paquet paquet. Quand il revient, il le renverra à la machine qui l'a envoyé.
http://linuxfr.org/users/edouard/journaux/nat-et-icmp
http://www.cisco.com/c/en/us/support/docs/ip/network-address-translation-nat/13771-10.html
http://superuser.com/questions/135094/how-does-a-nat-server-forward-ping-icmp-echo-reply-packets-to-users
http://tools.ietf.org/html/rfc3022
DSL
L'ADSL est Asymétrique : upload et download pas identique.
Entre 512 et 20 megabits en download, 1 mega en upload diviser par 8 pour avoir le débit en octet.
Multiplexage fréquentiel : plusieurs signaux sur un même support à des fréquences différentes. C'est ce qui se passe aussi avec la radio et la télé. Tous les signaux sur le même support passent sans se perturber l'un l'autre. De 300 à 3400 hertz pour la voix. La partie transmission de données va être transférée entre 130khz et 1Mhz, donc beaucoup plus.
Boucle locale : liaison téléphonique, ce qui relie l'abonné, avec une paire torsadée sur les poteaux, avec le DSLAM qui se trouve dans un rayon de 5 km de l'abonné. Le DSLAM se connecte au BAS (Broadband Access Server, qui fait l'authentification).
ATM : protocole destiné à transférer ce qu'on veut, des données, de la voix, de la vidéo, etc. Permet d'établir des circuit virtuels, c'est à dire qu'on aura un circuit commuté, mais virtuel, le chemin peut changer. Il enregistre le fait que les 2 extrémités sont connectées et simule un circuit. C'est le coeur de réseau de France Télécom. Certaines entreprises pourraient fonctionner en interne avec ATM. 3 couches ATM : physique (2 sous-couches, Tranmission Convergence pour contrôle des données/adaptation des débits/délimitation des cellules et Physical Medium pour l'accès au support physique et les mécanismes de synchronisation), ATM (multiplexage, génération/extraction des en-têtes, acheminement des cellules) et AAL (qui peut servir à simuler de l'Ethernet, divisé en 2 sous-couches, Segmentation And Reasembly Sublayer pour ségmenter/réassembler les cellules pour les couches supérieures et Convergenge Sublayer pour la synchronisation de l'horloge). Plus d'infos sur le site de l'université de Toulouse Plein d'infos sur le wiki de cisco
Modem à l'origine c'était transformation de signaux numérique en analogique, maintenant on appelle toujours ça pas abus de langage un modem mais il s'agit d'un boitier ATM.
On peut se connecter de 2 façons :
PC[adresse privée]-----[adresse privée]box[adresse publique]-----internet
PC[adresse publique]----adaptateur-----internet
PPP : Point-to-Point Protocol, s'utilise avec le protocole chap ou pap qui utilise mot d'utilisateur et mot de passe, pour une connexion entre 2 hôtes. Pour se connecter sur le réseau mondial. Au début prévu pour mettre sur des liaisons de niveau 2 de réseau WAN (les protocoles HDLC, PPP, SDLC, LAPD sont des exemples de protocoles de niveau 2, maintenant on a quasiment plus que de l'éthernet). Etant un protocole point à point, l'adressage au niveau de la couche 2 est facultatif (une seule destination possible).
PPPoA (PPP over ATM) ou PPPoE (PPP over ethernet) : on établit la connexion directe avec le BAS. PPP est un protocole de niveau 2 donc il peut transporter de l'ip (comme ethernet), mais il peut être transporté sur une autre couche : on peut avoir de l'ethernet qui contient de l'ip qui contient du PPP qui contient de l'ip (à cause des multiples étapes avant d'arriver sur internet).
L2TP est un protocole permettant de transporter un autre protocole de niveau 2 de façon chiffrée.
CHAP (challenge handshake authentification protocol) : CHAP va vérifier plusieurs fois en cours de route l'identité des communiquants. Serveur envoie un mot de passe au hasard que le client va chiffrer avec son mot de passe et le renvoyer.
PAP est un plus vieux protocole, plus simple (pas de vérification une fois la communication établie, mot de passe pas crypté....). Certains équipements ne permettaient pas le CHAP donc les FAI ouvrent PAP et CHAP.
Le problème est la taille du MTU, puisqu'on rajoute PPP à ethernet, ça peut ne plus marcher. A niveau de la machin client on peut aller dans le registrre et réduire la taille des paquets. La deuxième solution est au niveau du routeur, pour réduire la taille du MTU (fragmentation). Ca pose les mêmes problèmes en VPN, sur open VPN on peut choisir la taille du MTU. On choisis 1462 au lieu de 1500 pour ne plus avoir ce problème.
On parle d'équipement terminal de circuit de données (ETCD, "DCE" en anglais) pour le périphérique qui se connecte sur le réseau étendu (à un autre ETCD). Il fait une conversion du signal et doit faire office d'horloge pour un autre périphérique, l'équipement terminal de traitement de données (ETTD, "DTE" en anglais). Par exemple, une carte ADSL sera ETCD, le routeur (qui héberge la carte) sera ETTD, ou bien un modem sera ETCD et un PC ETTD. Lorsqu'on connecte 2 routeur ensemble avec un câble série (câble V.35), l'un devient DTE et l'autre DCE. On peut changer les rôles et la fréquence de l'horloge (
clockrate 56000 pour cette dernière, est visible par un "sh run").Liens intéressants
http://www.securite-informatique.gouv.fr/
Cours et exercices sur la sécurité informatique
http://xenod.free.fr/index.htm
Guide gouvernemental d'intégration de la sécurité des systèmes d'information dans les projets
http://guide-wifi.blogspot.fr/