Editer Vrac du vrac
Sommaire
1. Docker
- Généralités
- Image Linux sur Windows
- Lancer un conteneur
- Faire sa propre image
- Interagir avec un docker
- Docker Networks
- Docker compose
2. Migration Gitlab vers Github
3. Notation Big O
4. LLM
5. Go
6. Python
7. Education
8. Ergonomie
9. Conduite de projet
10. Scrum
11. UML
- Diagramme de classe
- Diagramme de cas d'utilisation
- Diagramme de séquence
- Diagramme d'activité
- Diagramme de composants
- Diagramme de déploiement
- Diagramme de package
- Diagramme d'état
- Diagramme de communication
- Diagramme de temps
- Diagramme d'objets
- Diagramme global d'interaction
- Diagramme de profils
- Diagramme de structures composites
- BOUML
- PlantUML
12. Tests
- Les tests pendant le cycle de vie logiciel
- Android
13. Git
- Guide rapide pour débuter
- Organisation des branches
- Divers
- Tags
- Sauvegarde du Token Git sous Windows
- Head
- Cherry Pick
14. Subversion avec Netbeans
15. Symfony
16. Php
17. CSS
18. Modélisation mathématique des langues naturelles
19. Chatterbot apprenant
20. Lojban
21. Français
- Vocabulaire
22. Anglais
23. Arabe
- لا
- Vocabulaire
Pages des trucs qui n'ont pas assez de matière pour avoir leur propre page.
Un outil open source qui fonctionne avec des conteneurs. Un conteneur est une sorte d'espace indépendant du système d'exploitation où on peut faire des actions qui ne vont pas affecter l'OS. On a l'impression que le conteneur est son propre petit OS indépendant mais c'est juste une illusion offerte par Docker.
Imaginons qu'on écrive une appli avec ses libs, sa base de données, sa version de Java/Python, ses fichers externes... on pourrait l'avoir dans cet espace puis distribuer l'intégralité de cet espace à d'autres personnes, et on serait sûr que tout marcherait directement.
Un conteneur se créé à partir d'une image. On peut faire ses images soi même ou bien récupèrer une image sur un annuaire docker (l'officiel -appelé "docker hub"- ou celui de votre entreprise si elle en a un) en utilisant la commande
Pour voir les images téléchargées sur notre poste :
On peut les utiliser en faisant
Certaines images peuvent être vraiment des OS mais ne pas croire qu'un conteneur est OBLIGATOIREMENT un OS virtualisé.
Attention une image pour linux ne marchera pas sous Windows.
Pour contourner ça on peut utiliser Windows Subsystem for Linux (wsl --install dans un powershell) qui va mettre un petit Linux dans notre Windows. Encore plus simple, mais un peu envahissant : utiliser docker desktop et lui demander de se mettre en mode linux (derrière il va juste... installer WSL également).
Attention à ne pas confondre RUN et START. Run va faire un éventuel pull+créer un nouveau container+start. Start va juste lancer un conteneur existant.
Pour lancer un conteneur existant faire donc
Un bon exemple est l'image "hello-world". Faites un
Une autre image intéressante est l'image du tutorial :
Vous pouvez voir l'association des ports entre le conteneur et notre PC en faisant
Pour arrêter :
Pour faire ses images soi même, il faut créer un fichier Dockerfile avec une syntaxe particulière :
Ci-dessus on demande de créer une image à partir de rien (scratch) -on pourrait créer à partir d'un image existante genre Ubuntu par exemple-, on lui demande d'ajouter le fichier coucouProg puis de lancer coucouProg.
CoucouProg pourrait être un simple fichier c compilé avec
Pour se servir de ce fichier faire
Et voilà le travail :
On peut avoir un serveur qui se lance automatiquement au démarrage du conteneur, par exemple
Mais sur certaines images on peut carrément invoker la ligne de commande, par exemple en lançant un conteneur ubuntu :
Si vous faites des modifications dans un conteneur, par exemple créer des fichiers dans le conteneur Ubuntu puis que vous le supprimez, vous perdrez ces fichiers. Il est possible de ne pas écrire dans le conteneur directement mais à côté, dans un "volume", une sorte de disque externe, ce qui permet de supprimer le conteneur mais garder les données.
Puis en utilisant "run"
Faites
On peut "lier" un répertoire de notre OS à un repertoire du conteur. Toutes les modifs qu'on fera depuis notre OS ou depuis l'intérieur du conteneur seront synchronisées.
Ici je demande un lien entre ~/ubuntuHome sur mon "vrai" OS et /home/ubuntu dans le conteneur Ubuntu.
Pour faire communiquer des conteneurs entre eux, on peut créer un réseau. Ou pourrait exposer les ports des conteneurs avec "-p" mais si on a notre app dans un conteneur connectée à un autre conteneur qui faire tourner un serveur mysql, c'est plus sur de ne pas exposer les ports du serveur à l'exterieur.
Pour créer un réseau :
Ensuite lors du run d'un conteneur on va lui dire qu'il est sur tel réseau avec tel nom :
Pour qu4ún autre contenur puisse lui parler, il faut le runner sur le meme --network et lui demander datteindre LeNonReseauDeCeConteneurSurMonBeauNetWork.
Plutôt que de créer conteneurs avec docker files on peut tout mettre dans un seul fichier et utiliser docker compose.
Docker compose est un plugin, j'ai réussi à l'installer en faisant :
Exemple de fichier dockercompose.yml :
Puis faire
Ca m'a toujours semblé évident d'utiliser Gitlab étant donné qu'il est open source et qu'on peut donc héberger sa propre instance. Mais GitHub a 2 avantages : une communauté plus importante (ce qui facilite les coopérations et la promotion) et un système de plugins.
Pour migrer les repos :
-créer un nouveau repository dans GitHub (sur sur votre profilm repositories, new). J'ai utilisé les mêmes noms que sur GitLab.
-ce nouveau repository va donner une URL pour le clonage. Copiez là.
-dans GitLab, ouvrir votre repository, puis settings, mirroring, coller l'url pour faire le clonage https (https://user:pass@github.com/marl1/yourProjectName)
-Renseigner votre nom d' utilisateur. Attention, le mot de passe est un token.
-dans GitHub, créer un token sur votre profil, settings, developper settings, tokens (https://github.com/settings/tokens). GitLab a un token pour chaque projet, GitHub a un token commun à tous les projets. Sauvez le token.
-copiez/collez le token.
-validez le formulaire.
-cliquez sur les 2 flèches circulaires "update now".
Pour GitLab Pages vers GitHub Pages :
-il y a 3 types de GitHub pages : celles du developpeur, celles de l'organization et celles des projets. C'est cette dernière qui correspond aux GitLab pages, allez dans les settings du projet, "pages".
-Il y a 2 façon de déployer une pages de projet :
1) "deploy from a branch", c'est à dire un copier/coller automatique des fichiers du repos sur le serveur (parfait pour les sites statiques), choisissez juste la branche et tous les foichiers du repo seront mis sur le serveur puis ils vous donneront l'url (https://marl1.github.io/cyoajsengine/www/games/a_sample_game/index.htm).
2) utiliser un pipeline, indispensable si on veut lancer des tests avant le déploiement ou transpiler du code TS en JS par exemple.
Erreur : "Waiting for a runner to pick up this job... " L'image que vous demandez n'est peut etre pas disponible.
Utiliser le plugin github actions si vous avez VsCode, il signalera les erreurs de syntaxe.
Dans le monde de la programmation, c'est une façon concise de décrire le temps d'execution d'une fonction par rapport à son entrée.
Par exemple dans
Par contre
Autre exemple, pour calculer la somme de tous les chiffres d'un nombre, par ex 5 en entrée, on peut faire une boucle 1+2+3+4+5=15 (solution O(n)) ou bien juste une petite astuce mathématique "5*(5+1)/2=15", solution O(1).
Cette fonction de complexitée O(n) prend 14 millisecondes pour 1000 en entrée :
Elle met 140ms pour 10000, 1400ms pour 100 000....
Il existe également O(n²), lorsque la vitesse dépend de l'entrée mutipliée par elle-même, typiquement quand on parcourt un même tableau 2 fois :
Elle met 140ms pour 100 et 14000ms (QUATORZE SECONDES) pour 1000. Je ne veux même pas tester pour 10000.
La différence est vraiment flagrante avec O(N) donc elle a droit a sa notation spéciale.
D'autres notations existent, on voit bien les différence lorsque les fonctions sont exprimées graphiquement :
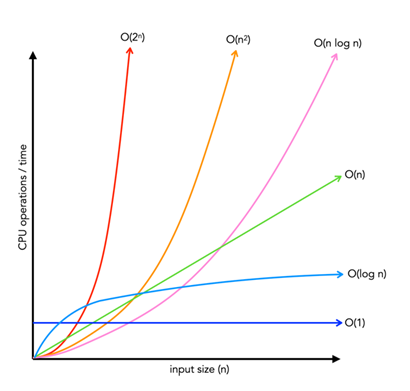
Par exemple O(log n) :
Elle met plus de temps a s’exécuter pour 1000 en entrée que 1 donc elle n'est pas O(1) MAIS même en mettant 1 000 00 00 00 00 00 00 00 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 en entrée on reste dans les 2 ou 3ms donc très largement plus rapide que O(N).
Autre notation à connaitre : O(2ⁿ), par exemple si on veut toutes les combinaisons possibles des éléments d'un tableau.
Choses à retenir pour estimer la complexité d'un programme :
1) On simplifie. Si ça affiche 3 bonjours peu importe l'entrée on ne note pas O(3) mais O(1). On s'en fiche également si ça itère 2 fois ou 15 fois (à la suite, sans imbrication) sur le tableau, c'est O(n), pas O(n+n). Par contre si ça itère de façon imbriquée, on si l'entrée se démultiplie, la diff est tellement grosse qu'on aura des notations comme O(N²).
2) Si le programme mélange plusieurs (par il fait une opération sur l'entrée puis n opérations dessus) , on choisit la PIRE. Avec Big O, on veut exprimer le PIRE temps possible. Par exemple si on veut écrire une fonction de tri, on imagine que le tableau en entrée est dans le PIRE désordre possible.
O(1) n'est pas non plus le saint graal. Il vaut peut être mieux une fonction qui mettent 4ms mutiplié par le nombre en entrée qu'une fonction qui met 3h à s'exécuter peu importe l'entrée.
Néanmoins en géneral on considère que O(1) c'est très bien, O(log n) bien, O(n) moyen et les autres à éviter absolument.
Il y a la même notion pour "l'espace", la mémoire consommée. Si on a un tableau qui grossit autant que l'entrée, on sera sur du O(n). Si la mémoire du programme reste la même quelque soit l'entrée, on est sur du O(1)...
Large language Model, désigne un générateur de texte, fonctionnant avec un réseau de neurone, entrainé sur une très grosse quantité de texte. Il peut compléter du texte, c'est à dire qu'on lui donne un "prompt" (du texte, par exemple : "ce matin, nous irons") et il va compléter (par exemple avec "au bois") selon des probabilités calculés d'après un corpus de texte.
Il est possible de le rendre plus créatif en modifiant la temperature (plus elle est haute, plus il aura de chances de choisir des mots aux probabilités moins élevées).
Néanmoins il semble pouvoir faire des calculs sur des chiffres jamais vus (alors qu'il n'est pas prévu pour), des déductions sur le temps (si je pars à xh et que j'ai xh de trajet...).
Connaissances générales :
-What's the biggest bookstore in XXX ?
-Who was the first king of France ?
Représentations du monde :
-I take a blue cube from the top of a yellow cube and put the blue cube on a red cube. There's also a black cube in the room. What's under the blue cube? (2023: GPT4 échoue, supercot-ggml-model-q4_0 autrement dit llama 30B réussi parfois).
GPT4 réussi plus souvent avec ce prompt : I take a blue cube from the top of a yellow cube and put the blue cube on a red cube. There's also a black cube in the room. What's under the blue cube? Please write a paragraph explaining your process of deduction and thoughts before giving an answer.
-A man has 5 red balls and 7 blue balls. He wants to arrange them in a row such that no two red balls are adjacent to each other. Show me some ways to arrange them. (2023: chatGPT échoue, il met trop de balles).
Théorie de l'esprit :
-Anna takes a ball and puts it in a red box, then leaves the room. Bob takes the ball out of the red box and puts it into the yellow box, then leaves the room. Anna returns to the room. Where will she look for the ball?
Calculs :
-I have one hour and 12 minutes of commute. I leave home at 7:14. However, there is 10m minutes roadblock today. What time will I arrive today?
Art :
-Write a 4 lines poem about cheese, it must rhymes and have 8 syllables per lines.
Détection du n'importe quoi :
-What is a pokhfino?
Pour lancer un programme :
Pour compiler un exe :
La fonction main est le point d'entrée.
Dans les classes, les méthodes/attributs qui commencent par une lettre majuscule sont publiques, sinon privées.
Pour déclarer les variables, := est utilisé à la première initialisation :
Ce qui revient au même que :
Il n'y a pas d'héritage mais on peut créer des types personnalisés :
On peut découper une chaine comme ça :
Vérifier si un nombre est pair ou impair :
Trouver le plus grand nombre d'un tableau :
Saisie de nombres et addition à la fin :
Fonctions :
Pas d'héritage en go mais on peut leur donner comportement qui vont les lier à une interface :
Fonctions en python :
Le modèle transmissif consiste à donner des informations à l'élève, comme s'il était un contenant à remplir. Ca fonctionne chez certains élèves, qui apprennent par coeur des faits et sont capables de les sortir par la suite, mais ce n'est pas très intéressant car l'élève se contente de répéter ce qu'il a appris. Il faut que la communication prof->élève soit parfaite, ce qui semble impossible car la langue est ambigüe. L'élève peut aussi déformer les informations reçues en fonction de ses conceptions préalables du sujet.
Le modèle constructiviste suppose que le savoir doit être reconstruit, reformulé par l'élève pour être assimilé. Popularisé par Jean Piaget qui parlait également de "schèmes" : une action (ou suite d'action) reproductible et combinable avec d'autres schèmes. Ils peuvent évoluer avec le temps. D'après ce que je comprends, ce sont des outils qu'on acquière et qu'on l'on va utiliser par la suite (il peut s'agir d'un réflexe face à une certaine situation, une manière de faire quelque chose...). Il faudra parfois aider les élèves à secouer d'anciens schèmes, c'est à dire, leur faire remettre en question les outils qu'ils utilisent si on les juge mauvais.
Le socioconstructivisme ajoute l'idée de l'importance de l'environnement social : on apprend mieux entouré d'élèves (entraide, émulation...).
L'étayage, c'est l'assistance du formateur permettant à la personne formée d'arriver seule à résoudre un problème qu'elle ne savait pas résoudre au départ. Autrement dit, aider pour que la personne devienne autonome.
Aaptation d'un environnement de travail pour optimiser le confort, la sécurité et l'efficacité d'un système à ses utilisateurs.
Un site est ergonomique s'il peut répondre efficacement aux besoin de ses utilisateur en leur fournissant un confort de navigation. Peut être évalué avec le taux de rebond (un utilisateur entre sur le site et quitte immédiatement), ce qui signifie que le référencement, ou le contenu ou que l'ergonomie ne sont pas bons.
Prendre en compte : les attentes de l'utilisateur, ses habitudes, son âge, l'équipement avec lequel il visite le site, ses compétences informatiques.
Conseils pour un site ergonomique : sobriété (simplicité, le site doit être peu chargé), peu chargé (pas de gis animés dans tous les sens), lisibilité (clair et structuré, texte suffisamment aéré et structuré avec paragraphes et titres de différents niveaux), organisation générale du site (infos les plus demandées en haut de page), règle des 3 clics (toute information doit être trouvée en 3 clics), repérage (l'utilisateur doit se repérer sur le site, header consistant sur les pages, homogénéité éléments de navigation au même endroit sur les pages, charte graphique homogène -mais on peut changer des couleurs pour séparer les sections), liberté de navigation (retourner facilement à la page d'accueil), tangibilité de l'information (connaître la date du mise à jour et le nom de l'auteur), ne pas proposer des liens qui affichent des pages en travaux (cacher les liens vers ces pages), temps d'affichage doit être inférieur à 15s (images optimisées en taille, toujours affichées en taille réelle -pas de redimensionnement), facilitation des échanges avec le visiteur (recueil de leurs impressions), adaptabilité (laisser à l'utilisateur la possibilité de personnaliser le site en redimensionnant les polices par exemple, site responsive), adapté aux non et mal voyants (balises adaptées, légendes sur les images, contraste fort, couleurs adaptés aux daltoniens, information accessible sans feuille de style.
Interface : le point des échanges entre l'homme et la machine, on aura une partie matérielle (écran, clavier, souris...) et logicielle qui vient entre les concepts et l'utilisateur.
Il y a 4 étapes pour architecturer l'information qu'on va présenter au visiteur :
-L'organisation : énumérer (toutes les informations qui seront dans le site), catégoriser (on tri ces infos), structurer (classer par ordre d'importance et faire des dépendances entre les infos). Equilibre entre trop d'infos dans une seule catégorie et trop de catégories qui pourraient perdre l'utilisateur.
Par exemple, pour un site e-commerce on liste tout ce qu'on va vendre, puis on classe par catégorie puis on décide ce qui est mis en avant (le plus vendu, ou les promos, etc).
-Etiquetage (la manière dont les éléments sont nommés, par exemple le menu). Utiliser le texte au maximum.
-Le système de navigation (comment on va naviguer sur le site, outre le menu). L'utilisateur ne devrait pas avoir à cliquer sur le bouton précédent du navigateur. Eviter les menus déroulants car ils obligent l'utilisateur à mémoriser ce qui se trouve sous le menu et imposent un mouvement précis de souris.
-Système de recherche (moteur de recherche dans le site).
Important de fixer l'objectif du site web. Site vitrine, e-commerce, institutionnel, outils web, blogs, site personnel, communautaire, wiki...
Les outils métiers sont maintenant migrés vers le web ce qui offre plusieurs avantages : accès facilité, support des périphériques mobiles, standardisation des interfaces, des outils, mises à jour simplifiées.
Le retour sur investissement : dans une situation A que l'on peut mesurer avec indicateurs qualitatifs/quantitatifs -> on fait un investissement -> je suis alors dans la situation B que l'on mesure à nouveau avec les indicateurs de A -> on calcule la différence entre les indicateurs de A et B pour savoir si l'amélioration est positive.
Il est difficile de mesurer les différences en ergonomie par manque d'indicateurs et de mesures factuelles. Souvent des investissements ne sont pas faits car la situation n'est pas critique.
On peut arguer que la mise en place d'une meilleure ergonomie a fait gagner de l'argent grâce à la productivité (plus facile d'utiliser le site métier) ou la vitesse grâce à laquelle les clients achètent leur produit. Un autre indicateur est l'évaluation de la satisfaction client.
Point clef : l'indicateur de la situation de départ. Se baser sur lui et ne pas être uniquement réactif à ce qui se passe sur l'instant t.
Règles d'or en ergonomie :
On a tendance à se focaliser sur les couleurs, logos, éléments... Mais pour améliorer le taux de conversion (le pourcentage des utilisateurs qui font un achat sur le site).
1)Viser la simplicité : pas plus de 7 grand maximum. Police lisible, pas plus de 3 fonts différentes et pas plus de 3 tailles différentes.
2)Mise en place de hiérarchie visuelle : le regard du visiteur doit être capté par les éléments les plus importants, position, taille couleurs.
3)Système de navigation intuitif. Afficher un menu de navigation clair, menu de navigation dans le footer, fil d'ariane, moteur de recherche interne, pas trop d'options de navigation, arborescence à 3 menus maximum
6)Respecter les conventions/standards du web actuel (menu de navigation, logo -qui renvoie vers la page d'accueil- en haut de la page, apparence des liens survolés changent).
7)Le site doit donner confiance. En respectant les conventions vues plus haut, affichant les mentions légales, les prix.
8)Se mettre à la place de ses visiteurs. Tests utilisateurs à distance (Evalyzer), utiliser des outils d'analyse de comportement (crazy egg), demander des feedbacks aux visiteurs.
Listes de critères ergonomiques : Critères ergonomiques pour l'évaluation d'interfaces utilisateur (JM Bastien et D Scapin), S. Ravden et G. Johnson, J. Nielsen adapté au web par K.Instone.
Analyse de la demande : pilier de l'intervention ergonomique. Quels sont les besoins qui motivent cette demande ? Quels sont les objectifs de l'application ? A qui le site s'adresse-t-il ? S'il s'agit d'une refonte, a-t-on des retours des précédents utilisateurs ? A ce stade là, il ne faut surtout pas oublier les utilisateurs.
On fait va faire valider nos maquettes par le client puis travailler sur le projet. Le cahier de recette va répertorier les différents scénarios d'utilisation du site (par exemple un fichier excel où on renseigne les étapes que l'on veut tester par type d'utilisateur).
Puis plusieurs étapes pour les tests utilisateurs : identifier la cible utilisateur et ses caractéristiques, identifier les objectifs des utilisateurs, recruter et prendre rendez-vous avec les utilisateurs, préparer le plan de test en fonction des objectifs d'utilisabilité, préparer pré et post questionnaires, développer le matériel de test, pré-tester avec un ou deux utilisateurs, conduire les tests, analyser les résultats.
Personas : archétypes utilisateurs (par exemple mère de famille, homme d'affaire...). Aident la prise de décision.
Tri par carte : exercice pour catégoriser. On a donne à chacun des membres un paquet de cartes identique qu'ils doivent classer. Les cartes représentent les rubriques du site. Utile pour Voir que chacun a sa propre façon de classer.
PMI : Project Management Institute (certifiant les gestionnaires de projets -informatiques et autres).
Il faut se poser la question : pourquoi est-on en train de programmer ? Chaque développeur doit se la poser. Tout d'abord, il faut comprendre ce qu'on a à faire puis mettre en place la méthode (agile ou autre). Tout ce qu'on fait en informatique, c'est pour une raison. On peut conduire une voiture avec un passager qui donne les directions sans savoir où on va, mais on ne sera pas à l'aise. Il faut une vision globale (quelle est la destination...). En tant que développeur on doit faire appel à notre bon sens et se mettre à la place de l'utilisateur au delà du cahier des charges. Il donne la ligne directrice de ce qu'on doit faire. Ne pas oublier que les utilisateurs se considèrent comme des informaticiens et on tendance à empiéter sur notre domaine d'exercice alors qu'ils devraient se limiter à ce qu'ils souhaitent obtenir. Le programmeur doit comprendre l'entreprise avant de programmer.
Système d'information : l'ensemble des composants physiques ou logiques interconnectés afin de produire de l'information pour la prise de décisions. Ceux pour qui on travaille ne pense pas en terme d'affichage, de réseau, de processeur... Matériel+logiciel+données+procédures+acteurs.
Par exemple : le système financier d'une entreprise qui va constituer le compte de charge, de produits.
L'entreprise va ainsi voir si elle a atteint ses objectifs avec des éléments factuels, ce qui va lui permettre de prendre des décisions.
Pour le développeur, il faut être objectif : quels sont les tests unitaire, de non-regression, combien de temps ça a pris pour faire telle ou telle chose... On doit donner des chiffre, pouvoir faire un rapport synthétique.
CASSIOPEE : logiciel développé pour centraliser la gestion de la justice (synchroniser les juridictions), voir le rapport de l'assemblée nationale 3177. Les projets informatiques respectent rarement les délais et aboutissent rarement correctement.
Ce n'est pas un programmeur qui décide où placer les boutons de l'application, ça doit se faire avec l'utilisateur.
Pourquoi on le fait, à qui on s'adresse, quels sont les enjeux.
Pour Cassiopee ils ont utilisé une méthode de gestion de projet en V, sans écouter les clients pendant le développement du projet. La structure était pas suffisamment souple pour prendre en compte les constants changements legislatifs.
Les commerciaux vont travailler contre nous. Il faut mettre les commerciaux devant leurs responsabilités et prévenir quand ils ont vendu des choses impossibles.
Tierce maintenance applicative : des personnes vont maintenir le code.
L'utilisateur est incapable d'écrire un cahier des charges. En général il énonce ce qu'il veut et quelqu'un va rédiger le cahier des charges à sa place (il y a des entreprises spécialisés). Il faut se méfier du cahier des charges, prendre du recul, analyser les interactions possibles, voir au delà. Penser à la documentation et la formation utilisateur.
Voir aussi projet CHORUS (informatique financière). La France est un des rares pays à être géré comme une entreprise, on sait exactement ce qui entre et sort.
Un projet s'intègre dans la stratégie de l'entreprise pour lui permettre d'atteindre ses objectifs. Un projet est limité par rapport à un domaine spécifique qu'il convient d'identifier. Par exemple pour la gestion de la bibliothèque (la ville).
Conférence sympa sur kanban :
https://www.infoq.com/fr/presentations/inversion-controle
Burndown : un graphique avec une ligne indiquant combien d'heures il nous reste avant de finir. En pointillé est indiqué ce qui serait attendu.
On ne peut pas appliquer Agile si l'utilisateur ne peut pas se rendre disponible.
Une méthodologie qui permet de mettre en place l'agile, voir scrumguide.org.
4 rôles chez ceux qui appliquent Scrum :
-Stakeholders, les gens qui ont un intérêt pour le résultat produit par l'équipe. Le client souvent, mais pas forcément -par exemple si c'est une startup qui commence et n'a pas encore de client. Ca peut être aussi des régulateurs qui cherchent à faire respecter un process qualité ou légal. Ca peut être la structure qui emploie l'équipe des devs (SSII par exemple). Ca peut être des experts que l'on va consulter. Ou de façon plus générale, "le métier".
-L'équipe qui produit les résultats attendus par les précédents (généralement les devs/testeurs).
-Product Owner (PO) qui fait la liaison entre les 2 précédents. Il peut être davantage côté client, davantage côté équipe prod, il peut y avoir aussi y avoir 2 PO. Comme c'est un travail conséquent, on peut aussi avoir une équipe PO qui réponde à un PO principal.
-Scrum Master qui est dédié au bon fonctionnement de l'équipe.
2 cadences :
-Daily meeting (="daily scrum") tous les jours, moins de 15 min (on a fait quoi hier, on va faire quoi jusqu'au prochain daily meeting, ça peut être aussi simple que "j'ai bien avancé sur les tickets et je continue demain"). Rassemble toutes les personnes qui interviennent sur les tickets depuis le démarrage de leur dev jusqu'à ce qu'ils soient terminés, donc souvent devs+testeurs.
-Sprint, de 1 à 4 semaines (avec une revue du sprint et de ce qui a été livré par les Stakeholders et le PO -max 4h, retrospective sur le fonctionnement de l'équipe pendant le Spring, planning pour préparation du prochain sprint -maximum 8h). Débute immédiatement après le précédent. Il peut être annulé.
3 artefacts :
-Le produit incrémenté (le résultat du travail de l'équipe).
-Le backlog du produit (liste des fonctionnalités -"ticket", "stories"- que les stakeholders veulent rajouter dans le produit).
-Le backlog du sprint (liste des fonctionnalités qu'on veut mettre en place dans ce sprint).
Le PO (et son équipe d'assitants PO) prioritise les tickets, modifie le backlog, explique les tickets et la backlog, valide les éléments réalisés.
L'équipe de dev/test pose des questions aux PO pour s'asusrer que les tickets soient clairs, ils font une estimation des tickets, s'engagent sur le développement à une certaine date, font le dev, pour que les tickets passent au statut réalisé et livrent le produit. La définition de ce statut "terminé" est variable : ça peut être juste le dev, ça peut comprendre jusqu'aux tests finaux, rédaction des docs, etc (on parle de Definition Of Done), et on ne réouvre jamais un ticket fermé ! L'équipe doit rester la même tout le sprint, ne pas dépasser 9 personnes. Elle doit s'organiser toute seule pour savoir qui développe quoi. Généralement elle développe des règles d'équipe pour résoudre les conflits.
Burndown chart : une courbe qui représente le travail restant dans le sprint. Suit la date à laquelle les tickets sont fermés. Par ex 1ère semaine il reste 12 tickets à faire, 2e semaine il devrait rester moins de tickets mettons 8 et 3e semaine 4, donc le graphique descend de 12 à 8 puis 4. C'est pour ça qu'il est très important de mettre à jour ses tickets et diviser ses travaux en petits tickets d'un ou deux jours. Généralement sur chaque ticket on met un point d'effort et on se base sur ces points d'effort.
Refinement/grooming : les questions réponses / analyses / cadrages pour passer les tickets à ready (juste avant le dev). Il doit être terminé avant le début du sprint. Quand on dev le sprint 4 (par ex), il faut que les tickets du sprint 5 soient déjà refinés.
Langage de modélisation unifié, proposant de nombreux types de diagrammes couvrant différents aspects du développement logiciel. L'écriture de code n'est qu'une petite partie de la réalisation d'une application, il existe d'autres étapes comme : comprendre le besoin, définir l'architecture de l'application, tester, suivre les besoins, effectuer la maintenance, écrire la documentation d'installation/d'utilisation/pour les développeurs...
Modèle : représentation, à différents niveaux d'abstraction et selon plusieurs vues, de l'information nécessaire à la production et à l'évolution des applications.(UML 2 pour les développeurs) Plusieurs vues pour une même application (vue des utilisateurs, vue technique, vue des données par exemple). L'ensemble doit être cohérent.
Dans l'idéal, le modèle devrait permettre la génération de code, il devra donc être aussi détaillé que celui-ci. Mais il contient des informations qui vont au delà du code (cas d'utilisation, déploiment...) donc le modèle devra être davantage détaillé que le code.
Le langage évolue souvent, actuellement on est arrivé à 14 diagrammes, chacun étant une vue partielle du modèle à décrire.
Modéliser la structure des différentes classes d'une application orienté objet ainsi que leurs relations.
Classe : définit la structure d'un objet et permet la construction d'instances. Se représente avec le nom de la classe dans un rectangle.
Les cardinalités sur les liens sont inversées par rapport à Merise, ci-dessous un joueur peut incarner 0 ou plusieurs personnage et un personnage ne peut être incarné que par un seul joueur:
Joueur-1----incarner----0,*-Personnage
Les classes abstraites sont notées en italiques.
Pour les attributs et les méthodes, la visibilité peut être indiquée :
Souligné = statique, italique = abstraite, tout en majuscule=constante (ce sont des conventions UML 1.4, en UML 2.0 c'est laissé libre).
Propriété/attribut : se représente dans le rectangle, sous un trait qui sépare du nom de la classe, de la forme nomAttribut : typeAttribut. S'il s'agit d'un tableau, d'une liste, ou généralement d'un entre crochets à côté du type (certains le mettent à côté du nom de l'attribut), on peut indiquer le nombre maximal/minimal. Un $ précédent le nom indique qu'il s'agit d'une constante, un / indique une propriété dérivée d'autres attributs (par exemple l'attribut nomComplet sera dérivé du nom et du prénom).
Méthode : se représente dans le rectangle, sous un trait qui sépare des attributs. [visibilité] nomDeLaMethode(parametre) : typeRetourné. Les méthodes statiques sont notées nomDeLaMethode():nomDeLaClasse.
Interface : définit un contrat que doivent respecter les classes. Généralement représenté de la même façon qu'une classe mais avec <> noté au dessus (sinon, elle peut se représenter comme un cercle où est noté le nom de l'interface auquel va se connecter un client via un demi-cercle).
Implémentation d'une interface : un trait pointillé entre la classe et l'interface avec une pointe de flèche blanche touchant l'interface.
Héritage : flèche à la tête blanche, au trait continu, entre la classe qui hérite et la classe mère. La tête de la flèche est collée à la classe mère.
Package : un rectangle avec un onglet en haut à gauche où est indiqué le nom du package.
Importation de package : une flèche en pointillée entre 2 packages, la tête de la flèche n'est pas pleine. La flèche pointe vers ce qui est importé. Si A import B : A -----> B
Note : un rectangle au coin droit corné attaché à un élément par une ligne pointillée, contenant un commentaire sous forme de texte. On peut écrire "<>" sur la ligne.
Composition : un losange plein au début du lien vers la classe qui agrège, par exemple un losange noir du côté d'une classe "fenetre" jusqu'à une classe "bouton" : si on supprime la fenêtre le bouton joint va disparaître.
Agrégation : un losange vide au début du lien vers la classe qui compose, par exemple "page html" qui sera agrégé avec une image. La suppression de la page html n'implique pas la destruction de l'image.
Stéréotype : Entre 4 chevron <>, se place sur un élément pour donner une indication supplémentaire. Pas de définition formelle, on est libre de mettre ce qu'on veut. Permet d'étendre les possibilités d'UML.
Permet de lister les fonctionnalités du système. On aura un ou plusieurs acteurs, représenté avec un bonhomme bâton avec le nom en dessous (par exemple l'utilisateur, l'administrateur, le gestionnaire...) qui est relié à une action (verbe dans une bulle) avec un trait (gérer les livres, gérer les utilisateurs etc). Les utilisateurs peuvent hériter les uns des autres avec un lien de l'enfant vers le parent terminé par un triangle blanc (comme pour le diagramme de classe). Les actions sont regroupées dans des boîtes avec le nom du système au dessus.
Si le cas d'utilisation nécessite un 2e acteur
Les utilisateurs peuvent aussi être représentés un peu comme des classes, on le fait souvent lorsqu'il s'agit d'utilisateurs non-humains. Exemple : commercial----acheter----système bancaire
Entre deux actions, on peut mettre une relation "include" (flèche pointillée du parent vers l'enfant), pour dire que l'une inclus l'autre : en gros on extrait une sous-action de l'action. On peut également mettre une relation "extend", si on veut lier une action à une autre en disant qu'elle peut être effectuée.
On peut détailler ces cas d'utilisations avec des sous-bulles, voir des sous-sous-bulles.
Dynamique, illustre le temps qui passe et les interactions entre les objets.
Typiquement, on a plusieurs "lignes de vie", en pratique des lignes verticales pointillés avec dans une boite au dessus le nom de l'instance. Sur ces pointillés on aura des rectangles indiquant le temps passé. Entre les lignes de vie on aura des flèches où seront notés les méthodes. On peut entourer de cadres indiquant des loops, des switchs...
Le diagramme de séquence peut être très simple, juste illustrer un enchaînement pour arriver jusqu'à une activité.
Par exemple, pour l'activité "suppression de compte" on part du moment où l'utilisateur touche le clavier jusqu'à l'action "suppression de compte". On pourra ainsi avoir envoie de "demande de connexion" renvoie de "page de login", puis "envoie infos de connexion", puis "envoi de la page d'accueil une fois connecté", puis "suppression du compte".
Il pourra aussi être très détaillé pour qu'on puisse s'en servir dans l'équipe, illustrant la création et la destruction d'instances.
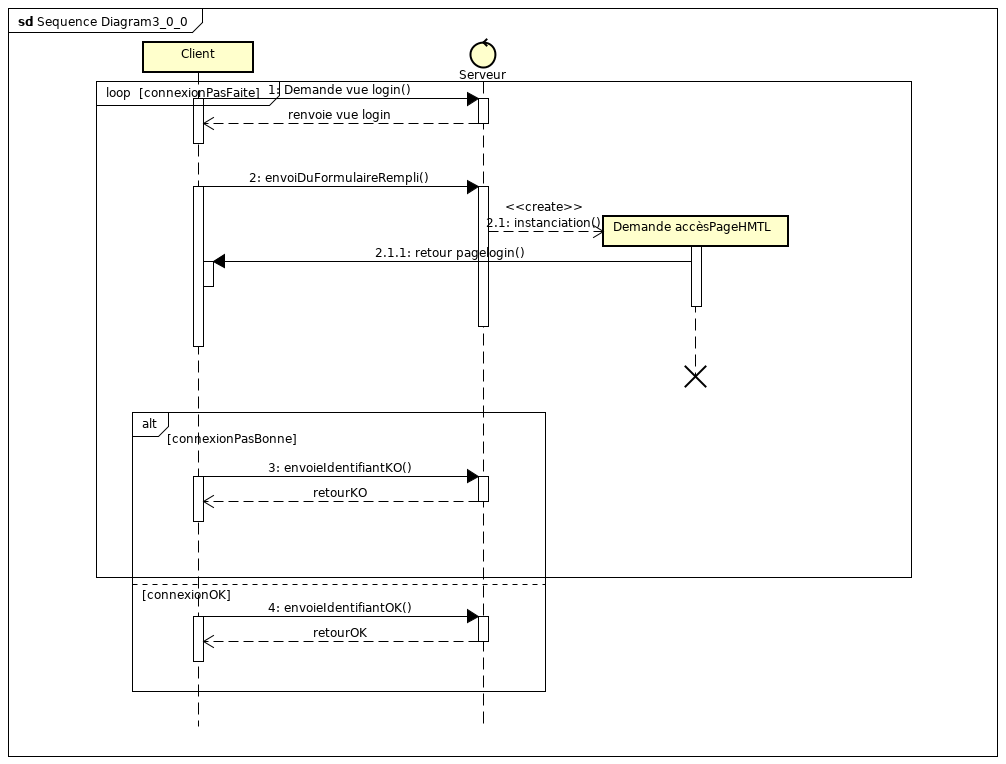
Diagramme de comportement, dynamique. Ressemble aux algorithmes représentés en logigrammes. Un point noir au départ, des activités (texte dans des boites aux coins arrondis) chaînées avec des flèches, des losanges pour les prises de décision, des rectangles noirs pour des routes parcourues en même temps (threads différents finalement), un point noir au centre d'un rond noir à l'arrivée. On peut avoir un "sous diagramme", une boite contenant un diagramme d'activité, avec les entrées sur une étiquette à gauche et les sorties sur une étiquette à droite.
Un rond avec une croix indique la "fin locale de flux", càd terminer un thread.
Région interruptible : un carré en pointillé qui entoure tout un logigramme. Une étiquette indique une action qui peut interrompre tout le processus dans le pointillé, typiquement "annuler" (elle même sera le début d'un autre logigramme qui sortira du pointillé).
On peut mettre des carrés pour l'entrée de données, par exemple pour l'activité "vérifier infos", on pourra avoir deux boites "nom d'utilisateur", "mot de passe" en entrée.
On peut donner des régions (parfois appelées "couloirs") aux diagrammes, des boites avec un nom au sommet entourant les actions, pour indiquer que toutes ces actions concernent le client, toutes ces actions concernent le serveur, etc.
Au lieu de mettre les actions dans des boites aux coins carrés, on peut les mettre dans des boites avec un bord en forme de flèche
Représentation des parties de l'application liées les unes autres autres, utilisé pour éviter de parler de classes ou package, utile pour le reverse engeneering. Quand on a perdu la doc du logiciel, on pourra utiliser ces diagrammes pour la reconstituer.
Un composant est une boîte avec son nom et un pictogramme à droite (3 rectangles évoquant une sorte de cahier). On peut avoir des composants dans des composants.
Un composant utilisera celui vers qui il pointe une flèche en pointillées (il y a parfois écrit "utilise" sur le lien).
On aura des interfaces, soit représentées avec un rond, soit une boite où sera noté "interface". Le client vers l'interface (celui qui aura besoin des services) y sera relié par une flèche en pointillée dont la flèche (pas pleine) sera du côté de l'interface.
Le service qui offre l'interface est connectée à elle avec une ligne en pointillée et un triangle plein vers l'interface (on peut aussi avoir un rond en guise d'interface et un demi cercle qui s'y connecte depuis le client).
Sur les composants on peut dessiner des petits carrés qui seront des ports, par exemple sur un composant on aura un petit carré "port web" qui sera connecté à une interface REST.
Sert à décrire la structure physique sur laquelle sera déployée l'application. Par exemple un PC, un serveur, un routeur, etc.
On peut utiliser des boites 3D pour représenter les noeuds (machines etc) ou bien carrément des représentations graphiques de PC, serveurs, imprimantes... Les logiciels sont appelés des "artefacts", des carrés avec <> noté en haut et le nom du logiciel en dessous. Il y a des cardinalités sur les liens.
Autrefois c'était le diagramme de classe avec des icônes stéréotypées.
Regroupe n'importe quel type d'élément UML.
On va souvent y mettre des morceaux du diagramme de classe. Pour montrer qu'un package est à l'intérieur d'un autre, on les mettre directement dedans ou utiliser un lien avec un rond au bout. Ci-contre lang est dans le package java : lang-----ojava.
Une flèche en pointillée indique les dépendances : A<---import----B
Un trait plein indique une association entre deux classes dans les packages, mais on peut également avoir des notions d'héritage avec un lien et un triangle blanc ou bout, ou d'interface avec un lien pointillé et une flèche blanche également.
Diagramme de comportement, dynamique, représentant le cycle de vie d'un objet. Un état représente un instant dans la vie de l'objet. Utilisé surtout pour les objets variant selon les stimulis extérieurs.
On aura les états de l'objet dans des boites arrondies avec un verbe à l'infinitif (créé, bloqué, renseigné...) et des liens entre les états sur lesquels seront écrits les évènements qui font passer d'un état à l'autre.
On peut donner aux états un traitement, une action qu'ils vont faire : sous le nom de l'état on trace une ligne et on va écrire "do/laMethode".
On peut regrouper plusieurs états dans une seule boite (on parle d'état composite), typiquement si dans 15 états on peut annuler, on ne va pas faire 15 liens vers annuler mais mettre tous les états dans une boite et c'est cette boite qui sera reliée à "annuler".
Historique : on peut également utiliser un H dans un rond pour indiquer que l'objet est historisé. Si on a plusieurs états regroupés dans une seule boite
Une transition interne (ou propre) / externe : par exemple, pour un objet panier, si on rajoute des objets et qu'on fait une action à chaque rajout, c'est une transition externe. Une transition interne est par exemple le calcul du prix total (???).
Anciennement diagramme de collaboration. Dynamique, sert à montrer les interactions entre objets. Affiche un peu les mêmes infos que le diagramme de séquence sans la notion de temporalité par contre. On y retrouve plusieurs objets (rectangles aux coins arrondis où sont notés les noms des objets) liés entre eux par des liens surmontés de flèches pour indiquer le sens et de nom de méthodes pour passer de l'un à l'autre. Un n° devant chaque méthode indique l'ordre dans lequel les actions sont effectuées. Les itérations sont représentées avec des étoiles. On peut représenter les conditions avec des lettres (1A, 1B...).
Il y a un autre type de représentation utilisant des ronds soulignés pour les objets, des ronds avec un T tourné de 90° à gauche pour les vues, des ronds avec une flèche pour les contrôleurs (MVC).
Dynamique, permet de représenter le temps de façon chiffrée. Ressemble à un chronogramme. Un cadre (rectangle entourant tout le diagramme) permet de définir la notion sur laquelle on va travailler, par exemple "accès utilisateur". Un texte placé à gauche indique l'objet pour lequel on va tracer la ligne de vie. Les états sont listés en une colonne à gauche devant le nom de l'objet. Sur une l'axe horizontal sera représentée l'échelle de temps. Une ligne évoquant un oscilloscope part de la gauche vers la droite, montant et descendant en fonction des états. Sur cette ligne, on peut indiquer les méthodes qui font passer d'un état à un autre.
On peut placer des contraintes de temps en notant entre accolades, au dessus de la ligne, des intervalles, par exemple |<---{5min}--->|. On peut mettre les contraintes un peu partout, par exemple {avant 18h30} pour parler d'un processus qui doit s'arrêter à une heure précise.
Il existe également une syntaxe alternative où les états sont mis en ligne en bas et répétés.
Une instanciation du diagramme de classe pour donner un exemple du programme à l'instant T. Ressemble donc beaucoup au diagramme de classe. On aura sur les carrés nomDeLaCasse:nomDeL'instance. Peu utilisé, va certainement disparaître.
Ou Diagramme vue globale d'interaction, rassemble plusieurs diagrammes d'activité. Peu utilisé également.
Sert à la configuration du projet. Permet d'étendre les possibilités UML en créant ses propres stéréotypes.
https://www.visual-paradigm.com/guide/uml-unified-modeling-language/what-is-profile-diagram/
https://www.uml-diagrams.org/profile-diagrams.html
Ressemble beaucoup aux diagrammes de classe/package mais on rentre dans le détail des attributs (avec quoi ils s'interfacent etc). On aura une boite pour la classe et des boites pour les attributs, chacun pouvant se connecter à d'autres.
https://www.visual-paradigm.com/support/documents/vpuserguide/94/2585/7193_drawingcompo.html
Pour générer un diagramme de classe avec BOUML :
Nouveau projet, utiliser Java, créer package, créer un class view, class diagram, faire ses classes. Créer une deployement view. Double cliquer sur la class view et choisir le deployement view. Clic droit sur une classe, créer un source artefact. Clic droit sur projet, generation setting, onglet directory.
Choisir repertoire de génération. Clic droit sur le package, propriétés, onglet java, y mettre le répertoire de génération sélectionné et le nom du package. Puis tools, generate java.
Très bon outil, pour générer toutes sortes de diagrammes UML à partir de texte : http://plantuml.com
Exemples :
https://www.planttext.com/
http://www.vogella.com/tutorials/JUnit/article.html
-Test unitaire (ou test case) : un morceau de code servant à vérifier le bon fonctionnement d'une partie précise d'un programme et attendant un résultat précis. Exemple : un controleur doit appeler un service qui appelle un repository qui lit la BDD = on testera uniquement que le controleur appelle bien le service, mais c'est tout, le code du service ne sera même pas exécuté, on vérifie juste qu'il est appelé. Typiquement, un test unitaire teste une seule méthode : si cette méthode appelle d'autre méthodes ou objets, ces derniers seront simulés (on va les forcer à renvoyer telle donnée en sortie si telle donnée en entrée. Par exemple avec Mockito "Mockito.when(monObjet.getNom()).thenReturn("bob");" : on renverra "bob" quand "monObjet.getNom()" sera appelé. Une technique consiste à écrire le test unitaire avant d'écrire le code qui sera testé, c'est du Test Driven Development (ça manque un peu de souplesse je trouve car il faut imaginer ce qui sera codé -autant le coder, donc-, mais pour cadrer certaines règles métier ça peut être pratique). Ne pas confondre BDD et TDD : en BDD (behavior driven development) ce sont en général des non-informaticiens qui donne un comportement. Les TU ont l'avantage de ne pas nécessiter de lancer toute l'appli pour tester un petit bout.
-Test d'intégration / fonctionnel : vérifie le bon fonctionnement de plusieurs composants ensemble, par exemple une méthode qui appelle un objet qui a lui-même une méthode dont il a besoin. Par exemple un controleur doit appeler un service qui appelle un repository qui lit la BDD, le test d'intégration vérifiera les appels à plusieurs de ces éléments, parfois même jusqu'à la BDD en utilisant une BDD simulée. Ou encore, une personne a développée une interface pour insérer des données, un autre une interface pour consulter les données et on fait un test pour vérifier le fonctionnement du tout.
-Test suite : un regroupement de tests, par exemple "tous les tests concernant les factures". Typiquement ils sont lancés automatiquement à chaque build.
-Test fixture : morceau de code pour fixer les conditions initiales du test (variables pré-remplies par exemple).
-Test coverage : la quantité de lignes de code sur lesquels des tests ont été mis en place (attention parfois les tests survolent des lignes mais ne les testent pas, augmentant ainsi le test coverage artificiellement).
-Test de comportement : vérifie qu'une partie du code est appelé (on ne vérifie pas le résultat).
-Test d'état : on vérifie l'état (de la BDD par exemple) après un appel de fonction.
-Test système / de qualification : test avec les données réelles (préprod).
-Test d'acceptation/d'acceptance (si l'utilisateur/le recetteur est satisfait, s'il confirme que ce qui a été livré correspond aux attentes).
TestNG et surtout JUnit sont des frameworks de test java.
Les tests JUnit sont des classes à part, dans src/test/java, notés avec l'annotation @Test. On va utiliser une methode assert, par exemple
Bouchon : données simulées pour qu'on puisse faire des tests (et du dev), par exemple avec un serveur json hébergé sur notre machine si on a pas encore accès à une API.
ISTQB (International Software Test Qualification Board) permet de devenir un testeur certifié. En france, on a le CFTL (Comité Français du Test Logiciel).
Le but des tests est de trouver des défauts, mettre en valeur des anomalies et assurer la qualité.
Erreur : produite par l'humain, elle peut engendrer une anomalie/un défaut dans le logiciel, ce qui va engendrer une panne.
Une anomalie a une sévérité (la dénomination peut varier : bloquante, grave, majeure, mineure, moyenne), une reproductibilité, un état (ouvert, en cours, corrigé, fermée, rejetée), criticité (par rapport au métier, c'est le client et pas le testeur qui la qualifie), urgence (niveau de priorité), un commentaire qui va expliquer le bug.
Il y a 7 principes à connaître pour les tests avant de se lancer dans le plan de test :
-les tests montrent la présence de défaut ;
-les tests exhaustifs sont impossibles (il faut prioriser selon un ordre définit par la gestion des risques) ;
-tester le plus tôt possible ;
-les défauts sont souvent regroupés dans une même partie du logiciel ;
-paradoxe du pesticide : on croit souvent avoir tout couvert alors que non. Les tests doivent être mis à jour/écris continuellement ;
-ils dépendent du contexte ;
-l'illusion de l'absence d'erreur : si on ne trouve pas d'erreur, c'est sans doute qu'on ne teste pas assez ;
Triangle de test :
-tout en bas, plus nombreux, les tests unitaires (qui testent une méthode précise) ;
-Au milieu, les tests d'intégration (comment fonctionnent les objets ensemble) ;
-Tout en haut de la pyramide, les moins nombreux, les tests manuels (on clique manuellement sur un bouton et on vérifie le résultat).
On commence par la préparation :
-Planification ;
-Conception des tests (rédigé par le "test manager", contenant le périmètre à tester, type de tests, environnement de test -bouchons, faux jeux de données etc., une analyse des risques);
-Détermination des critères d'acceptation (critères d'entrée : on va commencer à tester si l'environnement de test est prêt/si tout le développement a été fait, si l'appli a été déployée / critères de sortie : on va arrêter de tester s'il n'y a plus d'anomalie critique);
Puis l'exécution :
-Exécution des tests (on va faire campagne de test regroupés en lotissement, par exemple on teste tel ensemble de fonctionnalité, on aura un résultat effectif et un résultat attendu);
-Résolution des anomalies ;
-Clôture des tests ;
Le plan de test maître donne la stratégie de test globale sur le projet en se basant sur les spécifications détaillées du projet. Il permettra d'établir une matrice de couverture de test et des scénarios de test. Chaque scénario aura un "code scénario", un objectif (l'énoncé du test), un pré-requis (condition en amont dont on a besoin pour effectuer notre tests, des données par exemple), une action à faire de la part du testeur, un résultat attendu. Chaque scénario a plusieurs cas de tests.
Chaque cas d'utilisation donnera un ou plusieurs scénario, qui aura un ou plusieurs cas de tests.
Psychologie des tests :
-Il ne faut jamais reprocher au développeur un certain manque de compétence, il faut communiquer avec lui avec respect. On ne doit pas se servir des tests pour pointer du doigt le mauvais travail de quelqu'un.
Tests statiques : simplement en lisant le code, on n'exécute pas.
Une matrice des exigences permet au métier (aux utilisateurs) de voir que leurs cas d'utilisations sont couverts (4 cas d'utilisation en haut) et nous aide à mettre en place les tests :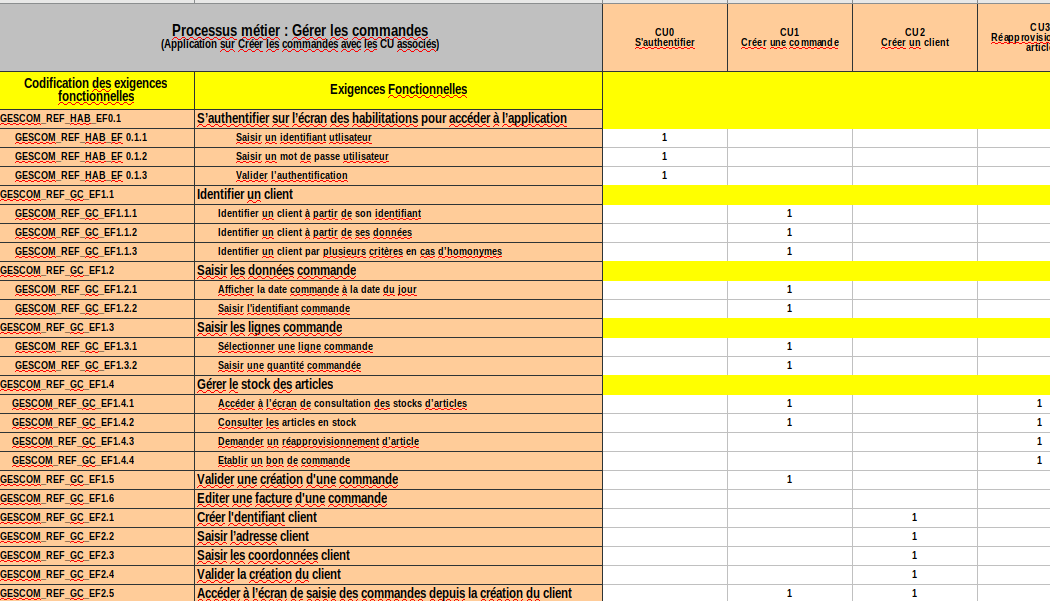
Le cahier des charges fonctionnel va donner naissance à la matrice des exigences (aka matrice de couverture fonctionnelle) et il va également donner les spécifications fonctionnelles détaillées. Ces deux éléments vont donner le plan de test.
Il faut distinguer les phases de test (aussi appelé "niveau de test") et les types de tests.
1) Tests unitaires (faits par les développeurs) ;
2) Tests d'intégration (faits par une équipe de testeurs, intégration applicative/inter-applicatives) ;
3) Tests système (ou "de qualification", "d'homologation", tests avec une volumétrie conséquente, par exemple une copie de la BDD de prod, souvent faits par une équipe de tests indépendante et impartiale) ;
4) Tests d'acceptation utilisateur (UAT, User Acceptance Test, c'est la "recette fonctionnelle" ou VABF : vérification d'aptitude au bon fonctionnement. Il y a aussi la VSR "Vérification du Service Régulier" où l'application est mise en production sur un site pilote pour être testé on parle aussi de validation d'exploitabilité-par exemple pour une application sur les imports on peut tester sur un seul département pilote).
-Test fonctionnel (Des fonctionnalités souvent métier. Par exemple dans le domaine de la banque, on va tester si on peut créer un contrat, créer un client... mais aussi l'authentification utilisateur par exemple).
-Test non-fonctionnel (Performances, tests de charge -si on a énormément de requêtes sur notre application, tests de portabilité -Linux/Windows, ergonomie...)
-Test structurel (ou "boîte blanche", l'inverse de la boîte noire, on regarde les bifurcations du code, les instructions, les décisions, les branches... Quand on fait du test unitaire, on est en "boite blanche").
-Test lié au changement (tests de confirmation -on vérifie que ce que dysfonctionnait précédemment fonctionne à présent, et de non-régression -on vérifie qu'il n'y a pas de bugs introduits avec notre nouveau code).
-Test de maintenance (migration de données, changement de plateforme, évolution de l'application, ou quand on a un bug remonté par un utilisateur après la MEP).
On parlera de decision (si quelque chose, alors...), branch (le déroulement après une décision) et statement (une instruction).
Plusieurs façons de faire des tests.
En boite noire on aura les concepts de partitions (ou "classe") d'équivalence (par exemple on a un nombre qui doit être entre 5 et 8, on aura 3 classes d'équivalence : moins de 5, entre 5 et 8, au dessus de 8), valeurs limites (borne sup ou inférieure), états transition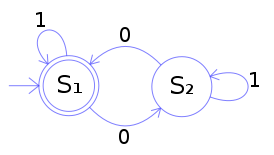 , tables de décision (un tableau), cas d'utilisation.
, tables de décision (un tableau), cas d'utilisation.
http://www.vogella.com/tutorials/AndroidTesting/article.html#androidtesting
2 types de tests pour les applis Android : ceux qui nécessitent de faire appel à l'OS Android (dans app/src/test/java ) et ceux qui ont juste besoin de la JVM (beaucoup plus rapide, dans app/src/test/java).
Conseil 70% de tests unitaire, 20% fonctionnels et 10% cross fonctionnels (intégration avec d'autres apps).
Google fourni la librairie ATSL (Android Testing Support Library).
Un repository contient en général les fichiers (texte, images, vidéos...) d'un seul projet, sans les fichiers compilés.
Pour récupérer un projet sur son poste, il faut le "cloner", en récupérant l'url du projet fourni sur la page web de github/gitlab/etc. Puis
Quand on clone on créé un dépôt "local" sur son poste. Si on fait des modifs sur un fichier, il faudra faire un
On peut voir le "git commit" comme un snapshot, un instantané de nos fichiers.
Donc en cas d'incendie :
Il existe aussi
Lors d'un push, notre serveur va demander au serveur distant s'il accepte ou non notre modif.
Le ficier .gitignore permet d'ignorer des dossiers ou des fichiers :
On peut supprimer un fichier du système de version mais le garder localement avec :
Il peut avoir plusieurs "versions" d'un projet qui existent en même temps : la branche master est la branche principale, il peut y avoir une branche pour la fonctionnalité X, une autre pour la fonctionnalité Y... Cela permet de faire des modifs sur le code sans affecter la branche master.
On peut créer une "branche" avec un "git branch mabellebranche" puis se positionner dessus avec
La branche sera dans un premier temps "locale", visible uniquement sur notre poste. Il faudra la pousser à distance avec un
Une sauvegarde d'un changement dans le repository (par exemple un fichier texte modifié) s'appelle un "commit" (un "commit message" est un commentaire expliquant le commit). Chaque commit est identifié par un hashcode. Une branche est un pointeur vers un commit. On peut très bien avoir plusieurs branches qui pointent vers le même commit. La branche pointe par défaut là où on se trouve mais on peut très bien créer une branche sur un commit précis :
Si juste avant de commiter on se rend compte qu'on a travaillé sur master au lieu d'une nouvelle branche, ce n'est pas grave. On peut créer une branche avec
Généralement ça se passe comme ça : on créé sa branche, on travaille et commit plusieurs fois sur cette branche (par exemple à chaque fin de journée). A la fin de son travail, on merge avec la branche principale.
Lorsqu'on a fait un "commit" sur une branche, on peut demander un "pull request" sur la branche principale, c'est à dire qu'on propose (request) que la personne en charge de la branche principale récupère (pull) nos changements.
Pour faire un "merge" de branche, on se met sur la branche où on veut merger, puis
Par exemple, si on veut merger master dans feature_nouveau_bouton, on se met sur feature_nouveau_bouton ("git checkout feature_nouveau_bouton") et on tape "git merge master". Celà modifiera les fichiers de la branche feature_nouveau_bouton en lui ajoutant les modifications de master.
En cas de conflit lors d'un git merge, le fichier en conflit sera modifié avec les sections en conflits indiquées avec des chevrons (>>>>>>). "git status" indiquera que vous êtes en train de merger. Modifier les fichiers pour ne garder que ce qui nous intéresse (soit manuellement avec un éditeur de texte, soit avec un outil comme Winmerge ou l'IDE). Une fois satisfait, ajoutez-les (git add mon_fichier) puis faites un commit.
"git merge --abort" permet d'arrêter un merge et de revenir à l'état initial (juste avant qu'on ait tapé "git merge").
-une branche "nouvelle_fonctionnalité" a été tirée de "branche_principale" en 2019.
-des modifications ont été faites sur "nouvelle_fonctionnalité" en janvier et février 2020.
-des modifications ont ensuite été faites sur "branche_principale" en 2021.
-->Zut, "nouvelle_fonctionnalité" est maintenant en retard sur "branche_principale".
-"rebase" permet de faire comme si "nouvelle_fonctionnalité" venait d'être tirée de "branche_principale" en 2021. Il y a donc une sorte de réécriture de l'historique. En outre, les modifications de janvier et février seront regroupées dans un seul commit.
C'est quelque chose qu'il est déconseillé de faire si "nouvelle_fonctionnalité" a déjà été pushé ! Car la réécriture de l'histoire change les id des commits et ils peuvent être utilisés par un collègue/un outil. Donc à ne faire que si la branche feature est locale !
Notez que l'historique est en fait caché, on peut retrouver le commit original avec
Si on commit par erreur (par exemple, on commit sur master alors qu'on voulait commiter sur une autre branche) et qu'on a pas encore poussé, on peut utiliser la commande suivante pour revenir à l'état juste avant commit :
Si on push par erreur quelque chose, deux façons de faire :
-soit
-soit
On peut aussi reset ou revert en visant un hash de commit.
Si on a ajouté juste un fichier par erreur, on peut faire:
Pour modifier le message de commit, à condition qu'on ait pas encore pushé, il suffit de faire en console :
On ne travaille pas généralement sur la branches master, on utilise d'autres branches qu'on appelle "release/", et sous ces releases, on va bosser sur des branches "features" (une pour chaque fonctionnalité). A la fin, on pourra ainsi embarquer certaines features dans la release et d'autres non. Pour chaque release on pourra aussi avoir une branche "hotfix".
Exercice pour les branches : https://learngitbranching.js.org/
Pour ignorer un fichier après qu'il ait été mis (par exemple on veut pousser une seule fois un fichier de conf avec des infos de login incorrectes, puis on modifie le password localement mais on veut garder le fichier de conf avec login incorrect sur le dépot) :
1)Créez un compte sur gitlab.
2)Créez un repository.
3)Configurer pseudo
4)Mettez vous dans le dossier dont vous souhaitez envoyer des éléments sur git et tapez
5)
6)
7)
8)
Vous pouvez travailler directement sur master mais il est recommandé de créer une nouvelle branche.
1)Créez la branche (sur votre dépot local) :
2)Positionnez-vous dessus :
3)Faites les modifs sur vos fichiers.
4)Ajoutez les modifs :
5)Commitez localement :
6)Poussez vos modifs + la branche locale à distance :
Il y a plusieurs façons de travailler.
Dans tous les cas, on aura une branche master. Certains aiment y laisser la version en prod (mettons v1), d'autres trouvent ça un peu inutile et préfèrent mettre sur le master la version cours de dev (mettons v2).
Mettons qu'on ait la v2 sur le master.
On aura des branches v3 et v4 en cours de dev. Chaque dev pourra avoir sa petite branche, par exemple v3_nouvelle_fonctionnalite.
Il est conseillé d'avoir des branches integration et recette :
-A chaque push sur le master, on pourra avoir un outil comme Jenkins qui va tester, compiler, build, installer les binaires sur un environnement d'intégration et pourquoi pas lancer des tests automatiques d'interfaces avec selenium. Puis, il va commiter vers sa branche integration. Cette branche intégration sert donc à faire des tests automatiques, ce qui est rassurant pour les devs.
-Manuellement, on pourra lancer la livraison en recette pour que les testeurs puissent tester. La branche recette va pull de la branche integration (car les tests automatiques sont passés !) et compiler, installer en recette, et pusher sur une branche recette.
-Enfin, la livraison se fera à partir de la branche recette : on est sûr que tous les tests y sont passés.
Attention cette organisation peut se complexifier si on travaille sur des versions antérieures. Si on veut pousser une version antérieure sur la branche integration, ça peut bloquer car la branche integration est en avance. Pour resoudre ce problème, on peut avoir des branches speciales, par exemple integration_v1.1 / integration_v2 (et du coup recette_v1.1 / recette_v2), ou supprimer carrément la branche integration à chaque livraison...
Voir https://docs.github.com/en/github/committing-changes-to-your-project/changing-a-commit-message.
Si ça n'a pas encore été poussé et qu'il s'agit du dernier :
Si vous voulez annuler toutes vos modifs sur les fichiers et revenir au dernier état (attention, irréversible !) :
Si vous voulez revenir en arrière sur un commit pushé sur la branche distante (si aucun collègue n'a pullé le mauvais commit ça sera trabsparent pour eux) :
Les tags permettent de mettre en valeur des points sur la branches particulièrement important, typiquement sur le commit qui sera livré au client. On est pas obligé d'utiliser des tags étant donné qu'on peut à tout moment revenir dans le passé sur n'importe quel commit. Néanmoins qu'il soit taggé permet de retrouver un commit plus facilement dans la liste.
2 types de tags "légers" ("git tag monBeauTag") et "annotés" ("git tag -a monBeauTagAnnote").
Un tag léger se pose sur un commit déjà existant.
Le tag annoté est un commit à part entière, avec son propre message de commit, son propre auteur etc.
Pour récupérer tous les tags :
Il y a plusieurs façon de stocker le mot de passe/le token git. Dans un fichier (store)
Attention le même mot de passe sera utilisé par tous les repos. En cas de multiple repos :
https://git-scm.com/docs/gitcredentials
"Head" est similaire à une "tête de lecture", c'est un pointeur qui designe là où on se trouve actuellement (la branche, le commit, le tag...). On peut voir son contenu dans : .git/HEAD. "Detached head" signifie que ".git/HEAD" pointe vers un commit et pas une branche. On peut déplacer cette tête de lecture en lui donnant un hash, une branche, un tag mais aussi une commande comme
Pour récupérer des commits précis.
Subversion ("SVN") est un gestionnaire de version pour des projets collaboratifs. Le site riouxsvn.com donne 50mo d'espace gratuit et 4 projets par utilisateurs. L'intégration de SVN est bien faite dans Netbeans.
Sur RiouxSVN, vous devrez créer un repository et récupérer son URL.
Pour mettre un projet sur riouxsvn, clic droit, "versioning", "import into subversion directory". Indiquez l'url et vos informations d'authentification.
Pour récupérer un projet de riouxSVN initialisé par quelqu'un d'autre, dans Netbeans Team->Subversion->Checkout.
Après avoir fait des modifs, clic droit "commit" pour envoyer les informations sur riouxsvb. Si un conflit est détecté, un message vous demandant d'updater s'affichera.
Clic droit sur le projet "update" va récupérer les fichiers de riouxsvn et les mettre dans votre projet. Mieux, si un fichier est modifié des 2 côtés, une fusion de fichiers sera effectuée. Si la fusion est impossible, cela sera indiqué dans le fichier :
Un clic droit "resolve conflit" permet de traiter les problèmes.
SVN est beaucoup plus simple à utiliser que GIT.
Notes persos basées sur le cours https://openclassrooms.com/courses/developpez-votre-site-web-avec-le-framework-symfony
php peut décompresser des fichiers "phar" (équivalent des jar en java, des bibliothèques/liens vers les bibliothèques).
Pour installer symfony, on récupèrera donc le phar présent sur https://symfony.com/installer puis on le met dans "C:\xampp\htdocs" par exemple puis :
/app -> config de notre site web
/bin -> executables utilitaires (on peut manipuler depuis l'invite de commande pour effectuer diverses tâches comme génération de code, création d'utilisateurs, vider le cache -à faire avant de publier le site :
/src -> code source de notre site
/tests -> tests unitaires etc
/var -> repertoire où symfony écrira des fichiers temporaires
/vendor -> bibliothèques externes
/web -> ce qui sera exposé au visiteur. Le controleur point d'entrée est "app.php", il y a également "app_dev.php" qui fait la même chose mais propose en plus des infos de débugs etc.
MVC : Modèle (en gros ce qui concerne la BDD), Vues (mise en forme -les pages html/css), Controleurs (analyse la requête et renvoie une réponse).
Bundle : une brique applicative. On peut imaginer un bundle "blog", "utilisateur", "boutique"... on peut les développer soi-même où en récupérer des déjà faits (http://knpbundles.com/). Les bundles doivent être renseignés dans app/AppKernel.php et le chemin d'accès dans app/config/routing.yml.
/Controller
/DependencyInjection -> informations sur la configuration des dépendances du bundle.
/Entity -> modèles
/Form ->formulaires Contient vos éventuels formulaires
/Resources
-- /config -> config du bundle (routes etc)
-- /public -> css, javascript, images...
-- /views -> vues, templates Twig
Chaque partie du site est un bundle,
Pour créer une page, il faut créer sa route. Le kernel envoie le chemin au "routeur" et celui-ci va vérifier si le chemin correspond à une route qu'il a en stock. Si oui, il renvoie des paramètres.
La route se déifnie dans le répertoire du bundle, dans "Resources\config\routing.yml". On aurait pu ajouter la route directement dans app/config/routing.yml mais mieux vaut la mettre dans le bundle, de plus il est déjà configuré pour analyser les routes de notre bundle comme vu plus haut. Par contre on peut ajouter
Exemple de route (il pourrait s'agir d'un fichier routing.yml complet) :
Dans "path", on peut également indiquer une variable, exemple :
Autre exemple de route, ci dessous on attends un numéro (entre 1 et 4 chiffres comme indiqué par \d{1,4}) de page (monsite.com/3). Sans ce numéro la page par défaut sera la 1 :
Ensuite, il faut créer le controleur dans le dossier "Controller", ici il devra s'appeler "MonControleurController" et contenir une méthode "methodeAExecuterAction". Voici ce que devrait maintenant afficher l'adresse
On peut aussi renvoyer une page html. Symfony 2 et 3 utilisent le système de template Twig. Il faut tout d'abord écrire une page twig dans Resources/views/(adresse que l'on veut, MonControleur pour rester cohérent)/index.html.twig :
Ci-dessous, une page twig avec des arguments (ici, le nom) :
Autre façon de faire avec
Ci-dessous, pour la route
Il est également possible de récupérer les variables de l'URL passées en paramètre en GET (post/5?monparamalancienne=mavaleur), elles se retrouveront dans un objet de type "Request" envoyé en paramètre à la fonction dans le controleur. L'url est http://localhost/Symfony/web/app_dev.php/platform/chemin_dans_barre_d_adresse/param?monparam=mavaleur, l'exemple suivant affichera "mavaleur" sur la page :
Un objet de type Request permet de récupérer les paramètres GET mais aussi POST ($request->request->get('tag')), les cookies ($request->cookies->get('tag')), les variables de serveur ($request->server->get('REQUEST_URI')), les variables d'entête ($request->headers->get('USER_AGENT')), les paramètres de route ($request->attributes->get('id')) et beaucoup d'autres choses.
On peut aussi utiliser cet objet pour manipuler les sessions (et les voir en cliquant sur la barre d'outil en bas en mode dev) :
Pour générer des url dans le contrôleur, par exemple un lien vers la page "contact", on lui indique le nom de la route et il génère l'url à partir du fichier de routing (ce qui permet de ne pas les écrire en dur et devoir modifier 2000 url) :
Pour le faire depuis Twig :
Redirection (pour que les directions soient pluis détaillées en mode dev passer intercept_redirects à true dans app/config/config_dev.yml) :
Il est possible de mémoriser une variable qui sera utilisée en cas de redirection. On appelle ça des "messages flash" :
Pour afficher tous les messages flash dans Twig :
Retourner du JSON :
Les messages d'erreur dans Symfony sont dans
En mettant un fichier error.html.twig dans
Moteur de template utilisé par Symfony. Entre " " pour afficher quelque chose, "{%" et "%}" pour exécuter une commande, "{#" et "#}" pour les commentaires. Pour concaténer :
" pour afficher quelque chose, "{%" et "%}" pour exécuter une commande, "{#" et "#}" pour les commentaires. Pour concaténer :
Voir la doc de twig pour les boucles, les if else, les tableaux...
Pour récupérer le contenu d'un template en texte :
On peut évidemment utiliser des layouts (avec le mot clef "block" qui indique où vont se placer les éléments). Il est conseillé de les faire sur 3 niveaux : layout général du site (à mettre dans app/Resources/views/layout.html.twig), layout de la section (dans src/nomdubundle/resources/views/), layout de la page (dans src/nomdubundle/resources/views/nomdelasection).
Exemple de bloc formant le layout général d'un site :
Et une page qui utiliserait le layout "base.html" ci-dessus, notez qu'il hérite (extends) de base.html :
On peut aussi inclure une page sans qu'elle n'hérite d'une autre :
Exemple qui récupère le contenu d'un tableau et l'affiche :
On peut également appeler une méthode d'un controleur avec render() :
Pour que l'exemple ci-dessus fonctionne, il faudra alimenter la page twig avec le controleur :
doc
Des objets php accessibles depuis n'importe où (pour envoyer un mail par exemple) : il suffit de créer la classe et de l'enregistrer dans le conteneur de service (le fichier
Ci-dessous un service renseigné dans services.yml, avec des arguments (un autre service, un paramètre de l'appli, un nombre) qui seront récupérés dans la méthode de construction de la classe
On peut aussi stocker des variables dans le fichier services.yml (
Un ORM php qui fait le lien entre nos classes modèles avec notre base de donnée grâce à des annotations (entre
Comme en Java, ces annotations peuvent être générées automatiquement.
Il peut être intéressant d'installer le package doctrinebundle.
L'accès à la BDD se configure dans "app\config\parameters.yml", puis, on lance la création de la base avec
Les entités se créent avec un configurateur qui va poser quelques questions. Il se lance avec
Entity shortcut name nom de la classe/(de la table généralement) : MonBundle:MaClasse
Configuration format façon dont sont mappés les attributs de la classe avec les colonnes : annotation
New field name (press to stop adding fields) nom de l'attribut (la colonne): date
Field type [string]: datetime
Is nullable [false]:
Unique [false]:
Le champ "id" est créé automatiquement. Bien sûr vous pouvez modifier le code source php entité (dans src/votre/bundle/Entity) pour y mettre un constructeur par exemple ou modifier le mapping (voir la doc de doctrine) puis
Une fois les classes php générées, on se base sur elles pour créer nos tables dans notre base :
On peut également faire l'inverse : créer ses tables puis les importer dans doctrine.
Création de tableau avec la fonction array :
Directement :
Tableau associatif (par exemple, les variables superglobales $_GET ou $_POST sont des tableaux associatifs) avec la fonction array :
Tableau associatif directement :
Pour parcourir avec foreach :
Avec les clefs :
Boucle for :
empty($var) returne true si var est nul, false, à 0, contient "", "0", un tableau vide.
isset return true si la variable contient quelque chose (si on lui a assigné null, elle ne contient rien).
tableau comparatif
Les variables peuvent changer de type selon ce qu'on met dedans, mais on peut forcer un type avec "settype" ou en faisant un cast, comme en java :
Pour démarrer une session
Pour mettre un cookie en place, tout en haut de la page
Pour exécuter une requète,il vaut mieux utiliser des requêtes préparées qui permettent d'éviter l'injection decode:
Activé par défaut depuis PHP 5.4, on peut faire un
Dans les vues, on pourra donc faire des choses du genre :
Eviter d'utiliser la balise d'ouverture
Attention aussi à ne pas faire des choses du type
Les namespaces permettent d'avoir des classes ou des fonctions du même nom : il suffit d'écrire
Généralement on sépare les fichiers php dans des dossiers et on donne comme namespace le chemin relatif des fichiers.
Pour déclarer :
Pour ajouter :
Permet de mettre des points d'arrêt etc.
Copier coller la vue html sur https://xdebug.org/wizard.php pour obtenir les instructions d'installation.
Gestion de dépendance en php, les paquets sont sur https://packagist.org/.
Il a besoin d'un fichier json, exemple :
...puis, dans la console, on va taper
Un fichier autoload.php va faire charger automatiquement ces librairies à php mais attention, il est écrasé par composer à chaque demande d'upate.
On peut ajouter sa propre librairie à l'autoload de la façon suivante :
Pour lire du css, mieux vaut partir de la droite, par exemple :
⇒ Pour utiliser des pourcentages, par exemple 50% de la page, ne pas oublier de donner l'attribut height à 100% sur html, body et tous les éléments avant.
⇒ Pour positionner un élément en absolu par rapport à un autre, ne pas oublier de préciser le parent en relative.
BEM, une solution pour écrire des classes CSS :
Si on veut faire une boite d'une autre couleur, on va mettre l'ancienne classe plus une nouvelle qui va changer la couleur :
Un menu sur une ligne avec sous-menu déroulants (par contre on peut pas dérouler les éléments avec tab) :
Les éléments de type flottants sortent complètement du flux. Pour y remédier, on peut insérer en dessous une div avec un "clear:both" (cette technique s'appelle "clearfix"), ce qui va interdire les éléments flottants à sa gauche et à droite. Comme il est dessous, la div parent va s'adapter pour inclure ce div "clear", incluant ainsi l'image affichée avant.
On peut aussi utiliser
Donne plus de fonctionnalité au CSS, par exemple l'imbrication :
En css :
D'après la conférence de KAHANE Sylvain.
Une formule peut donner les relations entre les différents éléments de sens :
"Félix veut parler à Zoé." Félix définit comme a ; Zoé comme b;
Premier prédicat "vouloir", qui prend deux argument (Vouloir 1)QUI ? et 2)QUOI ?) :
Vouloir(a,e -e comme "évènement").
Deuxième prédicat "parler" avec trois arguments :
Parler(e,a,b) pourquoi remettre e et a ici ?
La formule complête est :
Deux évènements, e1 et e2. Vouloir(e1,a,e2) et parler(e2,a,b). pas compris
Quand on formalise une phrase, on isole différents éléments de sens, on exprime leur relation et le sens de certains éléments. On a pas décrit tous les mots dans cette phrase.
Exemple avec l'adjectif sec, beaucoup de sens différents (pas mouillé, maigre, froid).
Comment comprendre ça de façon abstraite ? Il existe l'approche du dictionnaire de synonyme Sabine Ploux and Bernard Victorri. Cette approche, c'est de voir que les mots qui représentent un même sens de "sec", parmis ses 56 synonymes, sont synonymes entre eux. sec=aride=décharné=maigre. Autre exemple : autoritaire=brusque=cassant=sec=tranchant.
Ils appellent ces groupements de mots des cliques. Il y en a 75 pour le mot sec. Grâce à ça, on va essayer de représenter le sens global du mot sec.
On va construire un espace à 56 dimensions (pour chaque synonyme) dans lequel on va placer les cliques. Pas d'explication mathématique sur comment ça se passe... Il nous montre ce que ça donne, il a mis au milieu le sens pas mouillé, il y a dans un coin le sens psychologique insensible, autre coin squelettique décharné, dans un autre coin les sens temporels court, bref.
Ensuite, tentative de retrouver le sens de sec lorsqu'il est donné avec un nom. Pour cela, on utilise un corpus de texte. On cherche dans tous ces textes avec quels mots le mot "foin" est associé et à quelle clique ça correspond. Par exemple, foin séché, foin mouillé, foin desseché etc. Ca correspond à la clique d'un certain sens. On aura pas de foin squelettique, ni de foin rapide. On sait donc que lorsque foin est associé avec sec il a le sens de "pas mouillé". Si on fait la même opération avec "homme", on a deux sens, décharné et sens psycho.
Note perso : Je comprends pas pourquoi il a besoin de représentation à 56 dimensions, ça me semble assez simple. on doit pouvoir programmer facilement un détecteur de sens d'adjectif selon le mot avec lequel il est associé.
Il faut d'une part déterminer les cliques, puis les associer avec une définition du dico (via mots clefs dans ces cliques). Puis :
Si dans un corpus (ou sur google tant qu'à faire) le mot clef est souvent associé à tel groupe d'adjectif, alors, sa définition la plus vraissemblable est trouvée dans le dictionnaire d'après les adjectifs en question.
Pourquoi 56 dimensions ?
Ceci dit, l'approche du dico des synonymes est très intelligente. Je suis étonné qu'on trouve pas encore d'application.
Apprend des mots liés à des stimulis.
Exemples de stimulis : quelqu'un arrive, quelqu'un part, quelqu'un reste au délà d'une certaine limite, il est midi, le bot a faim, le bot a soif, on vient de dire un mot précis au bot, on tire la tronche, on va faire une action.
Chaque fois que le bot a faim, on demande "tu as faim ? tu as envie de manger ? C'est l'heure de manger ? il a faim le petit ?" exactement comme quand une mère parle à son bébé. Le bot doit associer les mots qui reviennent souvent "faim" et "manger" à la sensation de faim, puis les réutiliser par la suite.
Il doit également pouvoir (mais peut être est-ce inutile dans un premier temps ?).
Il est fort simple de programmer une longue liste de stimuli, mais pour que ça soit de la vraie auto apprentissage, les stimulis doivent être détectés par le bot.
Quelle est la définition la plus simple d'un stimuli ? Un changement d'un état. Le simple fait que le temps passe est un stimuli. Avoir faim au delà d'un certain point est un stimuli.
Le robot doit donc être capable d'associer un changement d'état à un mot, puis réutiliser ce mot lorsque le changement d'état survient. Ce serait déjà une étape importante, bien que très peu spectaculaire.
"Bot : Faim.
-NON. J'ai faim.
-J'ai faim." ⇒on donne à manger.
"User : J'ai faim." ⇒Il faudrait que le bot nous donne à manger ?
L'étape suivant serait de ne pas connaitre uniquement les mots, mais les stimulus suivant un stimulus, en distinguant les acteurs...
Grammaire : http://jerome.desquilbet.org/pages/85/#2_1
Utilise l'alphabet latin sauf les lettres "h" "w" et "q".
Il existe une lettre en plus : "'", qui se prononce comme ahead. Elle sert à séparer clairement deux voyelles.
La ponctuation se prononce, il y a juste "," (indique exception d'une syllabe) et "." (pause).
Le "e" se prononce "é", le "y" se prononce "e", le c se prononce "sh", le g est toujours dur (ga, gu, go), le x se prononce du fond de la gorge, comme la jota espagnole.
Les mots prennent un certains nombre d'arguments (sumti), comme pour une fonction dans un programme.
Par exemple avec klama (venir/aller) en a 5 : x1 va à la destination x2 depuis x3 par la route x4 en utilisant x5. Pour omettre un argument on utilise zo'e ("qui n'est pas important"). Il y a des petits mots à utiliser pour modifier l'ordre des arguments de klama pour éviter d'utiliser 4 zo'e par exemple. On peut laisser tomber les derniers arguments.
accroire : Faire croire un truc faux à quelqu'un.
adamites : religieux nus et végétariens pour faire comme Adam.
alacrité : Vivacité et enjouement. "Même après son divorce, il a pu conserver son alacrité."
anadyomène : qui sort de l'eau. "J'aime regarder Pamela Anderson anadyomène dans sa fameuse série au maillot rouge."
aporie : difficulté logique insoluble. noeud gordien = pseudo-aporie trouvant une résolution brutale.
Autotélique : "Qui n’est entrepris pour d’autre but qu'elle-même"
avunculaire : Qui a rapport à un oncle ou à une tante.
capirote : La capuche genre Ku Klux Klan.
coruscation : Éclat lumineux vif et passager. La coruscation d'un météore.
cynégétique : qui se rapporte à la chasse.
duègne : Femme âgée chargée de veiller sur la conduite d'une jeune fille ou d'une jeune femme. "Elle ne devrait pas sortir sans sa duègne."
dolent : Qui se sent malheureux et cherche à se faire plaindre.
guigner : Regarder à la dérobée. Guigner le jeu du voisin.
difficultueux : Qui cause des difficultés, est enclin à les faire naître.
dilection : Amour pur et spirituel pour quelqu'un/quelque chose.
entéléchie : parfait accomplissement de l'être.
épigone : imitateur sans originalité, successeur.
hapax : forme raccourcie et désormais usuelle d'hapax legomenon, un mot qui n'a qu'une seule occurrence dans un corpus donné.
ligne de désir : chemins qui se forme naturellement dans l'herbe à force que les gens y marchent.
impéritie : défaut de compétence dans la profession que l'on exerce.
manicheisme : simplificaion excessive notamment sur la question du bien et du mal mais à la base tentative de mélanger le judaïsme, du bouddhisme, du brahmanisme et du christianisme.
orchidoclaste : qui casse les couilles.
palinodie : refuter quelque chose qu'on vient juste de soutenir. Par exemple texte argumentatif en faveur de X où dans la conclusion on réfute toute notre argumentation.
panégyrique : louange, éloge de quelque chose. "J’ai même vu un livre quiportait pour titre : l’Éloge du sel, où le savant auteur exagérait les merveilleusesqualités du sel et les grands services qu’il rend à l’homme. En un mot, tu ne ver-ras presque rien qui n’ait eu son panégyrique. " - Le Banquet (Platon).
Pare-battage : Les bouées bizarres en petit boudin dans les bateaux. Ca se met entre la coque du bateau et le quai.
paternien : religieux qui disaient que la chair est l'oeuvre du démon et donc et donc forniquaient, se baffraient etc.
pelagique : relatif à la mer/haute mer.
Péricope : bout de texte significatif.
phare : vient du Phare d'Alexandrie qui s'appelle Phare à la base car il est sur l'île de Pharos.
plénipotentiaire : Agent diplomatique qui a pleins pouvoirs pour l'accomplissement d'une mission.
prétérition : ou paralipse, figure de style quand on parle de quelque chose dont on ne dit pas qu'on en parle ("je ne vais pas parler de sa cuisine infecte").
psittacisme : répêter bêteùent comme un perroquet sans comprendre.
senestre : main gauche. "Carré dans la cathèdre de la salle des États, il appuie sa tête sur sa senestre, et suit d’un œil éteint la polémique qui agite les grands serviteurs du royaume." (Jaworsky)
sérier : classer en série.
stigmergie : un ensemble d'actions individuelles qui aboutissent à une oeuvre. " Les individus, par stigmergie, font émerger des lignes de désir."
suborner : corrompre "Il ne pu suborner la jeune fille car sa duègne l'accompagnait. Ce qui enleva de l'alacrité au jeune homme."
syzygie : quand 3 objets célestes qui se tournent autour forment une ligne.
velléité : intention qui n'est pas suivie d'effet.
Principalement tiré du programme News Buster sur Canal U.
Les nombres 13 à 19 sont accentués sur la dernière syllabe (thirteen), les dizaines sont accentuées sur la première (thirty).
Syndicate : Groupe de personne. Un syndicat = “trade union”.
ten millions-plus jackpot : Le plus signifie ici "un jackpot de plus de dix millions", pas "10 millions plus un jackpot".
“The 3 types of terror: The Gross-out: the sight of a severed head tumbling down a flight of stairs, it's when the lights go out and something green and slimy splatters against your arm.
The Horror: the unnatural, spiders the size of bears, the dead waking up and walking around, it's when the lights go out and something with claws grabs you by the arm.
And the last and worse one: Terror, when you come home and notice everything you own had been taken away and replaced by an exact substitute. It's when the lights go out and you feel something behind you, you hear it, you feel its breath against your ear, but when you turn around, there's nothing there...”
1 : chase, attack —usually used as a command especially to a dogsic 'em
2 : to incite or urge to an attack, pursuit, or harassment : set sicced their lawyers on me
"I'm siccing Sylvanor's ghost on you!"
En anglais américain, on désigne les états unis d'Amérique comme "she". Comme un navire.
Se lit de droite à gauche.
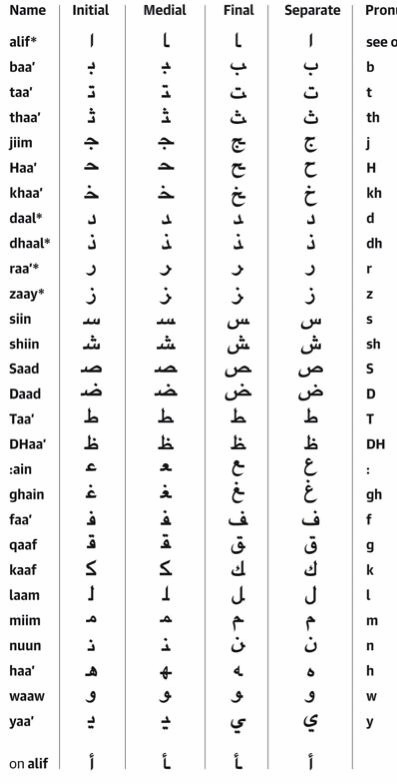
-Attention au daal et au raa (le raa est comme un cRRRochet, le daal est plus plat).
-Attention aussi à alif et laam. Pour les différencier, retenir que le alif n'est jamais attaché à gauche. Si c'est attaché à gauche ou SI ça va CHERCHER l'attachement à gauche (le bas à gauche cherche à s'attacher, même si ya rien ل), c'est un laam !
-Attention au miim et haa' qui se ressemblent (mais juste en début, et le haa' est replié sur lui même). Exemple : مُهُ (muhu).
-Le dhaal (ressemble à un j) se prononce un peu comme un z avec un peu de "th" anglais (translitéré avec un z ou dh).
-Il y a un vrai th anglais, ce sont les 3 petits points en triangle. Prononciation très proche du dhaal mais sans le son "zz", que le "th" !
-Le na a un point en haut, na na na na na batman.
-Le ta a 2 points en haut (pas de boucle sinon c'est q).
-Le vrai J ressemble à un te japonais ou a une vague de quick silver car Jim est cool c'est un surfeur. Il est nul par contre il est en bas de la vague (ou en train de se faire attrapper par le rouleau).
Quand il est plus du tout dans la vaugue, il prend sa respiration ("haaa").
-Le ba a un point en bas, il sert aussi de p (il n'y a pas le son p en arabe normalement mais pour des mots d'origine étrangères ça peut arriver).
-Le khaa' se prononce plutôt "rah" avec le r pas du tout roulé. Ne pas confondre avec le raa qui lui est davantage roulé.
-Le K ressemble vaguement à un K si on supprime la barre du haut à gauche.
-Le Y a deux points en dessous, comme les deux branches du Y qui aurait coulé. Je sais pas ça me fait penser à un bateau coulé.
Parfois (surtout pour les débutants) on met un ` au dessus d'une lettre, ça signifie qu'il faut ajouter le son "a" court (genre s`=sa) mais si on veut un a long faut combiner avec alif (on peut aussi combiner avec un ة pour avoir le son court...). Sur le sh (ش) le ` peut être décalé à gauche.
Si le ` est en bas, il faut ajouter i ,(on peut aussi combiner avec un Y ce qui ferait un long iiii par contre).
Un petit noeud au dessus signifie d'ajouter u (pareil on peut combiner avec و pour avoir le uuu).
La sorte de petit 3 c'est répéter, butter sur la consonne. "lubb-ii".
Enfin le petit ° signifie qu'il n'y a pas de voyelle, juste la consonne.
Si on met deux ` dessus alif (ا) ça se prononce "ann" (le signe s'appelle fatḥatan).
Le u se prononce ou.
Le son du 3 inversé (ع) est un peu chaud, un peu entre ain (15%), an(10%), ha et a... et la prononciation change selon avec quoi il est combiné.
Alif est entre èèè et aaa.
Il existe aussi لا qui n'est pas représenté dans la charte ci-dessus car mélange de ل et ا.
Exprime la négation.
Peut s'écrire comme un petit noeud type sidaction vers le bas sinon avec un angle de 90° droit et la diagonale qui part du milieu de l'angle.
Je mélange peut être les différents arabes :(
أَنا (ana') : je
أنتي ('anti, pas sûr) : tu (pour une femme, ressemble à mélange "empty"/"aunty" :) )
أنتا (anta) : tu (pour un homme)
عِنْد (ahend) : avoir, posséder (attention c'est pas un verbe, c'est na notiuon d'avoir, posséder).
عَفْواً (aafouan') : de rien
حظاَ جيداَ (hza jyda) : bonne chance ("avengé yidann").
عَفْواً (tamaman') : absolument
أَهْلاً ('ahlaan) : Bonjour/Bienvenue
شُكْراً (shukraan) : Merci. شُكْراً يا مَها. (shukraan ya maha) = Merci Maha.
بَيْت (bayt') : maison
كَراج (karaaj) : garage
مِن (min') : de (d'un endroit, أَنا مِن لُبنان je suis du Liban, ana' min' lubnann' / تامِر مِن فَرَنْسا Tamir est de France).
أَيْن (aynn') : où
فَرَنْسا (faransya) : France
عُمان (auman') : Sultanat d'Oman.
ليبيا (libya) : La Lybie.
لا(la) : non.
سَمَك(samak) : poisson (ça fait penser à "sakana" un peu)
سيد(syid) : monsieur (sayid, le fameux "saïd")
تَعْرِف(taerif, pas sûr) : connaitre/savoir (avec le i presque e et f qui ressemble à un v, "taarifinn" vis à vis d'une femme).
جَديد(jadid) : nouveau
زَوج(zauj) : mari
كَريم(karim) : généreux
باب(baab) : une porte
عادي(3aedi) : ordinaire
مُمتاز(mumtèz) : extraordinaire, excellent
بارِد(bèèrèd) : froid
إِبْتِسَام(ibtisaam) : sourire
كَبير(kabir) : large, grand
ya : petite particule pour insister.
1. Docker
- Généralités
- Image Linux sur Windows
- Lancer un conteneur
- Faire sa propre image
- Interagir avec un docker
- Docker Networks
- Docker compose
2. Migration Gitlab vers Github
3. Notation Big O
4. LLM
5. Go
6. Python
7. Education
8. Ergonomie
9. Conduite de projet
10. Scrum
11. UML
- Diagramme de classe
- Diagramme de cas d'utilisation
- Diagramme de séquence
- Diagramme d'activité
- Diagramme de composants
- Diagramme de déploiement
- Diagramme de package
- Diagramme d'état
- Diagramme de communication
- Diagramme de temps
- Diagramme d'objets
- Diagramme global d'interaction
- Diagramme de profils
- Diagramme de structures composites
- BOUML
- PlantUML
12. Tests
- Les tests pendant le cycle de vie logiciel
- Android
13. Git
- Guide rapide pour débuter
- Organisation des branches
- Divers
- Tags
- Sauvegarde du Token Git sous Windows
- Head
- Cherry Pick
14. Subversion avec Netbeans
15. Symfony
16. Php
17. CSS
18. Modélisation mathématique des langues naturelles
19. Chatterbot apprenant
20. Lojban
21. Français
- Vocabulaire
22. Anglais
23. Arabe
- لا
- Vocabulaire
Pages des trucs qui n'ont pas assez de matière pour avoir leur propre page.
Docker
Généralités
Un outil open source qui fonctionne avec des conteneurs. Un conteneur est une sorte d'espace indépendant du système d'exploitation où on peut faire des actions qui ne vont pas affecter l'OS. On a l'impression que le conteneur est son propre petit OS indépendant mais c'est juste une illusion offerte par Docker.
Imaginons qu'on écrive une appli avec ses libs, sa base de données, sa version de Java/Python, ses fichers externes... on pourrait l'avoir dans cet espace puis distribuer l'intégralité de cet espace à d'autres personnes, et on serait sûr que tout marcherait directement.
Un conteneur se créé à partir d'une image. On peut faire ses images soi même ou bien récupèrer une image sur un annuaire docker (l'officiel -appelé "docker hub"- ou celui de votre entreprise si elle en a un) en utilisant la commande
docker pull maBelleImage.Pour voir les images téléchargées sur notre poste :
docker imagesOn peut les utiliser en faisant
docker run maBelleImage (si l'image n'existe pas en local elle sera téléchargée avec un pull automatique), cela va créer et lancer un container à partir de l'image. Pour voir les containers faire docker ps -a, vous noterez qu'il y a des noms aléatoire (on peut utiliser un argument --name pour leur forcer un nom lors du run).Certaines images peuvent être vraiment des OS mais ne pas croire qu'un conteneur est OBLIGATOIREMENT un OS virtualisé.
Image Linux sur Windows
Attention une image pour linux ne marchera pas sous Windows.
docker run --platform windows -dp 80:80 docker/getting-started
C:\outils\docker\27.0.3>docker run --platform windows -dp 80:80 docker/getting-started
Unable to find image 'docker/getting-started:latest' locally
latest: Pulling from docker/getting-started
docker: image operating system "linux" cannot be used on this platform: operating system is not supported.
See 'docker run --help'
Pour contourner ça on peut utiliser Windows Subsystem for Linux (wsl --install dans un powershell) qui va mettre un petit Linux dans notre Windows. Encore plus simple, mais un peu envahissant : utiliser docker desktop et lui demander de se mettre en mode linux (derrière il va juste... installer WSL également).
Lancer un conteneur
Attention à ne pas confondre RUN et START. Run va faire un éventuel pull+créer un nouveau container+start. Start va juste lancer un conteneur existant.
Pour lancer un conteneur existant faire donc
docker start leNomDeMonConteneur. Ajoutez derrière l'option -a si vous voulez voir les messages en sortie de console de ce conteneur.Un bon exemple est l'image "hello-world". Faites un
docker run hello-world (ce qui va la télécharer, créer le conteneur, le lancer en afficher la sortie), puis un docker ps -a. Vous pourrez voir que le conteneur est arrêté, ceci car son processus principal (la commande hello) s'est arrêté. sudo docker inspect hello-world pour plus d'infos.Une autre image intéressante est l'image du tutorial :
docker run -p 8910:80 docker/getting-started ("p" dit qu'on va brancher le port 8910 de notre pc au port 80 du conteneur). Le conteneur va lancer un serveur web et on pourra y accéder sur http://localhost:8910Vous pouvez voir l'association des ports entre le conteneur et notre PC en faisant
sudo docker port idDuDocker ou juste docker ps.Pour arrêter :
docker stop monConteneur, pour supprimer docker rm monConteneur pour faire les 2 à la fois docker rm -f monConteneurFaire sa propre image
Pour faire ses images soi même, il faut créer un fichier Dockerfile avec une syntaxe particulière :
# syntax=docker/dockerfile:1
FROM scratch
ADD coucouExec /
CMD ["/coucouExec"]
Ci-dessus on demande de créer une image à partir de rien (scratch) -on pourrait créer à partir d'un image existante genre Ubuntu par exemple-, on lui demande d'ajouter le fichier coucouProg puis de lancer coucouProg.
CoucouProg pourrait être un simple fichier c compilé avec
gcc -static -o coucouExec coucouProg.c :
#include <stdio.h>
int main() {
printf("coucou\n");
return 0;
}
Pour se servir de ce fichier faire
docker build --tag coucou .. Puis vous pouvez lancer l'image avec docker run hello.Et voilà le travail :
aka@LAPTOP-AU6T2CVI:~$ sudo docker build --tag coucou .
DEPRECATED: The legacy builder is deprecated and will be removed in a future release.
Install the buildx component to build images with BuildKit:
https://docs.docker.com/go/buildx/
Sending build context to Docker daemon 921.6kB
Step 1/3 : FROM scratch
--->
Step 2/3 : ADD coucouExec /
---> 7e207d3da8ee
Step 3/3 : CMD ["/coucouExec"]
---> Running in c4c6a208e6f9
Removing intermediate container c4c6a208e6f9
---> 9f23689ab629
Successfully built 9f23689ab629
Successfully tagged coucou:latest
aka@LAPTOP-AU6T2CVI:~$ sudo docker run coucou
coucou
Interagir avec un docker
On peut avoir un serveur qui se lance automatiquement au démarrage du conteneur, par exemple
docker run -p 8910:80 docker/getting-started et donc interagir sur le port 8910 via le navigateur, ou bien y connecter un GUI pour une BDD.Mais sur certaines images on peut carrément invoker la ligne de commande, par exemple en lançant un conteneur ubuntu :
docker run -d ubuntu (ou sudo docker run -ti ubuntu, sans -ti le conteneur va s'arrêter immédiatement), puis trouver son id/nom avec docker ps et enfin executer (exec) en mode interactif (-i) avec un terminal (-t) le programme bash dans le dossier bin de ce conteneur : docker exec -it f20cde27620a bin/bash. Plus simple, on peut juste executer "ls" : sudo docker exec f20cde27620a lsConnecter des "volumes" au conteneur
Volumes nommés
Si vous faites des modifications dans un conteneur, par exemple créer des fichiers dans le conteneur Ubuntu puis que vous le supprimez, vous perdrez ces fichiers. Il est possible de ne pas écrire dans le conteneur directement mais à côté, dans un "volume", une sorte de disque externe, ce qui permet de supprimer le conteneur mais garder les données.
docker volume create monBeauVolume pour en créer un.Puis en utilisant "run"
sudo docker run -ti -v monBeauVolume:/home/ubuntu ubuntu vous pouvez y créer un fichier (touch MonBeauFichie) dans /home/ubuntu, supprimer le conteneur (rm ou prune) puis refaire la commande de run+montée de volume. Le fichier devrait revenir.
moi@LAPTOP-12345:~$ sudo docker run -ti -v VolumeUbuntu:/home/ubuntu ubuntu
root@a99b2ebb615c:~# cd /home/ubuntu/
root@a99b2ebb615c:/home/ubuntu# ls
root@a99b2ebb615c:/home/ubuntu# touch MonBeauFichier
moi@LAPTOP-12345:~/tutoapp/app$ sudo docker container prune
WARNING! This will remove all stopped containers.
Are you sure you want to continue? [y/N] y
Deleted Containers:
a99b2ebb615c85773bab0be1030b9c868475e89fdf56babb610f1de47a34e236
Total reclaimed space: 61B
moi@LAPTOP-12345:~/tutoapp/app$ docker ps -a
permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/containers/json?all=1": dial unix /var/run/docker.sock: connect: permission denied
moi@LAPTOP-12345:~/tutoapp/app$ sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2b8a406b840b docker/getting-started "/docker-entrypoint.…" 37 minutes ago Up 37 minutes 0.0.0.0:8910->80/tcp, :::8910->80/tcp upbeat_wescoff
moi@LAPTOP-12345:~/tutoapp/app$ sudo docker run -ti -v VolumeUbuntu:/home/ubuntu ubuntu
root@ca387503d085:/# ls /home/ubuntu/
MonBeauFichier
root@ca387503d085:/#
Faites
docker volume --help pour avoir les infos pour supprimer/voir les infos/lister un volume.Volumes bindés
On peut "lier" un répertoire de notre OS à un repertoire du conteur. Toutes les modifs qu'on fera depuis notre OS ou depuis l'intérieur du conteneur seront synchronisées.
Ici je demande un lien entre ~/ubuntuHome sur mon "vrai" OS et /home/ubuntu dans le conteneur Ubuntu.
sudo docker run -it -v ~/ubuntuHome:/home/ubuntu ubuntuDocker Networks
Pour faire communiquer des conteneurs entre eux, on peut créer un réseau. Ou pourrait exposer les ports des conteneurs avec "-p" mais si on a notre app dans un conteneur connectée à un autre conteneur qui faire tourner un serveur mysql, c'est plus sur de ne pas exposer les ports du serveur à l'exterieur.
Pour créer un réseau :
docker network create MonBeauNetWork.Ensuite lors du run d'un conteneur on va lui dire qu'il est sur tel réseau avec tel nom :
docker run -d --network MonBeauNetWork --network-alias LeNonReseauDeCeConteneurSurMonBeauNetWork MaBelleImagePour qu4ún autre contenur puisse lui parler, il faut le runner sur le meme --network et lui demander datteindre LeNonReseauDeCeConteneurSurMonBeauNetWork.
Docker compose
Plutôt que de créer conteneurs avec docker files on peut tout mettre dans un seul fichier et utiliser docker compose.
Docker compose est un plugin, j'ai réussi à l'installer en faisant :
DOCKER_CONFIG=${DOCKER_CONFIG:-/usr/local/lib/docker}
sudo mkdir /usr/local/lib/docker/cli-plugins -p
sudo curl -SL https://github.com/docker/compose/releases/download/v2.28.1/docker-compose-linux-x86_64 -o /usr/local/lib/docker/cli-plugins/docker-compose
Exemple de fichier dockercompose.yml :
services:
app:
image: node:18-alpine
command: sh -c "yarn install && yarn run dev"
ports:
- 3000:3000
working_dir: /app
volumes:
- ./:/app
environment:
MYSQL_HOST: mysql
MYSQL_USER: root
MYSQL_PASSWORD: secret
MYSQL_DB: todos
mysql:
image: mysql:8.0
volumes:
- todo-mysql-data:/var/lib/mysql
environment:
MYSQL_ROOT_PASSWORD: secret
MYSQL_DATABASE: todos
volumes:
todo-mysql-data:
Puis faire
docker compose up -d.
moi@LAPTOP-12345:~/tutoapp/app$ sudo docker compose up -d
[+] Running 4/4
✔ Network app_default Created 0.2s
✔ Volume "app_todo-mysql-data" Created 0.0s
✔ Container app-app-1 Started 0.5s
✔ Container app-mysql-1 Started 0.5s
aka@LAPTOP-AU6T2CVI:~/tutoapp/app$
Migration Gitlab vers Github
Ca m'a toujours semblé évident d'utiliser Gitlab étant donné qu'il est open source et qu'on peut donc héberger sa propre instance. Mais GitHub a 2 avantages : une communauté plus importante (ce qui facilite les coopérations et la promotion) et un système de plugins.
Pour migrer les repos :
-créer un nouveau repository dans GitHub (sur sur votre profilm repositories, new). J'ai utilisé les mêmes noms que sur GitLab.
-ce nouveau repository va donner une URL pour le clonage. Copiez là.
-dans GitLab, ouvrir votre repository, puis settings, mirroring, coller l'url pour faire le clonage https (https://user:pass@github.com/marl1/yourProjectName)
-Renseigner votre nom d' utilisateur. Attention, le mot de passe est un token.
-dans GitHub, créer un token sur votre profil, settings, developper settings, tokens (https://github.com/settings/tokens). GitLab a un token pour chaque projet, GitHub a un token commun à tous les projets. Sauvez le token.
-copiez/collez le token.
-validez le formulaire.
-cliquez sur les 2 flèches circulaires "update now".
Pour GitLab Pages vers GitHub Pages :
-il y a 3 types de GitHub pages : celles du developpeur, celles de l'organization et celles des projets. C'est cette dernière qui correspond aux GitLab pages, allez dans les settings du projet, "pages".
-Il y a 2 façon de déployer une pages de projet :
1) "deploy from a branch", c'est à dire un copier/coller automatique des fichiers du repos sur le serveur (parfait pour les sites statiques), choisissez juste la branche et tous les foichiers du repo seront mis sur le serveur puis ils vous donneront l'url (https://marl1.github.io/cyoajsengine/www/games/a_sample_game/index.htm).
2) utiliser un pipeline, indispensable si on veut lancer des tests avant le déploiement ou transpiler du code TS en JS par exemple.
Erreur : "Waiting for a runner to pick up this job... " L'image que vous demandez n'est peut etre pas disponible.
Utiliser le plugin github actions si vous avez VsCode, il signalera les erreurs de syntaxe.
Notation Big O
Dans le monde de la programmation, c'est une façon concise de décrire le temps d'execution d'une fonction par rapport à son entrée.
Par exemple dans
maFonction(monTableau) { console.log("bonjour");} on s'en fiche de l'entrée, le tableau est ignoré. Ça s'écrit O(1). La durée d'execution sera la même peu importe l'entrée.Par contre
maFonction(monChiffre) { for (let i = 0; i < monTableau.length; i++) { console.log("bonjour");}}, là la durée dépend très clairement de la taille du chiffre en entrée, ça s'écrit O(N).Autre exemple, pour calculer la somme de tous les chiffres d'un nombre, par ex 5 en entrée, on peut faire une boucle 1+2+3+4+5=15 (solution O(n)) ou bien juste une petite astuce mathématique "5*(5+1)/2=15", solution O(1).
Cette fonction de complexitée O(n) prend 14 millisecondes pour 1000 en entrée :
console.log("-------------");
timestampDebut=new Date().getTime();
function maFonction(monChiffre) { for (let i = 0; i < monChiffre; i++) { console.log("bonjour");}}
maFonction(1000);
console.log("temps d'execution="+(new Date().getTime()-timestampDebut));
Elle met 140ms pour 10000, 1400ms pour 100 000....
Il existe également O(n²), lorsque la vitesse dépend de l'entrée mutipliée par elle-même, typiquement quand on parcourt un même tableau 2 fois :
console.log("-------------");
timestampDebut=new Date().getTime();
function maFonction(monChiffre) {
for (let i = 0; i < monChiffre; i++) {
console.log("ibonjour" + i);
for (let j = 0; j < monChiffre; j++) {
console.log("jbonjour" + j);
}
}
}
maFonction(100);
console.log("temps d'execution="+(new Date().getTime()-timestampDebut));
Elle met 140ms pour 100 et 14000ms (QUATORZE SECONDES) pour 1000. Je ne veux même pas tester pour 10000.
La différence est vraiment flagrante avec O(N) donc elle a droit a sa notation spéciale.
D'autres notations existent, on voit bien les différence lorsque les fonctions sont exprimées graphiquement :
Par exemple O(log n) :
console.log("-------------");
timestampDebut=new Date().getTime();
function maFonction(monChiffre) {
for (let i = 0; i < monChiffre; i++) {
console.log("bonjour" + i);
i=i*2;
monChiffre=monChiffre/2;
}
}
maFonction(10);
console.log("temps d'execution="+(new Date().getTime()-timestampDebut));
Elle met plus de temps a s’exécuter pour 1000 en entrée que 1 donc elle n'est pas O(1) MAIS même en mettant 1 000 00 00 00 00 00 00 00 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 000 en entrée on reste dans les 2 ou 3ms donc très largement plus rapide que O(N).
Autre notation à connaitre : O(2ⁿ), par exemple si on veut toutes les combinaisons possibles des éléments d'un tableau.
Choses à retenir pour estimer la complexité d'un programme :
1) On simplifie. Si ça affiche 3 bonjours peu importe l'entrée on ne note pas O(3) mais O(1). On s'en fiche également si ça itère 2 fois ou 15 fois (à la suite, sans imbrication) sur le tableau, c'est O(n), pas O(n+n). Par contre si ça itère de façon imbriquée, on si l'entrée se démultiplie, la diff est tellement grosse qu'on aura des notations comme O(N²).
2) Si le programme mélange plusieurs (par il fait une opération sur l'entrée puis n opérations dessus) , on choisit la PIRE. Avec Big O, on veut exprimer le PIRE temps possible. Par exemple si on veut écrire une fonction de tri, on imagine que le tableau en entrée est dans le PIRE désordre possible.
O(1) n'est pas non plus le saint graal. Il vaut peut être mieux une fonction qui mettent 4ms mutiplié par le nombre en entrée qu'une fonction qui met 3h à s'exécuter peu importe l'entrée.
Néanmoins en géneral on considère que O(1) c'est très bien, O(log n) bien, O(n) moyen et les autres à éviter absolument.
Il y a la même notion pour "l'espace", la mémoire consommée. Si on a un tableau qui grossit autant que l'entrée, on sera sur du O(n). Si la mémoire du programme reste la même quelque soit l'entrée, on est sur du O(1)...
LLM
Large language Model, désigne un générateur de texte, fonctionnant avec un réseau de neurone, entrainé sur une très grosse quantité de texte. Il peut compléter du texte, c'est à dire qu'on lui donne un "prompt" (du texte, par exemple : "ce matin, nous irons") et il va compléter (par exemple avec "au bois") selon des probabilités calculés d'après un corpus de texte.
Il est possible de le rendre plus créatif en modifiant la temperature (plus elle est haute, plus il aura de chances de choisir des mots aux probabilités moins élevées).
Néanmoins il semble pouvoir faire des calculs sur des chiffres jamais vus (alors qu'il n'est pas prévu pour), des déductions sur le temps (si je pars à xh et que j'ai xh de trajet...).
Tests intéressants
Connaissances générales :
-What's the biggest bookstore in XXX ?
-Who was the first king of France ?
Représentations du monde :
-I take a blue cube from the top of a yellow cube and put the blue cube on a red cube. There's also a black cube in the room. What's under the blue cube? (2023: GPT4 échoue, supercot-ggml-model-q4_0 autrement dit llama 30B réussi parfois).
GPT4 réussi plus souvent avec ce prompt : I take a blue cube from the top of a yellow cube and put the blue cube on a red cube. There's also a black cube in the room. What's under the blue cube? Please write a paragraph explaining your process of deduction and thoughts before giving an answer.
-A man has 5 red balls and 7 blue balls. He wants to arrange them in a row such that no two red balls are adjacent to each other. Show me some ways to arrange them. (2023: chatGPT échoue, il met trop de balles).
Théorie de l'esprit :
-Anna takes a ball and puts it in a red box, then leaves the room. Bob takes the ball out of the red box and puts it into the yellow box, then leaves the room. Anna returns to the room. Where will she look for the ball?
Calculs :
-I have one hour and 12 minutes of commute. I leave home at 7:14. However, there is 10m minutes roadblock today. What time will I arrive today?
Art :
-Write a 4 lines poem about cheese, it must rhymes and have 8 syllables per lines.
Détection du n'importe quoi :
-What is a pokhfino?
Go
Pour lancer un programme :
go run monprogramme.goPour compiler un exe :
go build execute pairouimpair.goLa fonction main est le point d'entrée.
Dans les classes, les méthodes/attributs qui commencent par une lettre majuscule sont publiques, sinon privées.
Pour déclarer les variables, := est utilisé à la première initialisation :
name := "John" Ce qui revient au même que :
var name string
name = "John"
Il n'y a pas d'héritage mais on peut créer des types personnalisés :
type MonNouveauType string
func (s MonNouveauType) Display() {
fmt.Print("blah")
}
func main() {
var maVariable MonNouveauType
maVariable.Display()
}
On peut découper une chaine comme ça :
message := "azerty"
message = message[0:5] //on peut découper une chaine comme ça
Vérifier si un nombre est pair ou impair :
package main
import "fmt" //pour formater des chaines de caractères ou des choses à l'écran
func main() {
var n int //on déclare une variable n comme entier. Sa valeur par défaut sera 0.
fmt.Printf("Entrez un nombre pour tester s'il est pair ou impair :")
fmt.Scanf("%d", &n) //on veut un nombre (digit) qu'on va mettre dans la variable n (%n), si on donnait n sans &, on lui donnerait une copie de n et c'est elle qui serait modifiée
//on aurait pu lui donner l'adresse mémoire 842350559480 pour modifier n
fmt.Printf("Le nombre %d est ", n)
if n%2 == 0 { //si le reste de la division est 0
fmt.Printf(" pair")
} else {
fmt.Printf(" impair")
}
}
Trouver le plus grand nombre d'un tableau :
package main
func main() {
tab := []int{34, 45, 88, 21, 4}
var max int
for i := 0; i < len(tab); i++ {
if max < tab[i] {
max = tab[i]
}
}
print("Le plus grand est ", max, ".")
}
Saisie de nombres et addition à la fin :
func main() {
tabNombres := []float32{} //on pourrait faire tabNombres := make([]int, 0)
var somme float32
var saisieNombre float32
var saisieTexte string
for saisieTexte != "n" {
fmt.Printf("Entrez un nombre :")
fmt.Scanf("%f", &saisieNombre)
somme += saisieNombre
tabNombres = append(tabNombres, saisieNombre)
fmt.Printf("Voulez-vous continuer ? (o/n)")
fmt.Scanf("%s", &saisieTexte)
}
fmt.Print("La somme de ")
for i := 0; i < len(tabNombres)-1; i++ {
fmt.Print(tabNombres[i], "+")
}
fmt.Print(tabNombres[len(tabNombres)-1])
fmt.Print(" est ", somme)
}
Fonctions :
package main
import "fmt" //pour formater des chaines de caractères ou des choses à l'écran
//pour lancer : go run
func addition(a, b float32) float32 {
return a + b
}
//fonction de callback, c'est à dire qu'on donne à la fonction une autre fonction en argument
//utilisée lorsqu'un traitement est terminé
func Demarrer(course func(name string)) { //course est une variable de type fonction
fmt.Println("Positionnement des voitures")
fmt.Println("Mise à zéro du chrono")
fmt.Println("Demarrage de la course !")
course("24h du Mans")
}
func main() {
fmt.Println(addition(9, 9))
//une variable dans laquelle il y a une fonction
f := func() {
fmt.Println("Je suis une fonction dans une variable")
}
f() //qu'on appelle comme ça
//une fonction totalement anonyme
func() {
fmt.Println("Je suis une fonction anonyme qui doit être exécutée immédiatement")
}() //exécutée immédiatement
//une fonction totalement anonyme et asynchrone (ne bloque pas le thread principal)
go func() {
fmt.Println("Je suis une fonction anonyme et asynchrone mais on ne me verra pas car le thread principal va finir sans m'attendre : (")
}() //exécutée immédiatement
fmt.Println(addition(9, 9))
func() {
//on a accès aux variables de la fonction au dessus, par exemple la var f dans laquelle on a mis une fonction
f()
}()
Demarrer(func(nomCourse string) { print("Vroum vroum") })
//on peut aussi combiner les fonctions dans les variables
maBelleFonctionDeCourse := func(nomCourse string) { print("Vroum vroum") }
Demarrer(maBelleFonctionDeCourse)
}
Pas d'héritage en go mais on peut leur donner comportement qui vont les lier à une interface :
package main
import "fmt"
type Participant interface { //on définit le comportement commun des coureurs et des voitures, "participant" est abstrait
Participer() //ils participent tous les deux
}
type Coureur struct {
Name string
}
func (c Coureur) Participer() { //on dit que les coureurs peuvent participer, ce qui en fait d'office des "participants"
fmt.Println(c.Name, "court")
}
type Voiture struct {
Marque string
}
func (v Voiture) Participer() { //idem, ils deviennent des "participants"
fmt.Println(v.Marque, "roule")
}
func Demarrer(tabParticipants []Participant) { //il attend des objets qui ont un comportement de participants
for _, p := range tabParticipants {
p.Participer()
}
}
func main() {
tabParticipants := []Participant{
Coureur{Name: "Bob"},
Coureur{Name: "John"},
Voiture{Marque: "BMW"},
}
Demarrer(tabParticipants)
}
Python
#pair ou impair en python
print("Entrez un nombre : ")
n = input()
#sys.stdout.write pour éviter de sauter de ligne sinon ",end =""" à la fin
print('Le nombre {0} est '.format(n), end='') #une chaine de caractère ets considéré comme un objet en python donc il y a des méthodes qu'on peut appeler comme "format()" ici.
if int(n)%2 == 0: #on doit caster sinon on essaie de faire une division sur une chaine de caractère
print("pair.")
else:
print("impair.")
#-------------------------------------------------------------
#trouver le plus grand nombre d'un tableau en python
tableau=[683,21,34,543,23]
max=0
for i in range(0,len(tableau)):
if max<tableau[i]:
max=tableau[i]
print("Le plus grand nombre est "+str(max))
#-------------------------------------------------------------
#Calculer la somme des nombres entrés
tabNombres=[]
saisieTexte=""
saisieNombre=0
somme=0
while saisieTexte != "n":
print("Entrez un nombre : ")
saisieNombre=input()
tabNombres.append(saisieNombre)
print("Voulez-vous continuer ? (o/n) ")
saisieTexte = input()
print("Résultat de ", end='')
for i in range(0, len(tabNombres)-1):
print(tabNombres[i], end='')
print("+", end='')
somme=somme+int(tabNombres[i])
print(tabNombres[len(tabNombres)-1], end='')
somme=somme+int(tabNombres[len(tabNombres)-1])
print(" : "+str(somme))
Fonctions en python :
def additionner(a,b):
return a+b
print(additionner(30,20))
Education
Le modèle transmissif consiste à donner des informations à l'élève, comme s'il était un contenant à remplir. Ca fonctionne chez certains élèves, qui apprennent par coeur des faits et sont capables de les sortir par la suite, mais ce n'est pas très intéressant car l'élève se contente de répéter ce qu'il a appris. Il faut que la communication prof->élève soit parfaite, ce qui semble impossible car la langue est ambigüe. L'élève peut aussi déformer les informations reçues en fonction de ses conceptions préalables du sujet.
Le modèle constructiviste suppose que le savoir doit être reconstruit, reformulé par l'élève pour être assimilé. Popularisé par Jean Piaget qui parlait également de "schèmes" : une action (ou suite d'action) reproductible et combinable avec d'autres schèmes. Ils peuvent évoluer avec le temps. D'après ce que je comprends, ce sont des outils qu'on acquière et qu'on l'on va utiliser par la suite (il peut s'agir d'un réflexe face à une certaine situation, une manière de faire quelque chose...). Il faudra parfois aider les élèves à secouer d'anciens schèmes, c'est à dire, leur faire remettre en question les outils qu'ils utilisent si on les juge mauvais.
Le socioconstructivisme ajoute l'idée de l'importance de l'environnement social : on apprend mieux entouré d'élèves (entraide, émulation...).
L'étayage, c'est l'assistance du formateur permettant à la personne formée d'arriver seule à résoudre un problème qu'elle ne savait pas résoudre au départ. Autrement dit, aider pour que la personne devienne autonome.
Ergonomie
Aaptation d'un environnement de travail pour optimiser le confort, la sécurité et l'efficacité d'un système à ses utilisateurs.
Un site est ergonomique s'il peut répondre efficacement aux besoin de ses utilisateur en leur fournissant un confort de navigation. Peut être évalué avec le taux de rebond (un utilisateur entre sur le site et quitte immédiatement), ce qui signifie que le référencement, ou le contenu ou que l'ergonomie ne sont pas bons.
Prendre en compte : les attentes de l'utilisateur, ses habitudes, son âge, l'équipement avec lequel il visite le site, ses compétences informatiques.
Conseils pour un site ergonomique : sobriété (simplicité, le site doit être peu chargé), peu chargé (pas de gis animés dans tous les sens), lisibilité (clair et structuré, texte suffisamment aéré et structuré avec paragraphes et titres de différents niveaux), organisation générale du site (infos les plus demandées en haut de page), règle des 3 clics (toute information doit être trouvée en 3 clics), repérage (l'utilisateur doit se repérer sur le site, header consistant sur les pages, homogénéité éléments de navigation au même endroit sur les pages, charte graphique homogène -mais on peut changer des couleurs pour séparer les sections), liberté de navigation (retourner facilement à la page d'accueil), tangibilité de l'information (connaître la date du mise à jour et le nom de l'auteur), ne pas proposer des liens qui affichent des pages en travaux (cacher les liens vers ces pages), temps d'affichage doit être inférieur à 15s (images optimisées en taille, toujours affichées en taille réelle -pas de redimensionnement), facilitation des échanges avec le visiteur (recueil de leurs impressions), adaptabilité (laisser à l'utilisateur la possibilité de personnaliser le site en redimensionnant les polices par exemple, site responsive), adapté aux non et mal voyants (balises adaptées, légendes sur les images, contraste fort, couleurs adaptés aux daltoniens, information accessible sans feuille de style.
Interface : le point des échanges entre l'homme et la machine, on aura une partie matérielle (écran, clavier, souris...) et logicielle qui vient entre les concepts et l'utilisateur.
Il y a 4 étapes pour architecturer l'information qu'on va présenter au visiteur :
-L'organisation : énumérer (toutes les informations qui seront dans le site), catégoriser (on tri ces infos), structurer (classer par ordre d'importance et faire des dépendances entre les infos). Equilibre entre trop d'infos dans une seule catégorie et trop de catégories qui pourraient perdre l'utilisateur.
Par exemple, pour un site e-commerce on liste tout ce qu'on va vendre, puis on classe par catégorie puis on décide ce qui est mis en avant (le plus vendu, ou les promos, etc).
-Etiquetage (la manière dont les éléments sont nommés, par exemple le menu). Utiliser le texte au maximum.
-Le système de navigation (comment on va naviguer sur le site, outre le menu). L'utilisateur ne devrait pas avoir à cliquer sur le bouton précédent du navigateur. Eviter les menus déroulants car ils obligent l'utilisateur à mémoriser ce qui se trouve sous le menu et imposent un mouvement précis de souris.
-Système de recherche (moteur de recherche dans le site).
Important de fixer l'objectif du site web. Site vitrine, e-commerce, institutionnel, outils web, blogs, site personnel, communautaire, wiki...
Les outils métiers sont maintenant migrés vers le web ce qui offre plusieurs avantages : accès facilité, support des périphériques mobiles, standardisation des interfaces, des outils, mises à jour simplifiées.
Le retour sur investissement : dans une situation A que l'on peut mesurer avec indicateurs qualitatifs/quantitatifs -> on fait un investissement -> je suis alors dans la situation B que l'on mesure à nouveau avec les indicateurs de A -> on calcule la différence entre les indicateurs de A et B pour savoir si l'amélioration est positive.
Il est difficile de mesurer les différences en ergonomie par manque d'indicateurs et de mesures factuelles. Souvent des investissements ne sont pas faits car la situation n'est pas critique.
On peut arguer que la mise en place d'une meilleure ergonomie a fait gagner de l'argent grâce à la productivité (plus facile d'utiliser le site métier) ou la vitesse grâce à laquelle les clients achètent leur produit. Un autre indicateur est l'évaluation de la satisfaction client.
Point clef : l'indicateur de la situation de départ. Se baser sur lui et ne pas être uniquement réactif à ce qui se passe sur l'instant t.
Règles d'or en ergonomie :
On a tendance à se focaliser sur les couleurs, logos, éléments... Mais pour améliorer le taux de conversion (le pourcentage des utilisateurs qui font un achat sur le site).
1)Viser la simplicité : pas plus de 7 grand maximum. Police lisible, pas plus de 3 fonts différentes et pas plus de 3 tailles différentes.
2)Mise en place de hiérarchie visuelle : le regard du visiteur doit être capté par les éléments les plus importants, position, taille couleurs.
3)Système de navigation intuitif. Afficher un menu de navigation clair, menu de navigation dans le footer, fil d'ariane, moteur de recherche interne, pas trop d'options de navigation, arborescence à 3 menus maximum
6)Respecter les conventions/standards du web actuel (menu de navigation, logo -qui renvoie vers la page d'accueil- en haut de la page, apparence des liens survolés changent).
7)Le site doit donner confiance. En respectant les conventions vues plus haut, affichant les mentions légales, les prix.
8)Se mettre à la place de ses visiteurs. Tests utilisateurs à distance (Evalyzer), utiliser des outils d'analyse de comportement (crazy egg), demander des feedbacks aux visiteurs.
Listes de critères ergonomiques : Critères ergonomiques pour l'évaluation d'interfaces utilisateur (JM Bastien et D Scapin), S. Ravden et G. Johnson, J. Nielsen adapté au web par K.Instone.
Analyse de la demande : pilier de l'intervention ergonomique. Quels sont les besoins qui motivent cette demande ? Quels sont les objectifs de l'application ? A qui le site s'adresse-t-il ? S'il s'agit d'une refonte, a-t-on des retours des précédents utilisateurs ? A ce stade là, il ne faut surtout pas oublier les utilisateurs.
On fait va faire valider nos maquettes par le client puis travailler sur le projet. Le cahier de recette va répertorier les différents scénarios d'utilisation du site (par exemple un fichier excel où on renseigne les étapes que l'on veut tester par type d'utilisateur).
Puis plusieurs étapes pour les tests utilisateurs : identifier la cible utilisateur et ses caractéristiques, identifier les objectifs des utilisateurs, recruter et prendre rendez-vous avec les utilisateurs, préparer le plan de test en fonction des objectifs d'utilisabilité, préparer pré et post questionnaires, développer le matériel de test, pré-tester avec un ou deux utilisateurs, conduire les tests, analyser les résultats.
Personas : archétypes utilisateurs (par exemple mère de famille, homme d'affaire...). Aident la prise de décision.
Tri par carte : exercice pour catégoriser. On a donne à chacun des membres un paquet de cartes identique qu'ils doivent classer. Les cartes représentent les rubriques du site. Utile pour Voir que chacun a sa propre façon de classer.
Conduite de projet
PMI : Project Management Institute (certifiant les gestionnaires de projets -informatiques et autres).
Il faut se poser la question : pourquoi est-on en train de programmer ? Chaque développeur doit se la poser. Tout d'abord, il faut comprendre ce qu'on a à faire puis mettre en place la méthode (agile ou autre). Tout ce qu'on fait en informatique, c'est pour une raison. On peut conduire une voiture avec un passager qui donne les directions sans savoir où on va, mais on ne sera pas à l'aise. Il faut une vision globale (quelle est la destination...). En tant que développeur on doit faire appel à notre bon sens et se mettre à la place de l'utilisateur au delà du cahier des charges. Il donne la ligne directrice de ce qu'on doit faire. Ne pas oublier que les utilisateurs se considèrent comme des informaticiens et on tendance à empiéter sur notre domaine d'exercice alors qu'ils devraient se limiter à ce qu'ils souhaitent obtenir. Le programmeur doit comprendre l'entreprise avant de programmer.
Système d'information : l'ensemble des composants physiques ou logiques interconnectés afin de produire de l'information pour la prise de décisions. Ceux pour qui on travaille ne pense pas en terme d'affichage, de réseau, de processeur... Matériel+logiciel+données+procédures+acteurs.
Par exemple : le système financier d'une entreprise qui va constituer le compte de charge, de produits.
L'entreprise va ainsi voir si elle a atteint ses objectifs avec des éléments factuels, ce qui va lui permettre de prendre des décisions.
Pour le développeur, il faut être objectif : quels sont les tests unitaire, de non-regression, combien de temps ça a pris pour faire telle ou telle chose... On doit donner des chiffre, pouvoir faire un rapport synthétique.
CASSIOPEE : logiciel développé pour centraliser la gestion de la justice (synchroniser les juridictions), voir le rapport de l'assemblée nationale 3177. Les projets informatiques respectent rarement les délais et aboutissent rarement correctement.
Ce n'est pas un programmeur qui décide où placer les boutons de l'application, ça doit se faire avec l'utilisateur.
Pourquoi on le fait, à qui on s'adresse, quels sont les enjeux.
Pour Cassiopee ils ont utilisé une méthode de gestion de projet en V, sans écouter les clients pendant le développement du projet. La structure était pas suffisamment souple pour prendre en compte les constants changements legislatifs.
Les commerciaux vont travailler contre nous. Il faut mettre les commerciaux devant leurs responsabilités et prévenir quand ils ont vendu des choses impossibles.
Tierce maintenance applicative : des personnes vont maintenir le code.
L'utilisateur est incapable d'écrire un cahier des charges. En général il énonce ce qu'il veut et quelqu'un va rédiger le cahier des charges à sa place (il y a des entreprises spécialisés). Il faut se méfier du cahier des charges, prendre du recul, analyser les interactions possibles, voir au delà. Penser à la documentation et la formation utilisateur.
Voir aussi projet CHORUS (informatique financière). La France est un des rares pays à être géré comme une entreprise, on sait exactement ce qui entre et sort.
Un projet s'intègre dans la stratégie de l'entreprise pour lui permettre d'atteindre ses objectifs. Un projet est limité par rapport à un domaine spécifique qu'il convient d'identifier. Par exemple pour la gestion de la bibliothèque (la ville).
Conférence sympa sur kanban :
https://www.infoq.com/fr/presentations/inversion-controle
Burndown : un graphique avec une ligne indiquant combien d'heures il nous reste avant de finir. En pointillé est indiqué ce qui serait attendu.
On ne peut pas appliquer Agile si l'utilisateur ne peut pas se rendre disponible.
Scrum
Une méthodologie qui permet de mettre en place l'agile, voir scrumguide.org.
4 rôles chez ceux qui appliquent Scrum :
-Stakeholders, les gens qui ont un intérêt pour le résultat produit par l'équipe. Le client souvent, mais pas forcément -par exemple si c'est une startup qui commence et n'a pas encore de client. Ca peut être aussi des régulateurs qui cherchent à faire respecter un process qualité ou légal. Ca peut être la structure qui emploie l'équipe des devs (SSII par exemple). Ca peut être des experts que l'on va consulter. Ou de façon plus générale, "le métier".
-L'équipe qui produit les résultats attendus par les précédents (généralement les devs/testeurs).
-Product Owner (PO) qui fait la liaison entre les 2 précédents. Il peut être davantage côté client, davantage côté équipe prod, il peut y avoir aussi y avoir 2 PO. Comme c'est un travail conséquent, on peut aussi avoir une équipe PO qui réponde à un PO principal.
-Scrum Master qui est dédié au bon fonctionnement de l'équipe.
2 cadences :
-Daily meeting (="daily scrum") tous les jours, moins de 15 min (on a fait quoi hier, on va faire quoi jusqu'au prochain daily meeting, ça peut être aussi simple que "j'ai bien avancé sur les tickets et je continue demain"). Rassemble toutes les personnes qui interviennent sur les tickets depuis le démarrage de leur dev jusqu'à ce qu'ils soient terminés, donc souvent devs+testeurs.
-Sprint, de 1 à 4 semaines (avec une revue du sprint et de ce qui a été livré par les Stakeholders et le PO -max 4h, retrospective sur le fonctionnement de l'équipe pendant le Spring, planning pour préparation du prochain sprint -maximum 8h). Débute immédiatement après le précédent. Il peut être annulé.
3 artefacts :
-Le produit incrémenté (le résultat du travail de l'équipe).
-Le backlog du produit (liste des fonctionnalités -"ticket", "stories"- que les stakeholders veulent rajouter dans le produit).
-Le backlog du sprint (liste des fonctionnalités qu'on veut mettre en place dans ce sprint).
Le PO (et son équipe d'assitants PO) prioritise les tickets, modifie le backlog, explique les tickets et la backlog, valide les éléments réalisés.
L'équipe de dev/test pose des questions aux PO pour s'asusrer que les tickets soient clairs, ils font une estimation des tickets, s'engagent sur le développement à une certaine date, font le dev, pour que les tickets passent au statut réalisé et livrent le produit. La définition de ce statut "terminé" est variable : ça peut être juste le dev, ça peut comprendre jusqu'aux tests finaux, rédaction des docs, etc (on parle de Definition Of Done), et on ne réouvre jamais un ticket fermé ! L'équipe doit rester la même tout le sprint, ne pas dépasser 9 personnes. Elle doit s'organiser toute seule pour savoir qui développe quoi. Généralement elle développe des règles d'équipe pour résoudre les conflits.
Burndown chart : une courbe qui représente le travail restant dans le sprint. Suit la date à laquelle les tickets sont fermés. Par ex 1ère semaine il reste 12 tickets à faire, 2e semaine il devrait rester moins de tickets mettons 8 et 3e semaine 4, donc le graphique descend de 12 à 8 puis 4. C'est pour ça qu'il est très important de mettre à jour ses tickets et diviser ses travaux en petits tickets d'un ou deux jours. Généralement sur chaque ticket on met un point d'effort et on se base sur ces points d'effort.
Refinement/grooming : les questions réponses / analyses / cadrages pour passer les tickets à ready (juste avant le dev). Il doit être terminé avant le début du sprint. Quand on dev le sprint 4 (par ex), il faut que les tickets du sprint 5 soient déjà refinés.
UML
Langage de modélisation unifié, proposant de nombreux types de diagrammes couvrant différents aspects du développement logiciel. L'écriture de code n'est qu'une petite partie de la réalisation d'une application, il existe d'autres étapes comme : comprendre le besoin, définir l'architecture de l'application, tester, suivre les besoins, effectuer la maintenance, écrire la documentation d'installation/d'utilisation/pour les développeurs...
Modèle : représentation, à différents niveaux d'abstraction et selon plusieurs vues, de l'information nécessaire à la production et à l'évolution des applications.(UML 2 pour les développeurs) Plusieurs vues pour une même application (vue des utilisateurs, vue technique, vue des données par exemple). L'ensemble doit être cohérent.
Dans l'idéal, le modèle devrait permettre la génération de code, il devra donc être aussi détaillé que celui-ci. Mais il contient des informations qui vont au delà du code (cas d'utilisation, déploiment...) donc le modèle devra être davantage détaillé que le code.
Le langage évolue souvent, actuellement on est arrivé à 14 diagrammes, chacun étant une vue partielle du modèle à décrire.
Diagramme de classe
Modéliser la structure des différentes classes d'une application orienté objet ainsi que leurs relations.
Classe : définit la structure d'un objet et permet la construction d'instances. Se représente avec le nom de la classe dans un rectangle.
Les cardinalités sur les liens sont inversées par rapport à Merise, ci-dessous un joueur peut incarner 0 ou plusieurs personnage et un personnage ne peut être incarné que par un seul joueur:
Joueur-1----incarner----0,*-Personnage
Les classes abstraites sont notées en italiques.
Pour les attributs et les méthodes, la visibilité peut être indiquée :
+ Public
- Private
# Protected
~ Package
Souligné = statique, italique = abstraite, tout en majuscule=constante (ce sont des conventions UML 1.4, en UML 2.0 c'est laissé libre).
Propriété/attribut : se représente dans le rectangle, sous un trait qui sépare du nom de la classe, de la forme nomAttribut : typeAttribut. S'il s'agit d'un tableau, d'une liste, ou généralement d'un entre crochets à côté du type (certains le mettent à côté du nom de l'attribut), on peut indiquer le nombre maximal/minimal. Un $ précédent le nom indique qu'il s'agit d'une constante, un / indique une propriété dérivée d'autres attributs (par exemple l'attribut nomComplet sera dérivé du nom et du prénom).
Méthode : se représente dans le rectangle, sous un trait qui sépare des attributs. [visibilité] nomDeLaMethode(parametre) : typeRetourné. Les méthodes statiques sont notées nomDeLaMethode():nomDeLaClasse.
Interface : définit un contrat que doivent respecter les classes. Généralement représenté de la même façon qu'une classe mais avec <
Implémentation d'une interface : un trait pointillé entre la classe et l'interface avec une pointe de flèche blanche touchant l'interface.
Héritage : flèche à la tête blanche, au trait continu, entre la classe qui hérite et la classe mère. La tête de la flèche est collée à la classe mère.
Package : un rectangle avec un onglet en haut à gauche où est indiqué le nom du package.
Importation de package : une flèche en pointillée entre 2 packages, la tête de la flèche n'est pas pleine. La flèche pointe vers ce qui est importé. Si A import B : A -----> B
Note : un rectangle au coin droit corné attaché à un élément par une ligne pointillée, contenant un commentaire sous forme de texte. On peut écrire "<
Composition : un losange plein au début du lien vers la classe qui agrège, par exemple un losange noir du côté d'une classe "fenetre" jusqu'à une classe "bouton" : si on supprime la fenêtre le bouton joint va disparaître.
Agrégation : un losange vide au début du lien vers la classe qui compose, par exemple "page html" qui sera agrégé avec une image. La suppression de la page html n'implique pas la destruction de l'image.
Stéréotype : Entre 4 chevron <
Diagramme de cas d'utilisation
Permet de lister les fonctionnalités du système. On aura un ou plusieurs acteurs, représenté avec un bonhomme bâton avec le nom en dessous (par exemple l'utilisateur, l'administrateur, le gestionnaire...) qui est relié à une action (verbe dans une bulle) avec un trait (gérer les livres, gérer les utilisateurs etc). Les utilisateurs peuvent hériter les uns des autres avec un lien de l'enfant vers le parent terminé par un triangle blanc (comme pour le diagramme de classe). Les actions sont regroupées dans des boîtes avec le nom du système au dessus.
Si le cas d'utilisation nécessite un 2e acteur
Les utilisateurs peuvent aussi être représentés un peu comme des classes, on le fait souvent lorsqu'il s'agit d'utilisateurs non-humains. Exemple : commercial----acheter----système bancaire
Entre deux actions, on peut mettre une relation "include" (flèche pointillée du parent vers l'enfant), pour dire que l'une inclus l'autre : en gros on extrait une sous-action de l'action. On peut également mettre une relation "extend", si on veut lier une action à une autre en disant qu'elle peut être effectuée.
On peut détailler ces cas d'utilisations avec des sous-bulles, voir des sous-sous-bulles.
Diagramme de séquence
Dynamique, illustre le temps qui passe et les interactions entre les objets.
Typiquement, on a plusieurs "lignes de vie", en pratique des lignes verticales pointillés avec dans une boite au dessus le nom de l'instance. Sur ces pointillés on aura des rectangles indiquant le temps passé. Entre les lignes de vie on aura des flèches où seront notés les méthodes. On peut entourer de cadres indiquant des loops, des switchs...
Le diagramme de séquence peut être très simple, juste illustrer un enchaînement pour arriver jusqu'à une activité.
Par exemple, pour l'activité "suppression de compte" on part du moment où l'utilisateur touche le clavier jusqu'à l'action "suppression de compte". On pourra ainsi avoir envoie de "demande de connexion" renvoie de "page de login", puis "envoie infos de connexion", puis "envoi de la page d'accueil une fois connecté", puis "suppression du compte".
Il pourra aussi être très détaillé pour qu'on puisse s'en servir dans l'équipe, illustrant la création et la destruction d'instances.
Diagramme d'activité
Diagramme de comportement, dynamique. Ressemble aux algorithmes représentés en logigrammes. Un point noir au départ, des activités (texte dans des boites aux coins arrondis) chaînées avec des flèches, des losanges pour les prises de décision, des rectangles noirs pour des routes parcourues en même temps (threads différents finalement), un point noir au centre d'un rond noir à l'arrivée. On peut avoir un "sous diagramme", une boite contenant un diagramme d'activité, avec les entrées sur une étiquette à gauche et les sorties sur une étiquette à droite.
Un rond avec une croix indique la "fin locale de flux", càd terminer un thread.
Région interruptible : un carré en pointillé qui entoure tout un logigramme. Une étiquette indique une action qui peut interrompre tout le processus dans le pointillé, typiquement "annuler" (elle même sera le début d'un autre logigramme qui sortira du pointillé).
On peut mettre des carrés pour l'entrée de données, par exemple pour l'activité "vérifier infos", on pourra avoir deux boites "nom d'utilisateur", "mot de passe" en entrée.
On peut donner des régions (parfois appelées "couloirs") aux diagrammes, des boites avec un nom au sommet entourant les actions, pour indiquer que toutes ces actions concernent le client, toutes ces actions concernent le serveur, etc.
Au lieu de mettre les actions dans des boites aux coins carrés, on peut les mettre dans des boites avec un bord en forme de flèche
Diagramme de composants
Représentation des parties de l'application liées les unes autres autres, utilisé pour éviter de parler de classes ou package, utile pour le reverse engeneering. Quand on a perdu la doc du logiciel, on pourra utiliser ces diagrammes pour la reconstituer.
Un composant est une boîte avec son nom et un pictogramme à droite (3 rectangles évoquant une sorte de cahier). On peut avoir des composants dans des composants.
Un composant utilisera celui vers qui il pointe une flèche en pointillées (il y a parfois écrit "utilise" sur le lien).
On aura des interfaces, soit représentées avec un rond, soit une boite où sera noté "interface". Le client vers l'interface (celui qui aura besoin des services) y sera relié par une flèche en pointillée dont la flèche (pas pleine) sera du côté de l'interface.
Le service qui offre l'interface est connectée à elle avec une ligne en pointillée et un triangle plein vers l'interface (on peut aussi avoir un rond en guise d'interface et un demi cercle qui s'y connecte depuis le client).
Sur les composants on peut dessiner des petits carrés qui seront des ports, par exemple sur un composant on aura un petit carré "port web" qui sera connecté à une interface REST.
Diagramme de déploiement
Sert à décrire la structure physique sur laquelle sera déployée l'application. Par exemple un PC, un serveur, un routeur, etc.
On peut utiliser des boites 3D pour représenter les noeuds (machines etc) ou bien carrément des représentations graphiques de PC, serveurs, imprimantes... Les logiciels sont appelés des "artefacts", des carrés avec <
Diagramme de package
Autrefois c'était le diagramme de classe avec des icônes stéréotypées.
Regroupe n'importe quel type d'élément UML.
On va souvent y mettre des morceaux du diagramme de classe. Pour montrer qu'un package est à l'intérieur d'un autre, on les mettre directement dedans ou utiliser un lien avec un rond au bout. Ci-contre lang est dans le package java : lang-----ojava.
Une flèche en pointillée indique les dépendances : A<---import----B
Un trait plein indique une association entre deux classes dans les packages, mais on peut également avoir des notions d'héritage avec un lien et un triangle blanc ou bout, ou d'interface avec un lien pointillé et une flèche blanche également.
Diagramme d'état
Diagramme de comportement, dynamique, représentant le cycle de vie d'un objet. Un état représente un instant dans la vie de l'objet. Utilisé surtout pour les objets variant selon les stimulis extérieurs.
On aura les états de l'objet dans des boites arrondies avec un verbe à l'infinitif (créé, bloqué, renseigné...) et des liens entre les états sur lesquels seront écrits les évènements qui font passer d'un état à l'autre.
On peut donner aux états un traitement, une action qu'ils vont faire : sous le nom de l'état on trace une ligne et on va écrire "do/laMethode".
On peut regrouper plusieurs états dans une seule boite (on parle d'état composite), typiquement si dans 15 états on peut annuler, on ne va pas faire 15 liens vers annuler mais mettre tous les états dans une boite et c'est cette boite qui sera reliée à "annuler".
Historique : on peut également utiliser un H dans un rond pour indiquer que l'objet est historisé. Si on a plusieurs états regroupés dans une seule boite
Une transition interne (ou propre) / externe : par exemple, pour un objet panier, si on rajoute des objets et qu'on fait une action à chaque rajout, c'est une transition externe. Une transition interne est par exemple le calcul du prix total (???).
Diagramme de communication
Anciennement diagramme de collaboration. Dynamique, sert à montrer les interactions entre objets. Affiche un peu les mêmes infos que le diagramme de séquence sans la notion de temporalité par contre. On y retrouve plusieurs objets (rectangles aux coins arrondis où sont notés les noms des objets) liés entre eux par des liens surmontés de flèches pour indiquer le sens et de nom de méthodes pour passer de l'un à l'autre. Un n° devant chaque méthode indique l'ordre dans lequel les actions sont effectuées. Les itérations sont représentées avec des étoiles. On peut représenter les conditions avec des lettres (1A, 1B...).
Il y a un autre type de représentation utilisant des ronds soulignés pour les objets, des ronds avec un T tourné de 90° à gauche pour les vues, des ronds avec une flèche pour les contrôleurs (MVC).
Diagramme de temps
Dynamique, permet de représenter le temps de façon chiffrée. Ressemble à un chronogramme. Un cadre (rectangle entourant tout le diagramme) permet de définir la notion sur laquelle on va travailler, par exemple "accès utilisateur". Un texte placé à gauche indique l'objet pour lequel on va tracer la ligne de vie. Les états sont listés en une colonne à gauche devant le nom de l'objet. Sur une l'axe horizontal sera représentée l'échelle de temps. Une ligne évoquant un oscilloscope part de la gauche vers la droite, montant et descendant en fonction des états. Sur cette ligne, on peut indiquer les méthodes qui font passer d'un état à un autre.
On peut placer des contraintes de temps en notant entre accolades, au dessus de la ligne, des intervalles, par exemple |<---{5min}--->|. On peut mettre les contraintes un peu partout, par exemple {avant 18h30} pour parler d'un processus qui doit s'arrêter à une heure précise.
Il existe également une syntaxe alternative où les états sont mis en ligne en bas et répétés.
Diagramme d'objets
Une instanciation du diagramme de classe pour donner un exemple du programme à l'instant T. Ressemble donc beaucoup au diagramme de classe. On aura sur les carrés nomDeLaCasse:nomDeL'instance. Peu utilisé, va certainement disparaître.
Diagramme global d'interaction
Ou Diagramme vue globale d'interaction, rassemble plusieurs diagrammes d'activité. Peu utilisé également.
Diagramme de profils
Sert à la configuration du projet. Permet d'étendre les possibilités UML en créant ses propres stéréotypes.
https://www.visual-paradigm.com/guide/uml-unified-modeling-language/what-is-profile-diagram/
https://www.uml-diagrams.org/profile-diagrams.html
Diagramme de structures composites
Ressemble beaucoup aux diagrammes de classe/package mais on rentre dans le détail des attributs (avec quoi ils s'interfacent etc). On aura une boite pour la classe et des boites pour les attributs, chacun pouvant se connecter à d'autres.
https://www.visual-paradigm.com/support/documents/vpuserguide/94/2585/7193_drawingcompo.html
BOUML
Pour générer un diagramme de classe avec BOUML :
Nouveau projet, utiliser Java, créer package, créer un class view, class diagram, faire ses classes. Créer une deployement view. Double cliquer sur la class view et choisir le deployement view. Clic droit sur une classe, créer un source artefact. Clic droit sur projet, generation setting, onglet directory.
Choisir repertoire de génération. Clic droit sur le package, propriétés, onglet java, y mettre le répertoire de génération sélectionné et le nom du package. Puis tools, generate java.
PlantUML
Très bon outil, pour générer toutes sortes de diagrammes UML à partir de texte : http://plantuml.com
Exemples :
https://www.planttext.com/
Tests
http://www.vogella.com/tutorials/JUnit/article.html
-Test unitaire (ou test case) : un morceau de code servant à vérifier le bon fonctionnement d'une partie précise d'un programme et attendant un résultat précis. Exemple : un controleur doit appeler un service qui appelle un repository qui lit la BDD = on testera uniquement que le controleur appelle bien le service, mais c'est tout, le code du service ne sera même pas exécuté, on vérifie juste qu'il est appelé. Typiquement, un test unitaire teste une seule méthode : si cette méthode appelle d'autre méthodes ou objets, ces derniers seront simulés (on va les forcer à renvoyer telle donnée en sortie si telle donnée en entrée. Par exemple avec Mockito "Mockito.when(monObjet.getNom()).thenReturn("bob");" : on renverra "bob" quand "monObjet.getNom()" sera appelé. Une technique consiste à écrire le test unitaire avant d'écrire le code qui sera testé, c'est du Test Driven Development (ça manque un peu de souplesse je trouve car il faut imaginer ce qui sera codé -autant le coder, donc-, mais pour cadrer certaines règles métier ça peut être pratique). Ne pas confondre BDD et TDD : en BDD (behavior driven development) ce sont en général des non-informaticiens qui donne un comportement. Les TU ont l'avantage de ne pas nécessiter de lancer toute l'appli pour tester un petit bout.
-Test d'intégration / fonctionnel : vérifie le bon fonctionnement de plusieurs composants ensemble, par exemple une méthode qui appelle un objet qui a lui-même une méthode dont il a besoin. Par exemple un controleur doit appeler un service qui appelle un repository qui lit la BDD, le test d'intégration vérifiera les appels à plusieurs de ces éléments, parfois même jusqu'à la BDD en utilisant une BDD simulée. Ou encore, une personne a développée une interface pour insérer des données, un autre une interface pour consulter les données et on fait un test pour vérifier le fonctionnement du tout.
-Test suite : un regroupement de tests, par exemple "tous les tests concernant les factures". Typiquement ils sont lancés automatiquement à chaque build.
-Test fixture : morceau de code pour fixer les conditions initiales du test (variables pré-remplies par exemple).
-Test coverage : la quantité de lignes de code sur lesquels des tests ont été mis en place (attention parfois les tests survolent des lignes mais ne les testent pas, augmentant ainsi le test coverage artificiellement).
-Test de comportement : vérifie qu'une partie du code est appelé (on ne vérifie pas le résultat).
-Test d'état : on vérifie l'état (de la BDD par exemple) après un appel de fonction.
-Test système / de qualification : test avec les données réelles (préprod).
-Test d'acceptation/d'acceptance (si l'utilisateur/le recetteur est satisfait, s'il confirme que ce qui a été livré correspond aux attentes).
TestNG et surtout JUnit sont des frameworks de test java.
Les tests JUnit sont des classes à part, dans src/test/java, notés avec l'annotation @Test. On va utiliser une methode assert, par exemple
assertEquals(6, tester.multiply(2, 3), "2 fois 3 doivent faire 6");.Bouchon : données simulées pour qu'on puisse faire des tests (et du dev), par exemple avec un serveur json hébergé sur notre machine si on a pas encore accès à une API.
ISTQB (International Software Test Qualification Board) permet de devenir un testeur certifié. En france, on a le CFTL (Comité Français du Test Logiciel).
Le but des tests est de trouver des défauts, mettre en valeur des anomalies et assurer la qualité.
Erreur : produite par l'humain, elle peut engendrer une anomalie/un défaut dans le logiciel, ce qui va engendrer une panne.
Une anomalie a une sévérité (la dénomination peut varier : bloquante, grave, majeure, mineure, moyenne), une reproductibilité, un état (ouvert, en cours, corrigé, fermée, rejetée), criticité (par rapport au métier, c'est le client et pas le testeur qui la qualifie), urgence (niveau de priorité), un commentaire qui va expliquer le bug.
Il y a 7 principes à connaître pour les tests avant de se lancer dans le plan de test :
-les tests montrent la présence de défaut ;
-les tests exhaustifs sont impossibles (il faut prioriser selon un ordre définit par la gestion des risques) ;
-tester le plus tôt possible ;
-les défauts sont souvent regroupés dans une même partie du logiciel ;
-paradoxe du pesticide : on croit souvent avoir tout couvert alors que non. Les tests doivent être mis à jour/écris continuellement ;
-ils dépendent du contexte ;
-l'illusion de l'absence d'erreur : si on ne trouve pas d'erreur, c'est sans doute qu'on ne teste pas assez ;
Triangle de test :
-tout en bas, plus nombreux, les tests unitaires (qui testent une méthode précise) ;
-Au milieu, les tests d'intégration (comment fonctionnent les objets ensemble) ;
-Tout en haut de la pyramide, les moins nombreux, les tests manuels (on clique manuellement sur un bouton et on vérifie le résultat).
Processus de test
On commence par la préparation :
-Planification ;
-Conception des tests (rédigé par le "test manager", contenant le périmètre à tester, type de tests, environnement de test -bouchons, faux jeux de données etc., une analyse des risques);
-Détermination des critères d'acceptation (critères d'entrée : on va commencer à tester si l'environnement de test est prêt/si tout le développement a été fait, si l'appli a été déployée / critères de sortie : on va arrêter de tester s'il n'y a plus d'anomalie critique);
Puis l'exécution :
-Exécution des tests (on va faire campagne de test regroupés en lotissement, par exemple on teste tel ensemble de fonctionnalité, on aura un résultat effectif et un résultat attendu);
-Résolution des anomalies ;
-Clôture des tests ;
Le plan de test maître donne la stratégie de test globale sur le projet en se basant sur les spécifications détaillées du projet. Il permettra d'établir une matrice de couverture de test et des scénarios de test. Chaque scénario aura un "code scénario", un objectif (l'énoncé du test), un pré-requis (condition en amont dont on a besoin pour effectuer notre tests, des données par exemple), une action à faire de la part du testeur, un résultat attendu. Chaque scénario a plusieurs cas de tests.
Chaque cas d'utilisation donnera un ou plusieurs scénario, qui aura un ou plusieurs cas de tests.
Psychologie des tests :
-Il ne faut jamais reprocher au développeur un certain manque de compétence, il faut communiquer avec lui avec respect. On ne doit pas se servir des tests pour pointer du doigt le mauvais travail de quelqu'un.
Tests statiques : simplement en lisant le code, on n'exécute pas.
Une matrice des exigences permet au métier (aux utilisateurs) de voir que leurs cas d'utilisations sont couverts (4 cas d'utilisation en haut) et nous aide à mettre en place les tests :
Le cahier des charges fonctionnel va donner naissance à la matrice des exigences (aka matrice de couverture fonctionnelle) et il va également donner les spécifications fonctionnelles détaillées. Ces deux éléments vont donner le plan de test.
Les tests pendant le cycle de vie logiciel
Il faut distinguer les phases de test (aussi appelé "niveau de test") et les types de tests.
Phases de test
1) Tests unitaires (faits par les développeurs) ;
2) Tests d'intégration (faits par une équipe de testeurs, intégration applicative/inter-applicatives) ;
3) Tests système (ou "de qualification", "d'homologation", tests avec une volumétrie conséquente, par exemple une copie de la BDD de prod, souvent faits par une équipe de tests indépendante et impartiale) ;
4) Tests d'acceptation utilisateur (UAT, User Acceptance Test, c'est la "recette fonctionnelle" ou VABF : vérification d'aptitude au bon fonctionnement. Il y a aussi la VSR "Vérification du Service Régulier" où l'application est mise en production sur un site pilote pour être testé on parle aussi de validation d'exploitabilité-par exemple pour une application sur les imports on peut tester sur un seul département pilote).
Types de tests
-Test fonctionnel (Des fonctionnalités souvent métier. Par exemple dans le domaine de la banque, on va tester si on peut créer un contrat, créer un client... mais aussi l'authentification utilisateur par exemple).
-Test non-fonctionnel (Performances, tests de charge -si on a énormément de requêtes sur notre application, tests de portabilité -Linux/Windows, ergonomie...)
-Test structurel (ou "boîte blanche", l'inverse de la boîte noire, on regarde les bifurcations du code, les instructions, les décisions, les branches... Quand on fait du test unitaire, on est en "boite blanche").
-Test lié au changement (tests de confirmation -on vérifie que ce que dysfonctionnait précédemment fonctionne à présent, et de non-régression -on vérifie qu'il n'y a pas de bugs introduits avec notre nouveau code).
-Test de maintenance (migration de données, changement de plateforme, évolution de l'application, ou quand on a un bug remonté par un utilisateur après la MEP).
On parlera de decision (si quelque chose, alors...), branch (le déroulement après une décision) et statement (une instruction).
Conception des tests
Plusieurs façons de faire des tests.
En boite noire on aura les concepts de partitions (ou "classe") d'équivalence (par exemple on a un nombre qui doit être entre 5 et 8, on aura 3 classes d'équivalence : moins de 5, entre 5 et 8, au dessus de 8), valeurs limites (borne sup ou inférieure), états transition
, tables de décision (un tableau), cas d'utilisation.Android
http://www.vogella.com/tutorials/AndroidTesting/article.html#androidtesting
2 types de tests pour les applis Android : ceux qui nécessitent de faire appel à l'OS Android (dans app/src/test/java ) et ceux qui ont juste besoin de la JVM (beaucoup plus rapide, dans app/src/test/java).
Conseil 70% de tests unitaire, 20% fonctionnels et 10% cross fonctionnels (intégration avec d'autres apps).
Google fourni la librairie ATSL (Android Testing Support Library).
Git
Un repository contient en général les fichiers (texte, images, vidéos...) d'un seul projet, sans les fichiers compilés.
git help pour l'aide, git help branch pour avoir l'aide sur la commande branche.git config pour configurer git. Avec l'attribut --global, il va modifier le fichier ~/.gitconfig, mais on peut avoir un fichier gitconfig par dépôt. Exemple pour changer le nom d'utilisateur : git config --global user.name "[votre nom]", git config --global user.email "[votre mail]"Pour récupérer un projet sur son poste, il faut le "cloner", en récupérant l'url du projet fourni sur la page web de github/gitlab/etc. Puis
git clone [url du projet en ssh ou https].Quand on clone on créé un dépôt "local" sur son poste. Si on fait des modifs sur un fichier, il faudra faire un
git add [nom dufichier], puis un git commit -m "[le message qu'on veut]" (qui prendra en compte les fichiers qu'on a add). Attention, "git commit" sauvegarde en local ! Il faudra faire un "git push" pour pousser les données vers le serveur distant.On peut voir le "git commit" comme un snapshot, un instantané de nos fichiers.
Donc en cas d'incendie :
git add *, git commit, git push.git reset permet "d'annuler" un add (ce fichier ne sera pas pris en compte au prochain commit).git status pour savoir ce qu'on a modifié avant de commit. En vert, tous les fichiers qui seront embarqués pour le commit (donc ceux qu'on a "add"), en rouge ceux qui ne le seront pas.Il existe aussi
gitk pour voir en détail les fichiers modifiés, les branches etc.Lors d'un push, notre serveur va demander au serveur distant s'il accepte ou non notre modif.
Le ficier .gitignore permet d'ignorer des dossiers ou des fichiers :
/*.log pour ignorer les fichiers ".log", /**/bin pour ignorer les répertoires "bin" dans n'importe quel répertoire...On peut supprimer un fichier du système de version mais le garder localement avec :
git rm -r --cached chemin/vers/monfichiergit fetch ou git pull /git merge pour récupérer les fichiers distants sur le serveur. Il ne va pas écraser les fichiers de ntore dépot local, il affichera un message soit pour nous dire qu'un conflit a été géré automatiquement, soit pour nous demander de trancher par rapport à un conflit. On peut utiliser git mergetool pour résoudre les conflits.Branches
Il peut avoir plusieurs "versions" d'un projet qui existent en même temps : la branche master est la branche principale, il peut y avoir une branche pour la fonctionnalité X, une autre pour la fonctionnalité Y... Cela permet de faire des modifs sur le code sans affecter la branche master.
On peut créer une "branche" avec un "git branch mabellebranche" puis se positionner dessus avec
git checkout mabellebranche. Pour créer ET se positionner sur une branche : git checkout -b "ma-belle-branche". Les branches sont très légères, il ne faut pas hésiter à faire beaucoup de petites branches. Une branche contient les données du dernier commit et tout ce qui vient avant.La branche sera dans un premier temps "locale", visible uniquement sur notre poste. Il faudra la pousser à distance avec un
git push --set-upstream origin accountmodel, puis le collègue devra faire un git fetch pour la voir, et ensuite lui aussi un git checkout mabellebranche pour se positionner dessus.Commit
Une sauvegarde d'un changement dans le repository (par exemple un fichier texte modifié) s'appelle un "commit" (un "commit message" est un commentaire expliquant le commit). Chaque commit est identifié par un hashcode. Une branche est un pointeur vers un commit. On peut très bien avoir plusieurs branches qui pointent vers le même commit. La branche pointe par défaut là où on se trouve mais on peut très bien créer une branche sur un commit précis :
git branch -f maBelleBranche hashcodeDeCommit Si juste avant de commiter on se rend compte qu'on a travaillé sur master au lieu d'une nouvelle branche, ce n'est pas grave. On peut créer une branche avec
git branch maNouvelleBranche et commiter dessus.Généralement ça se passe comme ça : on créé sa branche, on travaille et commit plusieurs fois sur cette branche (par exemple à chaque fin de journée). A la fin de son travail, on merge avec la branche principale.
Lorsqu'on a fait un "commit" sur une branche, on peut demander un "pull request" sur la branche principale, c'est à dire qu'on propose (request) que la personne en charge de la branche principale récupère (pull) nos changements.
git branch pour lister les branches locales , git branch -a pour voir toutes les branches même les distantes. git branch -d ma_branche pour la supprimer (et -D pour forcer).Pour faire un "merge" de branche, on se met sur la branche où on veut merger, puis
git merge ma_branche, on peut spécifier un message avec "-m".Par exemple, si on veut merger master dans feature_nouveau_bouton, on se met sur feature_nouveau_bouton ("git checkout feature_nouveau_bouton") et on tape "git merge master". Celà modifiera les fichiers de la branche feature_nouveau_bouton en lui ajoutant les modifications de master.
En cas de conflit lors d'un git merge, le fichier en conflit sera modifié avec les sections en conflits indiquées avec des chevrons (>>>>>>). "git status" indiquera que vous êtes en train de merger. Modifier les fichiers pour ne garder que ce qui nous intéresse (soit manuellement avec un éditeur de texte, soit avec un outil comme Winmerge ou l'IDE). Une fois satisfait, ajoutez-les (git add mon_fichier) puis faites un commit.
"git merge --abort" permet d'arrêter un merge et de revenir à l'état initial (juste avant qu'on ait tapé "git merge").
git rebase : Utile dans le cas suivant :-une branche "nouvelle_fonctionnalité" a été tirée de "branche_principale" en 2019.
-des modifications ont été faites sur "nouvelle_fonctionnalité" en janvier et février 2020.
-des modifications ont ensuite été faites sur "branche_principale" en 2021.
-->Zut, "nouvelle_fonctionnalité" est maintenant en retard sur "branche_principale".
-"rebase" permet de faire comme si "nouvelle_fonctionnalité" venait d'être tirée de "branche_principale" en 2021. Il y a donc une sorte de réécriture de l'historique. En outre, les modifications de janvier et février seront regroupées dans un seul commit.
C'est quelque chose qu'il est déconseillé de faire si "nouvelle_fonctionnalité" a déjà été pushé ! Car la réécriture de l'histoire change les id des commits et ils peuvent être utilisés par un collègue/un outil. Donc à ne faire que si la branche feature est locale !
Notez que l'historique est en fait caché, on peut retrouver le commit original avec
git log --reflog ou git fsck --unreachable.git tag -a V1.0.0.0 -m "Mon beau tag", pour "marquer" des commit importants, par exemple un changement de version.Si on commit par erreur (par exemple, on commit sur master alors qu'on voulait commiter sur une autre branche) et qu'on a pas encore poussé, on peut utiliser la commande suivante pour revenir à l'état juste avant commit :
git reset --soft HEAD~1Si on push par erreur quelque chose, deux façons de faire :
-soit
git reset --hard master~2 pour revenir deux commits en arrière sur la branche master, mais attention car on perd COMPLETEMENT les commits, càd les fichiers sont effacés. Ca peut aussi poser problème si d'autres personnes ont fait un pull sur notre commit.-soit
git revert -n master~5 ..master~2 : Inverse les changements effectués depuis les 5 derniers commits jusqu'au 3e dernier commits (inclu). Git revert créé un commit où on annule les changements. Après ça, on peut le pousser.On peut aussi reset ou revert en visant un hash de commit.
Si on a ajouté juste un fichier par erreur, on peut faire:
git add fichier_ajouté_par_erreur
git commit --amend
git push -f origin master
Pour modifier le message de commit, à condition qu'on ait pas encore pushé, il suffit de faire en console :
git commit --amend, ce qui va ouvrir un éditeur de texte où on pourra écrire autre chose.On ne travaille pas généralement sur la branches master, on utilise d'autres branches qu'on appelle "release/", et sous ces releases, on va bosser sur des branches "features" (une pour chaque fonctionnalité). A la fin, on pourra ainsi embarquer certaines features dans la release et d'autres non. Pour chaque release on pourra aussi avoir une branche "hotfix".
Exercice pour les branches : https://learngitbranching.js.org/
Pour ignorer un fichier après qu'il ait été mis (par exemple on veut pousser une seule fois un fichier de conf avec des infos de login incorrectes, puis on modifie le password localement mais on veut garder le fichier de conf avec login incorrect sur le dépot) :
git update-index --skip-worktree dossierdufichier/monfichierdeconf.cfgGuide rapide pour débuter
Initialisation du dépot local
1)Créez un compte sur gitlab.
2)Créez un repository.
3)Configurer pseudo
git config --global user.name "[votre nom]" et mail git config --global user.email "[votre mail]" sur votre machine.4)Mettez vous dans le dossier dont vous souhaitez envoyer des éléments sur git et tapez
git init pour créer un dépôt local.5)
git add votredossier6)
git commit7)
git remote add origin https://github.com/VOTRE PSEUDO/NOMDUDEPOT.git8)
git push -u origin masterCréation d'une nouvelle branche pour travailler
Vous pouvez travailler directement sur master mais il est recommandé de créer une nouvelle branche.
1)Créez la branche (sur votre dépot local) :
git branch mabellebranche2)Positionnez-vous dessus :
git checkout mabellebranche3)Faites les modifs sur vos fichiers.
4)Ajoutez les modifs :
git add mesfichiersmodifies5)Commitez localement :
git commit6)Poussez vos modifs + la branche locale à distance :
git push --set-upstream origin mabellebrancheOrganisation des branches
Il y a plusieurs façons de travailler.
Dans tous les cas, on aura une branche master. Certains aiment y laisser la version en prod (mettons v1), d'autres trouvent ça un peu inutile et préfèrent mettre sur le master la version cours de dev (mettons v2).
Mettons qu'on ait la v2 sur le master.
On aura des branches v3 et v4 en cours de dev. Chaque dev pourra avoir sa petite branche, par exemple v3_nouvelle_fonctionnalite.
Il est conseillé d'avoir des branches integration et recette :
-A chaque push sur le master, on pourra avoir un outil comme Jenkins qui va tester, compiler, build, installer les binaires sur un environnement d'intégration et pourquoi pas lancer des tests automatiques d'interfaces avec selenium. Puis, il va commiter vers sa branche integration. Cette branche intégration sert donc à faire des tests automatiques, ce qui est rassurant pour les devs.
-Manuellement, on pourra lancer la livraison en recette pour que les testeurs puissent tester. La branche recette va pull de la branche integration (car les tests automatiques sont passés !) et compiler, installer en recette, et pusher sur une branche recette.
-Enfin, la livraison se fera à partir de la branche recette : on est sûr que tous les tests y sont passés.
Attention cette organisation peut se complexifier si on travaille sur des versions antérieures. Si on veut pousser une version antérieure sur la branche integration, ça peut bloquer car la branche integration est en avance. Pour resoudre ce problème, on peut avoir des branches speciales, par exemple integration_v1.1 / integration_v2 (et du coup recette_v1.1 / recette_v2), ou supprimer carrément la branche integration à chaque livraison...
Divers
Editer un message de commit
Voir https://docs.github.com/en/github/committing-changes-to-your-project/changing-a-commit-message.
Si ça n'a pas encore été poussé et qu'il s'agit du dernier :
git commit --amendRevenir en arrière
Si vous voulez annuler toutes vos modifs sur les fichiers et revenir au dernier état (attention, irréversible !) :
git reset --hardSi vous voulez revenir en arrière sur un commit pushé sur la branche distante (si aucun collègue n'a pullé le mauvais commit ça sera trabsparent pour eux) :
git reset --hard <revision_du_dernier_bon_committ>
git push --force
Voir le beau graph
git log --all --decorate --oneline --graphTags
Les tags permettent de mettre en valeur des points sur la branches particulièrement important, typiquement sur le commit qui sera livré au client. On est pas obligé d'utiliser des tags étant donné qu'on peut à tout moment revenir dans le passé sur n'importe quel commit. Néanmoins qu'il soit taggé permet de retrouver un commit plus facilement dans la liste.
2 types de tags "légers" ("git tag monBeauTag") et "annotés" ("git tag -a monBeauTagAnnote").
Un tag léger se pose sur un commit déjà existant.
Le tag annoté est un commit à part entière, avec son propre message de commit, son propre auteur etc.
Pour récupérer tous les tags :
git fetch --all --tagsSauvegarde du Token Git sous Windows
Il y a plusieurs façon de stocker le mot de passe/le token git. Dans un fichier (store)
git config credential.helper store, dans la config windows (wincred) git config --local credential.helper wincred...Attention le même mot de passe sera utilisé par tous les repos. En cas de multiple repos :
git config --global credential.https://github.com.useHttpPath truehttps://git-scm.com/docs/gitcredentials
Head
"Head" est similaire à une "tête de lecture", c'est un pointeur qui designe là où on se trouve actuellement (la branche, le commit, le tag...). On peut voir son contenu dans : .git/HEAD. "Detached head" signifie que ".git/HEAD" pointe vers un commit et pas une branche. On peut déplacer cette tête de lecture en lui donnant un hash, une branche, un tag mais aussi une commande comme
git checkout master^ pour revenir à l'avant dernier commit de master ou même git checkout HEAD^ pour revenir à l'avant dernier commit de là où pointe HEAD ou bien git checkout master~3 pour 3 commits avant master.Cherry Pick
Pour récupérer des commits précis.
git cherry-pick leCommitQueJeVeux unAutreCommitQueJeVeux fera une copie des commits leCommitQueJeVeux+unAutreCommitQueJeVeux et les mettra sur la branche en cours.Subversion avec Netbeans
Subversion ("SVN") est un gestionnaire de version pour des projets collaboratifs. Le site riouxsvn.com donne 50mo d'espace gratuit et 4 projets par utilisateurs. L'intégration de SVN est bien faite dans Netbeans.
Sur RiouxSVN, vous devrez créer un repository et récupérer son URL.
Pour mettre un projet sur riouxsvn, clic droit, "versioning", "import into subversion directory". Indiquez l'url et vos informations d'authentification.
Pour récupérer un projet de riouxSVN initialisé par quelqu'un d'autre, dans Netbeans Team->Subversion->Checkout.
Après avoir fait des modifs, clic droit "commit" pour envoyer les informations sur riouxsvb. Si un conflit est détecté, un message vous demandant d'updater s'affichera.
Clic droit sur le projet "update" va récupérer les fichiers de riouxsvn et les mettre dans votre projet. Mieux, si un fichier est modifié des 2 côtés, une fusion de fichiers sera effectuée. Si la fusion est impossible, cela sera indiqué dans le fichier :
<h:body>
<<<<<<< .mine
mamodif
=======
modifrecuperee
>>>>>>> .r5
<h:link outcome="welcomePrimefaces" value="Primefaces welcome page" />
Un clic droit "resolve conflit" permet de traiter les problèmes.
SVN est beaucoup plus simple à utiliser que GIT.
Symfony
Notes persos basées sur le cours https://openclassrooms.com/courses/developpez-votre-site-web-avec-le-framework-symfony
Installation
php -b dans une invite de commande doit indiquer la version de php.php peut décompresser des fichiers "phar" (équivalent des jar en java, des bibliothèques/liens vers les bibliothèques).
Pour installer symfony, on récupèrera donc le phar présent sur https://symfony.com/installer puis on le met dans "C:\xampp\htdocs" par exemple puis :
C:\xampp\htdocs>php symfony.phar new Symfony 3.3.2/app -> config de notre site web
/bin -> executables utilitaires (on peut manipuler depuis l'invite de commande pour effectuer diverses tâches comme génération de code, création d'utilisateurs, vider le cache -à faire avant de publier le site :
php bin/console cache:clear --env=prod, etc)/src -> code source de notre site
/tests -> tests unitaires etc
/var -> repertoire où symfony écrira des fichiers temporaires
/vendor -> bibliothèques externes
/web -> ce qui sera exposé au visiteur. Le controleur point d'entrée est "app.php", il y a également "app_dev.php" qui fait la même chose mais propose en plus des infos de débugs etc.
MVC : Modèle (en gros ce qui concerne la BDD), Vues (mise en forme -les pages html/css), Controleurs (analyse la requête et renvoie une réponse).
Bundle : une brique applicative. On peut imaginer un bundle "blog", "utilisateur", "boutique"... on peut les développer soi-même où en récupérer des déjà faits (http://knpbundles.com/). Les bundles doivent être renseignés dans app/AppKernel.php et le chemin d'accès dans app/config/routing.yml.
/Controller
/DependencyInjection -> informations sur la configuration des dépendances du bundle.
/Entity -> modèles
/Form ->formulaires Contient vos éventuels formulaires
/Resources
-- /config -> config du bundle (routes etc)
-- /public -> css, javascript, images...
-- /views -> vues, templates Twig
Chaque partie du site est un bundle,
php bin/console generate:bundle pour lancer l'utilitaire de création de bundle (création des repertoires, templates et ajout dans AppKernel et de la route dans routing.yml.Pour créer une page, il faut créer sa route. Le kernel envoie le chemin au "routeur" et celui-ci va vérifier si le chemin correspond à une route qu'il a en stock. Si oui, il renvoie des paramètres.
La route se déifnie dans le répertoire du bundle, dans "Resources\config\routing.yml". On aurait pu ajouter la route directement dans app/config/routing.yml mais mieux vaut la mettre dans le bundle, de plus il est déjà configuré pour analyser les routes de notre bundle comme vu plus haut. Par contre on peut ajouter
prefix: /chemin_que_je_veux_pour_mon_appli pour préfixer toutes les routes correspondant au bundle.Exemple de route (il pourrait s'agir d'un fichier routing.yml complet) :
nom_arbitraire_de_ma_route:
path: /chemin_dans_barre_d_adresse
defaults: { _controller: MonBeauBundle:MonControleur:methodeAExecuter}
Dans "path", on peut également indiquer une variable, exemple :
path: /consulterPost/{id}, la variable sera envoyée à la méthode "consulterPostAction". On peut séparer plusieurs variables avec des points ou de slashs (pour simuler des sous répertoires). On peut aussi forcer le format des variables avec le mot clef "requirements:". Il existe des variables systèmes (par exemple {_format} va changer le header renvoyé lors du rendu de la page pour y mettre le format spécifié).Autre exemple de route, ci dessous on attends un numéro (entre 1 et 4 chiffres comme indiqué par \d{1,4}) de page (monsite.com/3). Sans ce numéro la page par défaut sera la 1 :
nom_arbitraire_de_ma_route:
path: /{page}
defaults:
_controller: MonBeauBundle:MonControleur:methodeAExecuter
page: 1
requirements:
page: \d{1,4}
Ensuite, il faut créer le controleur dans le dossier "Controller", ici il devra s'appeler "MonControleurController" et contenir une méthode "methodeAExecuterAction". Voici ce que devrait maintenant afficher l'adresse
http://localhost/Symfony/web/app_dev.php/chemin_dans_barre_d_adresse (notez que la réponse est renvoyée brut, l'objet réponse permet de renvoyer une vraie réponse http, on pourrait aussi renvoyer une vrai réponse d'erreur 404 en faisant $response->setStatusCode(Response::HTTP_NOT_FOUND); si on voulait):
<?php
namespace Mon\BeauBundle\Controller;
use Symfony\Component\HttpFoundation\Response;
class MonControleurController
{
public function methodeAExecuterAction()
{
return new Response("Bleuh :-p");
}
}
On peut aussi renvoyer une page html. Symfony 2 et 3 utilisent le système de template Twig. Il faut tout d'abord écrire une page twig dans Resources/views/(adresse que l'on veut, MonControleur pour rester cohérent)/index.html.twig :
{# src/Mon\BeauBundle/Resources/views/MonControleur/index.html.twig #}
<!DOCTYPE html>
<html>
<head>
<title>Ma page twig</title>
</head>
<body>
<h1>Hello {{ nom }} !</h1>
<p>
<h1>BLEUH !</H1>
</p>
</body>
</html>
Ci-dessous, une page twig avec des arguments (ici, le nom) :
namespace Mon\BeauBundle\Controller;
use Symfony\Bundle\FrameworkBundle\Controller\Controller;
use Symfony\Component\HttpFoundation\Response;
class MonControleurController extends Controller
{
public function methodeAExecuterAction()
{
$content = $this->get('templating')->render('OCPlatformBundle:MonControleur:index.html.twig', array('nom' => 'lolou'));
return new Response($content);
}
}
Autre façon de faire avec
this->render() qui est une façon de raccourcir get('templating etc: :
namespace Mon\BeauBundle\Controller;
use Symfony\Bundle\FrameworkBundle\Controller\Controller;
use Symfony\Component\HttpFoundation\Response;
class MonControleurController extends Controller
{
public function methodeAExecuterAction()
{
return $this->render('OCPlatformBundle:MonControleur:index.html.twig', array('nom' => $monparam));
}
}
Ci-dessous, pour la route
path: /chemin_dans_barre_d_adresse/{monparam}, on affiche le paramètre :
public function methodeAExecuterAction($monparam)
{
$content = $this->get('templating')->render('OCPlatformBundle:MonControleur:index.html.twig', array('nom' => $monparam));
return new Response($content);
}
Il est également possible de récupérer les variables de l'URL passées en paramètre en GET (post/5?monparamalancienne=mavaleur), elles se retrouveront dans un objet de type "Request" envoyé en paramètre à la fonction dans le controleur. L'url est http://localhost/Symfony/web/app_dev.php/platform/chemin_dans_barre_d_adresse/param?monparam=mavaleur, l'exemple suivant affichera "mavaleur" sur la page :
use Symfony\Bundle\FrameworkBundle\Controller\Controller;
use Symfony\Component\HttpFoundation\Response;
use Symfony\Component\HttpFoundation\Request;
class MonControleurController extends Controller
{
public function methodeAExecuterAction($monparam, Request $request)
{
$tag = $request->query->get('monparam');
$content = $this->get('templating')->render('OCPlatformBundle:MonControleur:index.html.twig', array('nom' => $tag));
return new Response($content);
}
}
Un objet de type Request permet de récupérer les paramètres GET mais aussi POST ($request->request->get('tag')), les cookies ($request->cookies->get('tag')), les variables de serveur ($request->server->get('REQUEST_URI')), les variables d'entête ($request->headers->get('USER_AGENT')), les paramètres de route ($request->attributes->get('id')) et beaucoup d'autres choses.
On peut aussi utiliser cet objet pour manipuler les sessions (et les voir en cliquant sur la barre d'outil en bas en mode dev) :
$session = $request->getSession(); // Récupération de la session
$userId = $session->get('user_id'); // On récupère le contenu de la variable user_id
$session->set('user_id', 12); // On définit une nouvelle valeur pour cette variable user_id
Pour générer des url dans le contrôleur, par exemple un lien vers la page "contact", on lui indique le nom de la route et il génère l'url à partir du fichier de routing (ce qui permet de ne pas les écrire en dur et devoir modifier 2000 url) :
$this->get('router')->generate('oc_platform_home') ou $url = $this->generateUrl('oc_platform_home');. Pour URL absolue, ajouter l'argument UrlGeneratorInterface::ABSOLUTE_URL.Pour le faire depuis Twig :
{{ path('oc_platform_view', { 'id': advert_id }) }}Redirection (pour que les directions soient pluis détaillées en mode dev passer intercept_redirects à true dans app/config/config_dev.yml) :
return $this->redirectToRoute('nom_de_la_route_vers_laquelle_rediriger');
Il est possible de mémoriser une variable qui sera utilisée en cas de redirection. On appelle ça des "messages flash" :
$session = $request->getSession();
$session->getFlashBag()->add('info', 'Ce message sera affiché une fois arrivé sur la page vers laquelle vous êtes redirigé. Il disparaitra si vous faites F5 ou bien y arrivez directement, sans passer par cette redirection.');
return $this->redirectToRoute('nom_de_la_route_vers_laquelle_rediriger');
Pour afficher tous les messages flash dans Twig :
<div>
{# On affiche tous les messages flash dont le nom est « info » #}
{% for message in app.session.flashbag.get('info') %}
<p>Message flash : {{ message }}</p>
{% endfor %}
</div>
Retourner du JSON :
use Symfony\Component\HttpFoundation\JsonResponse;
// ...
public function viewAction($id)
{
return new JsonResponse(array('id' => $id));
}
Les messages d'erreur dans Symfony sont dans
\vendor\symfony\symfony\src\Symfony\Bundle\TwigBundle\Resources\views\Exception. En cas d'erreur html une page html est affichée (error.html.twig), en cas d'erreur json un json vide est renvoyé, en cas d'erreur css un css vide est renvoyé etc...En mettant un fichier error.html.twig dans
\app\Resources\TwigBundle\views\Exception, celui-ci aura priorité sur celui de Symfony (on pourrait aussi modifier directement les messages d'erreur mais en cas de mise à jour le dossier vendor/symfony est susceptible d'être écrasé), penser à vider le cache de prod.Twig
Moteur de template utilisé par Symfony. Entre "
{{ nom ~ " " ~ prenom }}. On peut aussi mettre en majuscule, mettre la première lettre en amjuscule, etc. Avant d'afficher une valeur, twig converti en entités html.Voir la doc de twig pour les boucles, les if else, les tableaux...
Pour récupérer le contenu d'un template en texte :
$contenu = $this->renderView('MonBeauBundle:Advert:email.txt.twig', array(
'var1' => $var1,
'var2' => $var2
));
mail('adressemail@quienvoyer.com', 'Voici la page html envoyée comme mail', $contenu);
On peut évidemment utiliser des layouts (avec le mot clef "block" qui indique où vont se placer les éléments). Il est conseillé de les faire sur 3 niveaux : layout général du site (à mettre dans app/Resources/views/layout.html.twig), layout de la section (dans src/nomdubundle/resources/views/), layout de la page (dans src/nomdubundle/resources/views/nomdelasection).
Exemple de bloc formant le layout général d'un site :
<!DOCTYPE html>
<html>
<head>
{% block head %}
<link rel="stylesheet" href="style.css" />
<title>{% block title %}{% endblock %} - My Webpage</title>
{% endblock %}
</head>
<body>
<div id="content">{% block content %}{% endblock %}</div>
<div id="footer">
{% block footer %}
© Copyright 2011 by <a href="http://domain.invalid/">you</a>.
{% endblock %}
</div>
</body>
</html>
Et une page qui utiliserait le layout "base.html" ci-dessus, notez qu'il hérite (extends) de base.html :
{% extends "base.html" %}
{% block title %}Index{% endblock %}
{% block head %}
{{ parent() }}
<style type="text/css">
.important { color: #336699; }
</style>
{% endblock %}
{% block content %}
<h1>Index</h1>
<p class="important">
Welcome on my awesome homepage.
</p>
{% endblock %}
On peut aussi inclure une page sans qu'elle n'hérite d'une autre :
{{ include("MonbeauBundle:monSousD:maPageAInclure.html.twig") }}Exemple qui récupère le contenu d'un tableau et l'affiche :
{% for article in monTableauDarticles %}
<a href="{{ path('chemin_de_mon_lien', {'id': article.id}) }}">
{{ article.titre }}
</a>
{% else %}
Aucun article dans ce tableau !
{% endfor %}
On peut également appeler une méthode d'un controleur avec render() :
<div id="menu">
{{ render(controller("MonBeauBundle:MonSousDosser:maMethode")) }} //dans la méthode on trouvera un "return $this->render(..."
</div>
Pour que l'exemple ci-dessus fonctionne, il faudra alimenter la page twig avec le controleur :
$monTableauDarticles = array(
array('id' => 2, 'titre' => 'Titre de mon article numero deux'),
array('id' => 5, 'titre' => 'Titre de mon article numero cinq'),
array('id' => 9, 'titre' => 'Le 9e article')
);
//on utilise la page twig
return $this->render('OCPlatformBundle:Advert:menu.html.twig', array(
// on y passe la tableau d'article
'monTableauDarticles' => $monTableauDarticles
));
Services Symfony
doc
Des objets php accessibles depuis n'importe où (pour envoyer un mail par exemple) : il suffit de créer la classe et de l'enregistrer dans le conteneur de service (le fichier
var/cache/dev/appDevDebugProjectContainer.php, qui va s'occuper d'instancier les services -une seule fois, en instanciant éventuellement d'autres services nécessaires, càd service A avant service B qui le nécessite). Pour enregistrer un service, ça se passe dans src/Mon/BeauBundle/Ressources/config/services.yml qui sera chargé par OCPlatformExtension dans le dossier DependencyInjection du bundle.Ci-dessous un service renseigné dans services.yml, avec des arguments (un autre service, un paramètre de l'appli, un nombre) qui seront récupérés dans la méthode de construction de la classe
public function __construct(\Swift_Mailer $mailer, $locale, $minLength):
services:
mon_beau.nomarbitraireduservice:
class: Le\Namespace\De\Mon\Service
arguments:
- "@mailer"
- %locale%
- 12
On peut aussi stocker des variables dans le fichier services.yml (
$container->getParameter('nomParametre'); pour y accéder ou bien %mon_parametre% pour y faire référence dans une autre section de services.yml):
parameters:
mon_parametre: ma_valeur
php bin/console debug:container pour lister les services. Depuis un contrôleur, pour appeler un service mailer par exemple : $this->container->get('mailer');.Doctrine
Un ORM php qui fait le lien entre nos classes modèles avec notre base de donnée grâce à des annotations (entre
/** et */, exemple :
/**
* @ORM\Column(name="id", type="integer")
* @ORM\Id
* @ORM\GeneratedValue(strategy="AUTO")
*/
Comme en Java, ces annotations peuvent être générées automatiquement.
Il peut être intéressant d'installer le package doctrinebundle.
L'accès à la BDD se configure dans "app\config\parameters.yml", puis, on lance la création de la base avec
php bin/console doctrine:database:create.Les entités se créent avec un configurateur qui va poser quelques questions. Il se lance avec
php bin/console doctrine:generate:entity puis les questions suivantes seront posées :Entity shortcut name nom de la classe/(de la table généralement) : MonBundle:MaClasse
Configuration format façon dont sont mappés les attributs de la classe avec les colonnes : annotation
New field name (press
Field type [string]: datetime
Is nullable [false]:
Unique [false]:
Le champ "id" est créé automatiquement. Bien sûr vous pouvez modifier le code source php entité (dans src/votre/bundle/Entity) pour y mettre un constructeur par exemple ou modifier le mapping (voir la doc de doctrine) puis
php bin/console doctrine:generate:entities MonBeauBundle:MonEntite pour générer les getters et les setters.Une fois les classes php générées, on se base sur elles pour créer nos tables dans notre base :
php bin/console doctrine:schema:update --dump-sql pour voir le SQL qui sera exécuté.php bin/console doctrine:schema:update --force pour créer concrètement nos tables en base.On peut également faire l'inverse : créer ses tables puis les importer dans doctrine.
Php
Création de tableau avec la fonction array :
$noms = array ('Bob', 'Bill', 'Joe');.Directement :
$noms[0] = 'Bob';Tableau associatif (par exemple, les variables superglobales $_GET ou $_POST sont des tableaux associatifs) avec la fonction array :
$coordonnees = array ('nom' => 'Bob','ville' => 'Paris');Tableau associatif directement :
$coordonnees['prenom'] = 'bob';Pour parcourir avec foreach :
foreach($noms as $element)Avec les clefs :
foreach($coordonnees as $cle => $element)Boucle for :
for ($i=0; $i<10; $i++) {}empty($var) returne true si var est nul, false, à 0, contient "", "0", un tableau vide.
isset return true si la variable contient quelque chose (si on lui a assigné null, elle ne contient rien).
tableau comparatif
Les variables peuvent changer de type selon ce qu'on met dedans, mais on peut forcer un type avec "settype" ou en faisant un cast, comme en java :
$_GET['nbr'] = (int) $_GET['nbr'];htmlspecialchars ou strip_tags pour éviter l'injection de code html dans les formulaires.Pour démarrer une session
session_start() au tout début de chaque page php où on veut utiliser les infos stockés en session (ou bien session.auto_start dans php.ini pour ne pas avoir à le préciser à chaque page). Une fois la session démarrée, il est possible de stocker des variables dans le tableau associatif superglobal $SESSION: $_SESSION['nom'] = 'Bob';. Le visiteur est identifié par une chaine de caractère (ex : 7bbba5d25cdfde422d7ac4be71ae7f91) stockée soit dans un cookie soit dans l'url (?PHPSESSID=...) ce qui est appelé "trans_id". On peut forcer à l'utiliser ou non de la façon suivante : ini_set("session.use_trans_sid",false); Attention, si on stocke l'identifiant de session dans l'url, il est facile de la voler (en recopiant l'url, en écoutant le réseau et récupérant les requêtes...).Pour mettre un cookie en place, tout en haut de la page
setcookie('nom', 'Bob', time() + 365*24*3600, null, null, false, true);, puis $_COOKIE['Bob'] pour l'afficher.Pour exécuter une requète,il vaut mieux utiliser des requêtes préparées qui permettent d'éviter l'injection decode:
$req = $bdd->prepare('SELECT * FROM table_employes WHERE nom = ?');
$req->execute(array($nomRecherche));
Balises echo courtes
Activé par défaut depuis PHP 5.4, on peut faire un
<?= $maVariable ?> qui sera équivalent à <?php echo $maVariable; ?>.Dans les vues, on pourra donc faire des choses du genre :
<span id="msgBienvenueHeader">Bienvenue <?= $membre->getPrenom();?></span> <span id="msgInfoHeader">Il te reste <?= $abonnement->getNbrCoursRestant();?> cours sur ta carte.</span>
Eviter d'utiliser la balise d'ouverture
<?, car elle est également utilisée en xml.Attention aussi à ne pas faire des choses du type
<?= include "mon_fichier.php" ?>, car sinon un 1 viendra se rajouter derrière le contenu de la page que vous voulez inclure.Les namespaces permettent d'avoir des classes ou des fonctions du même nom : il suffit d'écrire
namespace monnamespace; tout en haut du fichier et les fonctions qui seront crées ici seront propres à ce namespace (on peut aussi utiliser des accolades, namespace A{...}). Ils fonctionnent comme des dossier : mon\beau\namespace Pour appeler une fonction du namespace global, la faire précéder de \, ça fonctionne avec tous les namespace pas seulement celui racine. Il y a également le même genre de notion chemin relatif et absolu lorsqu'on veut appeler une fonction d'un autre namespace. La constante NAMESPACE permet d'afficher le namespace en cours. On peut donner des alias : use mon\beau\namespace as mbn;. On peut mettre plusieurs "use" dans un même fichier pour importer des classes (pas des fonctions, uniquement des classes) d'autres namespaces.Généralement on sépare les fichiers php dans des dossiers et on donne comme namespace le chemin relatif des fichiers.
Tableau associatif
Pour déclarer :
$monTableauAssociatif = array("maClef1"=>"maValeur1", "maClef2"=>"maValeur2", "maClef3"=>"maValeur3");Pour ajouter :
$monTableauAssociatif += array($maNouvelleClef => $maNouvelleValeur);XDebug
Permet de mettre des points d'arrêt etc.
Copier coller la vue html sur https://xdebug.org/wizard.php pour obtenir les instructions d'installation.
Composer
Gestion de dépendance en php, les paquets sont sur https://packagist.org/.
Il a besoin d'un fichier json, exemple :
{
"require": {
"monolog/monolog": "1.0.*"
}
}
...puis, dans la console, on va taper
composer update pour qu'il télécharge les librairies demandées.Un fichier autoload.php va faire charger automatiquement ces librairies à php mais attention, il est écrasé par composer à chaque demande d'upate.
On peut ajouter sa propre librairie à l'autoload de la façon suivante :
"autoload": {
"psr-4": {
"": "src/",
"VotreNamespace": "chemin/vers/la/bibliotheque"
},
"files": [ "app/AppKernel.php" ]
},
Callback
<?php
function appellezMoi(callable $action){ //pour s'assurer que c'est bien une fonction on type (callable)
echo "Avant Démarrage...";
// if(is_callable($action)){ on pourrait utiliser ça pour vérifier que c'est bien une fonction
$action();
}
$f=function(){
echo "Allo";
};
appellezMoi($f);
Fonction récursive
<?php
$nav = [
[
"label"=>"Accueil",
"url"=>"/",
],
[
"label" =>"Blog",
"url"=>"/blog",
"nav" =>
[
[
"label" =>"Articles",
"url"=>"/articles",
],
[
"label" =>"Tags",
"url"=>"/articles",
],
],
],
];
function arrayToMenu(array $data){
echo '<ul>';
foreach($data as $key=>$value){
echo '<li>';
printf('<a href="%s">%s</a>', $value['url'], $value['label']);
if(isset($value['nav'])){
arrayToMenu($value['nav']);
}
echo '</li>';
}
echo '</ul>';
}
arrayToMenu($nav);
CSS
Pour lire du css, mieux vaut partir de la droite, par exemple :
/* Après l'élément de classe "maClasse" ayant le même parent et suivant l'input type radio coché. */
input[type="radio"]:checked ~ .maClasse:after {
content: "lol";
}
⇒ Pour utiliser des pourcentages, par exemple 50% de la page, ne pas oublier de donner l'attribut height à 100% sur html, body et tous les éléments avant.
⇒ Pour positionner un élément en absolu par rapport à un autre, ne pas oublier de préciser le parent en relative.
BEM, une solution pour écrire des classes CSS :
<div class="boite">
<h2 class="boite_titre">Titre de ma boite</h2>
<p class="boite_pararaphe">Paragraphe de ma boite</p>
</div>
Si on veut faire une boite d'une autre couleur, on va mettre l'ancienne classe plus une nouvelle qui va changer la couleur :
<div class="boite boite--noire">
<h2 class="boite_titre">Titre de ma boite</h2>
<p class="box_pararaphe">Paragraphe de ma boite</p>
</div>
Un menu sur une ligne avec sous-menu déroulants (par contre on peut pas dérouler les éléments avec tab) :
<ul class="menu">
<li><a href="#">Item 1</a></li> <!-- il y aura des espaces affichés entre les éléments-->
<li class="menu_deroulant">
<a href="#">Item 2</a>
<ul>
<li><a href="#">Sous-Item 1</a></li>
<li><a href="#">Sous-Item 2</a></li>
</ul>
</li>
<li><a href="#">Item 3</a></li>
<li><a href="#">Item 4</a></li>
</ul>
.menu{
background-color: #227093;
color:white;
}
.menu > li{ /* on pourrait faire ".menu li" mais ">" permet de ne prendre que le dernier enfant */
display: inline-block; /*car on a des liens de type block à l'intérieur*/
position: relative;
}
.menu a{
padding:10px;
color:inherit; /* pour spécifier la couleur une seule fois, on récupère le "white" de plus haut*/
display: block;
}
.menu a:hover{
background-color: #34ace0;
}
.menu_deroulant {
background-color: inherit;
}
.menu_deroulant > ul{
position: absolute;
background-color: inherit;
white-space: nowrap;
/* display: none; pas bon pour l'accesibilité*/
/*on pourrait faire left:-99999px; pour éviter de le retirer du DOM ce qui n'est pas bon en terme d'accessibilité*/
/*par contre il sera sélectionné en étant invisible avec la tabulation, perso j'aime pas ça...*/
height: 0;
opacity: 0;
transition: opacity .2s ease;
}
.menu_deroulant:hover ul{
display:block;
height: auto;
opacity: 1;
}
Les éléments de type flottants sortent complètement du flux. Pour y remédier, on peut insérer en dessous une div avec un "clear:both" (cette technique s'appelle "clearfix"), ce qui va interdire les éléments flottants à sa gauche et à droite. Comme il est dessous, la div parent va s'adapter pour inclure ce div "clear", incluant ainsi l'image affichée avant.
On peut aussi utiliser
overflow: hidden; sur le parent : comme le parent n'est pas en taille fixe, il va s'adapter au contenu.SCSS
Donne plus de fonctionnalité au CSS, par exemple l'imbrication :
.book {
margin: 1em;
&:hover{
background-color: royalblue;
color:0;
}
p{
margin:0;
}
}
En css :
.book {
margin: 1em;
}
.book:hover{
background-color: royalblue;
color:0;
}
.book p{
margin:0;
}
Modélisation mathématique des langues naturelles
D'après la conférence de KAHANE Sylvain.
Une formule peut donner les relations entre les différents éléments de sens :
"Félix veut parler à Zoé." Félix définit comme a ; Zoé comme b;
Premier prédicat "vouloir", qui prend deux argument (Vouloir 1)QUI ? et 2)QUOI ?) :
Vouloir(a,e -e comme "évènement").
Deuxième prédicat "parler" avec trois arguments :
Parler(e,a,b) pourquoi remettre e et a ici ?
La formule complête est :
Deux évènements, e1 et e2. Vouloir(e1,a,e2) et parler(e2,a,b). pas compris
Quand on formalise une phrase, on isole différents éléments de sens, on exprime leur relation et le sens de certains éléments. On a pas décrit tous les mots dans cette phrase.
Exemple avec l'adjectif sec, beaucoup de sens différents (pas mouillé, maigre, froid).
Comment comprendre ça de façon abstraite ? Il existe l'approche du dictionnaire de synonyme Sabine Ploux and Bernard Victorri. Cette approche, c'est de voir que les mots qui représentent un même sens de "sec", parmis ses 56 synonymes, sont synonymes entre eux. sec=aride=décharné=maigre. Autre exemple : autoritaire=brusque=cassant=sec=tranchant.
Ils appellent ces groupements de mots des cliques. Il y en a 75 pour le mot sec. Grâce à ça, on va essayer de représenter le sens global du mot sec.
On va construire un espace à 56 dimensions (pour chaque synonyme) dans lequel on va placer les cliques. Pas d'explication mathématique sur comment ça se passe... Il nous montre ce que ça donne, il a mis au milieu le sens pas mouillé, il y a dans un coin le sens psychologique insensible, autre coin squelettique décharné, dans un autre coin les sens temporels court, bref.
Ensuite, tentative de retrouver le sens de sec lorsqu'il est donné avec un nom. Pour cela, on utilise un corpus de texte. On cherche dans tous ces textes avec quels mots le mot "foin" est associé et à quelle clique ça correspond. Par exemple, foin séché, foin mouillé, foin desseché etc. Ca correspond à la clique d'un certain sens. On aura pas de foin squelettique, ni de foin rapide. On sait donc que lorsque foin est associé avec sec il a le sens de "pas mouillé". Si on fait la même opération avec "homme", on a deux sens, décharné et sens psycho.
Note perso : Je comprends pas pourquoi il a besoin de représentation à 56 dimensions, ça me semble assez simple. on doit pouvoir programmer facilement un détecteur de sens d'adjectif selon le mot avec lequel il est associé.
Il faut d'une part déterminer les cliques, puis les associer avec une définition du dico (via mots clefs dans ces cliques). Puis :
Si dans un corpus (ou sur google tant qu'à faire) le mot clef est souvent associé à tel groupe d'adjectif, alors, sa définition la plus vraissemblable est trouvée dans le dictionnaire d'après les adjectifs en question.
Pourquoi 56 dimensions ?
Ceci dit, l'approche du dico des synonymes est très intelligente. Je suis étonné qu'on trouve pas encore d'application.
Chatterbot apprenant
Apprend des mots liés à des stimulis.
Exemples de stimulis : quelqu'un arrive, quelqu'un part, quelqu'un reste au délà d'une certaine limite, il est midi, le bot a faim, le bot a soif, on vient de dire un mot précis au bot, on tire la tronche, on va faire une action.
Chaque fois que le bot a faim, on demande "tu as faim ? tu as envie de manger ? C'est l'heure de manger ? il a faim le petit ?" exactement comme quand une mère parle à son bébé. Le bot doit associer les mots qui reviennent souvent "faim" et "manger" à la sensation de faim, puis les réutiliser par la suite.
Il doit également pouvoir (mais peut être est-ce inutile dans un premier temps ?).
Il est fort simple de programmer une longue liste de stimuli, mais pour que ça soit de la vraie auto apprentissage, les stimulis doivent être détectés par le bot.
Quelle est la définition la plus simple d'un stimuli ? Un changement d'un état. Le simple fait que le temps passe est un stimuli. Avoir faim au delà d'un certain point est un stimuli.
Le robot doit donc être capable d'associer un changement d'état à un mot, puis réutiliser ce mot lorsque le changement d'état survient. Ce serait déjà une étape importante, bien que très peu spectaculaire.
"Bot : Faim.
-NON. J'ai faim.
-J'ai faim." ⇒on donne à manger.
"User : J'ai faim." ⇒Il faudrait que le bot nous donne à manger ?
L'étape suivant serait de ne pas connaitre uniquement les mots, mais les stimulus suivant un stimulus, en distinguant les acteurs...
Lojban
Grammaire : http://jerome.desquilbet.org/pages/85/#2_1
Utilise l'alphabet latin sauf les lettres "h" "w" et "q".
Il existe une lettre en plus : "'", qui se prononce comme ahead. Elle sert à séparer clairement deux voyelles.
La ponctuation se prononce, il y a juste "," (indique exception d'une syllabe) et "." (pause).
Le "e" se prononce "é", le "y" se prononce "e", le c se prononce "sh", le g est toujours dur (ga, gu, go), le x se prononce du fond de la gorge, comme la jota espagnole.
Les mots prennent un certains nombre d'arguments (sumti), comme pour une fonction dans un programme.
Par exemple avec klama (venir/aller) en a 5 : x1 va à la destination x2 depuis x3 par la route x4 en utilisant x5. Pour omettre un argument on utilise zo'e ("qui n'est pas important"). Il y a des petits mots à utiliser pour modifier l'ordre des arguments de klama pour éviter d'utiliser 4 zo'e par exemple. On peut laisser tomber les derniers arguments.
Français
Vocabulaire
accroire : Faire croire un truc faux à quelqu'un.
adamites : religieux nus et végétariens pour faire comme Adam.
alacrité : Vivacité et enjouement. "Même après son divorce, il a pu conserver son alacrité."
anadyomène : qui sort de l'eau. "J'aime regarder Pamela Anderson anadyomène dans sa fameuse série au maillot rouge."
aporie : difficulté logique insoluble. noeud gordien = pseudo-aporie trouvant une résolution brutale.
Autotélique : "Qui n’est entrepris pour d’autre but qu'elle-même"
avunculaire : Qui a rapport à un oncle ou à une tante.
capirote : La capuche genre Ku Klux Klan.
coruscation : Éclat lumineux vif et passager. La coruscation d'un météore.
cynégétique : qui se rapporte à la chasse.
duègne : Femme âgée chargée de veiller sur la conduite d'une jeune fille ou d'une jeune femme. "Elle ne devrait pas sortir sans sa duègne."
dolent : Qui se sent malheureux et cherche à se faire plaindre.
guigner : Regarder à la dérobée. Guigner le jeu du voisin.
difficultueux : Qui cause des difficultés, est enclin à les faire naître.
dilection : Amour pur et spirituel pour quelqu'un/quelque chose.
entéléchie : parfait accomplissement de l'être.
épigone : imitateur sans originalité, successeur.
hapax : forme raccourcie et désormais usuelle d'hapax legomenon, un mot qui n'a qu'une seule occurrence dans un corpus donné.
ligne de désir : chemins qui se forme naturellement dans l'herbe à force que les gens y marchent.
impéritie : défaut de compétence dans la profession que l'on exerce.
manicheisme : simplificaion excessive notamment sur la question du bien et du mal mais à la base tentative de mélanger le judaïsme, du bouddhisme, du brahmanisme et du christianisme.
orchidoclaste : qui casse les couilles.
palinodie : refuter quelque chose qu'on vient juste de soutenir. Par exemple texte argumentatif en faveur de X où dans la conclusion on réfute toute notre argumentation.
panégyrique : louange, éloge de quelque chose. "J’ai même vu un livre quiportait pour titre : l’Éloge du sel, où le savant auteur exagérait les merveilleusesqualités du sel et les grands services qu’il rend à l’homme. En un mot, tu ne ver-ras presque rien qui n’ait eu son panégyrique. " - Le Banquet (Platon).
Pare-battage : Les bouées bizarres en petit boudin dans les bateaux. Ca se met entre la coque du bateau et le quai.
paternien : religieux qui disaient que la chair est l'oeuvre du démon et donc et donc forniquaient, se baffraient etc.
pelagique : relatif à la mer/haute mer.
Péricope : bout de texte significatif.
phare : vient du Phare d'Alexandrie qui s'appelle Phare à la base car il est sur l'île de Pharos.
plénipotentiaire : Agent diplomatique qui a pleins pouvoirs pour l'accomplissement d'une mission.
prétérition : ou paralipse, figure de style quand on parle de quelque chose dont on ne dit pas qu'on en parle ("je ne vais pas parler de sa cuisine infecte").
psittacisme : répêter bêteùent comme un perroquet sans comprendre.
senestre : main gauche. "Carré dans la cathèdre de la salle des États, il appuie sa tête sur sa senestre, et suit d’un œil éteint la polémique qui agite les grands serviteurs du royaume." (Jaworsky)
sérier : classer en série.
stigmergie : un ensemble d'actions individuelles qui aboutissent à une oeuvre. " Les individus, par stigmergie, font émerger des lignes de désir."
suborner : corrompre "Il ne pu suborner la jeune fille car sa duègne l'accompagnait. Ce qui enleva de l'alacrité au jeune homme."
syzygie : quand 3 objets célestes qui se tournent autour forment une ligne.
velléité : intention qui n'est pas suivie d'effet.
Anglais
Principalement tiré du programme News Buster sur Canal U.
Les nombres 13 à 19 sont accentués sur la dernière syllabe (thirteen), les dizaines sont accentuées sur la première (thirty).
Syndicate : Groupe de personne. Un syndicat = “trade union”.
ten millions-plus jackpot : Le plus signifie ici "un jackpot de plus de dix millions", pas "10 millions plus un jackpot".
“The 3 types of terror: The Gross-out: the sight of a severed head tumbling down a flight of stairs, it's when the lights go out and something green and slimy splatters against your arm.
The Horror: the unnatural, spiders the size of bears, the dead waking up and walking around, it's when the lights go out and something with claws grabs you by the arm.
And the last and worse one: Terror, when you come home and notice everything you own had been taken away and replaced by an exact substitute. It's when the lights go out and you feel something behind you, you hear it, you feel its breath against your ear, but when you turn around, there's nothing there...”
1 : chase, attack —usually used as a command especially to a dogsic 'em
2 : to incite or urge to an attack, pursuit, or harassment : set sicced their lawyers on me
"I'm siccing Sylvanor's ghost on you!"
En anglais américain, on désigne les états unis d'Amérique comme "she". Comme un navire.
Arabe
Se lit de droite à gauche.
-Attention au daal et au raa (le raa est comme un cRRRochet, le daal est plus plat).
-Attention aussi à alif et laam. Pour les différencier, retenir que le alif n'est jamais attaché à gauche. Si c'est attaché à gauche ou SI ça va CHERCHER l'attachement à gauche (le bas à gauche cherche à s'attacher, même si ya rien ل), c'est un laam !
-Attention au miim et haa' qui se ressemblent (mais juste en début, et le haa' est replié sur lui même). Exemple : مُهُ (muhu).
-Le dhaal (ressemble à un j) se prononce un peu comme un z avec un peu de "th" anglais (translitéré avec un z ou dh).
-Il y a un vrai th anglais, ce sont les 3 petits points en triangle. Prononciation très proche du dhaal mais sans le son "zz", que le "th" !
-Le na a un point en haut, na na na na na batman.
-Le ta a 2 points en haut (pas de boucle sinon c'est q).
-Le vrai J ressemble à un te japonais ou a une vague de quick silver car Jim est cool c'est un surfeur. Il est nul par contre il est en bas de la vague (ou en train de se faire attrapper par le rouleau).
Quand il est plus du tout dans la vaugue, il prend sa respiration ("haaa").
-Le ba a un point en bas, il sert aussi de p (il n'y a pas le son p en arabe normalement mais pour des mots d'origine étrangères ça peut arriver).
-Le khaa' se prononce plutôt "rah" avec le r pas du tout roulé. Ne pas confondre avec le raa qui lui est davantage roulé.
-Le K ressemble vaguement à un K si on supprime la barre du haut à gauche.
-Le Y a deux points en dessous, comme les deux branches du Y qui aurait coulé. Je sais pas ça me fait penser à un bateau coulé.
Parfois (surtout pour les débutants) on met un ` au dessus d'une lettre, ça signifie qu'il faut ajouter le son "a" court (genre s`=sa) mais si on veut un a long faut combiner avec alif (on peut aussi combiner avec un ة pour avoir le son court...). Sur le sh (ش) le ` peut être décalé à gauche.
Si le ` est en bas, il faut ajouter i ,(on peut aussi combiner avec un Y ce qui ferait un long iiii par contre).
Un petit noeud au dessus signifie d'ajouter u (pareil on peut combiner avec و pour avoir le uuu).
La sorte de petit 3 c'est répéter, butter sur la consonne. "lubb-ii".
Enfin le petit ° signifie qu'il n'y a pas de voyelle, juste la consonne.
Si on met deux ` dessus alif (ا) ça se prononce "ann" (le signe s'appelle fatḥatan).
Le u se prononce ou.
Le son du 3 inversé (ع) est un peu chaud, un peu entre ain (15%), an(10%), ha et a... et la prononciation change selon avec quoi il est combiné.
Alif est entre èèè et aaa.
لا
Il existe aussi لا qui n'est pas représenté dans la charte ci-dessus car mélange de ل et ا.
Exprime la négation.
Peut s'écrire comme un petit noeud type sidaction vers le bas sinon avec un angle de 90° droit et la diagonale qui part du milieu de l'angle.
Vocabulaire
Je mélange peut être les différents arabes :(
أَنا (ana') : je
أنتي ('anti, pas sûr) : tu (pour une femme, ressemble à mélange "empty"/"aunty" :) )
أنتا (anta) : tu (pour un homme)
عِنْد (ahend) : avoir, posséder (attention c'est pas un verbe, c'est na notiuon d'avoir, posséder).
عَفْواً (aafouan') : de rien
حظاَ جيداَ (hza jyda) : bonne chance ("avengé yidann").
عَفْواً (tamaman') : absolument
أَهْلاً ('ahlaan) : Bonjour/Bienvenue
شُكْراً (shukraan) : Merci. شُكْراً يا مَها. (shukraan ya maha) = Merci Maha.
بَيْت (bayt') : maison
كَراج (karaaj) : garage
مِن (min') : de (d'un endroit, أَنا مِن لُبنان je suis du Liban, ana' min' lubnann' / تامِر مِن فَرَنْسا Tamir est de France).
أَيْن (aynn') : où
فَرَنْسا (faransya) : France
عُمان (auman') : Sultanat d'Oman.
ليبيا (libya) : La Lybie.
لا(la) : non.
سَمَك(samak) : poisson (ça fait penser à "sakana" un peu)
سيد(syid) : monsieur (sayid, le fameux "saïd")
تَعْرِف(taerif, pas sûr) : connaitre/savoir (avec le i presque e et f qui ressemble à un v, "taarifinn" vis à vis d'une femme).
جَديد(jadid) : nouveau
زَوج(zauj) : mari
كَريم(karim) : généreux
باب(baab) : une porte
عادي(3aedi) : ordinaire
مُمتاز(mumtèz) : extraordinaire, excellent
بارِد(bèèrèd) : froid
إِبْتِسَام(ibtisaam) : sourire
كَبير(kabir) : large, grand
ya : petite particule pour insister.