EditerConception d'une base de donnée
Sommaire
1. Méthode Merise
- Recueil des données
- Établissement du dictionnaire des données
- Mise en place des dépendance fonctionnelles et non-fonctionnelles
- Modèle Conceptuel des Données (MCD)
- Les formes normales
- Héritage
- Contraintes sur héritage
- Contraintes entre relations
- Identifiant relatif
- Plus loin dans le MCD
- Modèle Logique des Données (MLD)
2. Liens
Une base de donnée est :
-centralisée et unifiée (règles de fonctionnement communes à toute la base).
-elle a une indépendance physique et logique vis à vis de l'applicatif.
-elle dispose de systèmes de sécurité pour assurer l'intégrité des données et leur cohérence (règles de remplissage, vérification des associations entre les données...).
-l'administration est facilitée (systèmes de droit d'accès).
-gestion de la concurrence : plusieurs utilisateurs peuvent modifier la base en même temps.
-performances.
-langage unifié pour manipuler les données (SQL).
-la redondance est mieux maîtrisée.
Pour comprendre la redondance, voir le tableau suivant. Beaucoup d'informations sont redondantes (Fiat est répété 5 fois) :
Si on avait un deuxième tableau (contenant "Fiat:1, Opel:2, Renault:3"), on pourrait considérablement économiser de l'espace disque de la façon suivante :
Pour utiliser une base de donnée, il faut un SGBD (système de gestion de base de donnée).
SGBDR (Relationnelles) -> Mysql, access, oracle, Navicat, Postegresql, db2, sql server.
Il existe aussi des SGBD "objet" (se basant sur les principes de la programmation objet) comme MongoDB. Intéressantes mais pas forcément plus performantes. Elles restent confidentielles car il faudrait changer les programmes et les SGBDR sont bien implantées.
Il faut prendre du temps pour réfléchir à la mise en place de sa base de donnée : mal définie elle peut être trop lente, pas évolutive, trop simpliste ou trop complexe, ne pas répondre du tout aux besoins.
La méthode Merise permet d’organiser la BDD.
UML est un système de modélisation qui explique comment représenter, pas une méthode. Elle est mal adaptée au relationnel.
Principes posés dans les années 70 car c'est l'époque de l'élaboration des SGBD. Avant les SGBD on travaillait avec des fichiers.
Merise permet l'oganisation du système d'information. C'est une méthode très vaste qui va au delà de la conception de base de données, elle permet la conception du système d'information.
On utilisera les MDC, MLD et MPD pour concevoir notre base de donnée.
Au niveau conceptuel, on fait abstraction des contraintes techniques (quelle SGBD, quel langage...).
On va recueillir les données à traiter, établir un dictionnaire des données pour bien les identifier, lier les données entre elles et établir une structure de la base de donnée. C'est là qu'on fait le recueildes données, l'établissement du dictionnaire, des dépendances et dessine le MCD.
En plus des "données" (mémorisation des informations) et des "traitements" (tâches à effectuer sur les données), la "communication" est un troisième domaine étudié par Merise (celui des flux), ajouté plus tard. Il ne nous sera pas utile pour concevoir des bases.
Pour réaliser une base de donnée à partir d'éléments existants (exemple : une entreprise souhaite informatiser ce qu'elle gérait sur papier), la première étape est le recueil des données.
-voir quel champ métier est concerné. Pour une base "ressource humaine" -> les RH, la paye, les employés en général, les personnes qui valident les congés...
Les données peuvent être recueillies en interviewant les experts métier et analysant les documents internes (fiche de paye, facture, feuille d'inventaire...).
Il faut essayer d'être exhaustif car sous spécifier une base est plus grave que de la sur-spécifier.
-On stocke les infos au niveau atomique, c'est à dire qu'on ne doit pas pouvoir les décomposer. Une adresse se découpe donc au minimum en "voie, CP, ville" (il existe en réalité des normes à respecter pour les adresses postales européennes). De la même manière, si on trouve sur un formulaire un champs "âges" permettant de noter plusieurs âges à la suite, on devra découper âge par âge tous les âges notés. Une date jour-mois-année est atomique dans le sens où on a besoin en général de ces trois éléments en même temps pour la comprendre (donner jour-mois sans l'année ne permet pas de donner un âge par exemple). On pourrait, à l'extrême, stocker le numéro de sécurité sociale dans plusieurs champs différents (sexe, mois, année de naissance...). Stocker de façon atomique permet d'indexer les champs et de rendre les recherches plus rapides (bien sûr il existe des commandes comme SUBSTRING pour éclater un champ mais on aura pas d'index).
-On regroupe les données similaires pour éviter les redondances. Par exemple, une date de livraison et une date d'expédition se regroupent en "Date". Un prix HT et un prix TTC peuvent se regrouper en "prix". Parfois on peut même regrouper des concepts comme des nombres. Recueillir toutes les données puis grouper celles qui ont un concept similaire. De la même manière, si on trouve un champ "prénoms" (ou "âges" pour reprendre l'exemple précédent), on va faire une donnée conceptuelle "prénom" et surtout pas "prénom1, prénom2...".
A ce stade, on essaie donc de regrouper un maximum de chose au concept proche, quitte à se rendre compte par la suite qu'il vaudrait mieux les garder séparer et revenir sur notre décision.
Des interviews des personnes concernées par la base les plus poussées possibles sont nécessaires pour bien comprendre l'organisation de la structure (demande de reformulation, poser plusieurs fois la même question à plusieurs personnes différentes...).
Il faut surtout se focaliser sur les questions portant sur les données, les questions sur les traitements ("Si un colis n'arrive pas à temps, que se passe-t-il ?") pourront venir plus tard, car au niveau conceptuel on veut séparer traitement et données.
Le dictionnaire va nous aider à établir des relations entre les données. Il sera partagé avec le programmeur.
On y indique le nom de la donnée, son format (alphabétique, alphanumérique, numérique -si elle servira pour des calculs, date, booléen...), sa longueur (nombre de caractères), son type ("élémentaire" si impossible à deviner ou "calculée" si elle vient d'autre données), sa règle de calcul (pour les données calculées, ce qui servira au programmeur), sa règle de gestion ("toujours positif", "unique"...) et le document où on a récupéré la donnée.
Les dictionnaires de données peuvent varier. Certains n'y mettent pas les données calculées, d'autres rajoutent des champs "commentaires" et "nom du champs dans la base".
A ce stade, on met en place les liens qui existent entre les données. On peut se rendre compte qu'on a besoin de retourner modifier son dictionnaire de données.
2 catégories de dépendances : fonctionnelles ou non.
Dépendances Fonctionnelles : les plus importantes, elles permettent de trouver de façon sûre et précise une autre donnée. Exemple : un numéro d'adhérent dans un club doit nous permettre de trouver de façon sûre, sans ambiguité, un nom et un prénom.
Il faut supposer que les données sont à jour (sinon, ça ne fonctionnerait jamais...). Par exemple, une personne peut changer son nom et son prénom après son inscription à un club, mais ce qui nous intéresse ce sont les données dans la base. On peut trouver avec un n° d'adhérent de façon sûre et certaine le nom et le prénom enregistré dans la base.
Dépendances Non Fonctionnelles : une information donne plusieurs résultats. Par exemple, une ville va retourner zéro, un ou plusieurs noms de clients différents.
Il peut exister des dépendances composées, c'est à dire qu'on a besoin de plusieurs éléments pour identifier de façon sûre une donnée. Exemple : n° du coureur, n° de course -> temps du coureur.
Attention aux fausses dépendances composées. Par exemple, dans "numéro de sécu, ville -> nom" on a pas besoin de la ville.
Une dépendance qui n'est pas composée est dite "élémentaire".
Il existe des dépendance indirectes : n° client -> pays, pays -> taxe applicable à ce pays. C'est intéressant à noter mais comme il peut en exister beaucoup, on va plutôt privilégier la recherche de dépendance directe.
Noter les dépendances trouvées à partir du recueil et du dictionnaire de données. On peut se rendre compte qu'il faut créer de nouvelles données (un numéro de client pour identifier à coup sûr un client). Penser à l'évolution future de la base : un numéro d'employé ne sera peut être plus unique si l'entreprise fusionne avec une autre, un numéro de sécurité social peut changer si changement de sexe ou être inconnu lors de l'admission d'un patient à l'hôpital (ce qui empêcherait de créer le patient dans la base). Une clef ne devrait pas porter d'information (car si l'information change, la clef aussi), ne devrait pas être trop long en raison des performances : un nombre qui s'incrémente est idéal.
On parle parfois d'identifiant naturel ("numéro de sécu" ou "nom/prenom") et artificiel (numéro qui s'auto-incrémente).
Dans tous les cas, lors de l'établissement des dépendances, garder en tête l'utilisation qui sera faite de votre base pour ne pas noter des dépendances inutiles. Exemple : un prénom donne une ou plusieurs villes, mais va-t-on souvent chercher une ville à partir d'un prénom ? Il y a des choix à faire pour rester pertinent.
C'est une représentation schématique qui fait la synthèse du recueil, du dictionnaire et des dépendances trouvées.
Attention, ce concept va demander beaucoup de vocabulaire.
Un MCD est constitué d'entités (un carré), d'associations (ovales d'où partent des segments connectant les entités entre elles, parfois appelés à tort "relations") et de propriétés (des attributs dans les carrés, des informations élémentaires -non déductibles- concernant une entité ou une association).
On peut le dessiner une feuille ou le créer sur ordinateur avec des logiciel comme Jmerise.
Un exemple d'entité "Client" avec ses propriétés (on dit aussi attributs) "n° de client", "Nom", "Prénom" :
Toute entité comporte une clef (un identifiant) : toutes les propriétés de l'entité dépendent fonctionnellement de cette clef (ci-dessus "n° de client").
Les propriétés ne doivent apparaître qu'une seule fois dans le MCD.
Elles sont liées entre elle par un lien verbalisée.
Par exemple, l'entité client pourra être lié avec l'entité produit de la façon suivante : client ---souscrire--- contrat.
Lorsqu'une propriétés concerne 2 entités, on peut en faire une propriété portée :
client ---souscrire (date)--- contrat
Date est ici une propriété portée.
Le terme "relation" est à l'origine utilisé pour parler d'entité : l'entité "client" serait une "relation" client, pas dans le sens où elle est en lien avec quelque chose, mais dans le sens où elle relate quelque chose. La relation est entre le nom du champ et la donnée.
Les cardinalités sont une paire de chiffres indiquant un maximum et un minimum qui vont répondre aux questions suivantes : "Un client peut souscrire a combien de contrat(s) ?" et "Un contrat peut être souscrit par combien de client(s) ?".
Exemple :
client 1,N -----souscrire----- 1,1 contrat
On apprend ici :
-qu'un client peut souscrire à minimum 1 contrat, maximum N (une infinité) de contrat ;
-qu'un contrat peut être souscrit par minimum 1, maximum 1 client ;
Autre exemple :
Joueur 1,1 ------ jouer ----- 1,N Club
"Chaque joueur peut jouer avec un seul club (min 1, max 1)."
"Chaque club peut faire jouer un ou plusieurs joueurs."
Encore un exemple pour bien comprendre :
Véhicule 1,1 -----immatriculer------ 0,N Date
"Chaque véhicule ne peut être immatriculé qu'à une seule date."
"A chaque date, 0 ou plusieurs véhicules peuvent avoir été immatriculés."
Comment passer des dépendances fonctionnelles au MCD ?
1)Les identifiants donnent des clefs.
2)Une clef (non fonctionelle ou fonctionnelle) donne une entité (si on a une clef n° joueur on comprend qu'on a une entité joueur).
3)Une dépendance composée donne une relation ternaire ou une propriété portée (marque de voiture,modèle -> nombre de portes).
4)Les dépendances entre clefs donnent des associations (si on a trouvé une dépendance n° de client -> commande, on aura une association).
5)Les dépendances fonctionnelles donnent les propriétés (num client -> nom client, "nom client" sera une propriété de l'entité client).
Le MCD aura donc une certaine structure visuelle avec divers éléments liés entre eux.
Les dépendances fonctionnelles composées donnent des propriétés portées ou des relations ternaires (un verbe relié à trois branches). Attention, les cardinalités sont difficile à mettre en place en cas de ternaire.
Une ternaire peut se découper entre plusieurs binaires (exemple tiré de http://cyril-gruau.developpez.com/uml/tutoriel/ConceptionBD/) :

Avant de faire une ternaire, mieux vaut tester si ça fonctionne avec une binaire.
Se poser la question, pour une ternaire avec les entités X, Y et Z : pour chaque X, combien y a-t-il de Y ? Pour chaque X combien y a-t-il de Z ?
Notez que si une association est porteuse de données, on trouve en général une cardinalité maximum de "n" de chaque côté.
Le modèle le plus performant est un modèle en étoile, avec l'entité très importante dans le coeur du métier au centre à laquelle est rattachée d'autres entités.
Quelques astuces pour les cardinalités :
-Impossible d'avoir une cardinalité maximale de 0.
-Si on a une cardinalité 1,1---association---1,1, autant fusionner les 2 entités.
-Si on a une cardinalité maximum de 1 dans une ternaire, il y a sans doute une erreur.
-Une association type 1,1---association---1,N ne peut pas avoir de propriété portée.
Le modèle le moins performant est un petit train avec les entités à la queue-leu-leu, ce qui implique que pour passer d'un côté à l'autre du train il faut remonter toutes les entités, ce qui demande beaucoup de traitement.
On peut se retrouver avec des "boucles", ce qui peut faire diminuer les performances, mais c'est parfois préférable à un modèle en petit train.
Plus on détaille le MCD en créant des entités au lieu de propriétés, plus il sera évolutif. Par exemple, on peut créer une entité "contrat" avec la propriété "type contrat" ou bien 2 entités séparées (une "contrat" et une "type contrat"). Mais plus il y a d'entités, plus cela nécessitera de traitements.
On a souvent un choix à faire entre nombre d'entités qui fait ralentir les requêtes et propriétés qui chargent l'espace disque. Le choix est fait selon l'utilisation qui sera faite de la base de donnée. Vaut-il mieux répéter deux mille fois "Renault" en propriété ou avoir une entité "marque de voiture"...?
Il vaut mieux aller du général au particulier : type de véhicule vers le centre du MCD, puis marque, puis modèle à l'extrémité du MCD, ceci afin de filtrer plus efficacement.
D'après Christian Soutou, "une base bien modélisée contient un grand nombre de tables, dotées d'un faible nombre de colonnes".
On peut vouloir éviter de laisser la possibilité d'avoir des champs "null" car ils prendront de la place en base. Par exemple, si on estime que beaucoup de clients n'ont pas d'email, au lieu d'avoir une table "nom, prénom, email" (qui contiendra beaucoup de NULL), mieux vaut avoir une table "email" séparée (les enregistrements n'existeront même pas). Le champ NULL est parfois réservé (plus rapide à écrire mais prend plus de place), parfois non, selon la configuration de la base. Il peut rendre plus compliqué l'écriture de requête (on doit le prendre en compte et vérifier si le champ est null) et ralentir les recherches car il n'est parfois pas indexé.
Lorsqu'on a des relations de type : 0,n---x,1 on parle parfois de CIF (Contrainte d'intégrité fonctionnelle).
Les relations/dépendances fonctionnelles ont plusieurs niveaux de qualité, qu'on appelle "les formes normales. On essaie de tendre vers le meilleur niveau de qualité mais parfois il est impossible de dépasser 3 étoiles.
Première forme normale (niveau de qualité une étoile) : Le contenu des attributs n'est pas divisible ("atomique", adresse est découpé en voie, cp, ville) + pas de valeur répétitives (pas prénom1, prénom2...). Ce travail a été fait lors du recueil et de l'établissement du dictionnaire des données.
Deuxième forme normale : Elle est de première forme normale+les attributs ont une dépendance élémentaire avec la clef (la dépendance "num secu,"age"->nom" n'est pas de 2e forme normale car "age" est inutile ici.
Troisième forme normale : Elle est en 2e forme normale+les propriétés non-clef ne doivent pas dépendre d'autres propriétés non-clef.
Exemple : une entité commande avec "num_commande" en clef et "num_client, nom_client" en propriétés n'est pas en 3e forme normale car le nom_client est obtenu avec num_client, pas directement).
Forme normale de Boyce Codd (4 étoiles) : Elle est en 3e forme normale+les dépendances ne sont pas composées. Une dépendance composée donnant une relation ternaire, elle est très reconnaissable sur le MCD. Si on trouve une cardinalité de 1,1 sur une ternaire, c'est une fausse ternaire et mieux vaut l'éliminer.
Dit autrement (Christian Soutou) : "Aucun attribut d'une classe association ne doit pouvoir jouer le rôle d'un identifiant d'une autre classe.".
Exemple : on a une entité vache avec comme propriétés "race (en clef), pays (en clef), région".
On voit ci dessus qu'il y a une dépendance fonctionnelle entre région et pays (une région donne un seul pays) : il faudrait donc avoir 2 entités, une entité Races (idRace, idrégion) et une entité région (idrégion, idpays).
Autre exemple (source) : Une entité "recolte" avec comme propriétés producteur (en clef), année (en clef), litres, id_vin.
-Elle est en 2e forme normale car on ne peut pas déterminer le numéro de vin avec aucun des deux parties de la clef.
-Elle est en 3e forme normale car on ne peut pas déterminer le numéro de vin avec une propriété non-clef.
-Par contre, la propriété id_vin peut servir à identifier un et un seul producteur.
id_vin--DF-->producteur
id_vin, année --DF-->litres
https://stph.scenari-community.org/bdd/nor1-prs/co/norUC026.html?mode=html
http://www.fsg.rnu.tn/imgsite/cours/Chap4-BD%20P2.pdf
http://salihayacoub.com/420Khg/Semaine%205/NormalisationEn%20Bref.pdf
https://cours.etsmtl.ca/gpa775/Cours/P05_2.pdf
Introduit dans Merise 2, la notion d'héritage (concept "orienté objet") n'est pas prise en compte par toutes les SGBD. Si on utilise cette notion dans notre MCD, il faudra une base telle que PostgreSQL ou Oracle pour l'implémenter (impossible dans MySQL).
Symbolisé par un triangle dans le MCD.
L'héritage permet de faire de la généralisation ("moto" et "auto" généralisés en "véhicule")/spécialisation ("véhicule", spécialisé en "moto" et "auto").
Attention à ne pas confondre avec une notion de composition : train->wagon=composition, train->TGV=spécialisation.
Il permet d'éviter de dupliquer des attributs et se retrouver par exemple avec un champ "nom" pour une entité "joueur", un autre champ "nom" pour une entité entraineur, un autre champ "nom" pour une entité "soigneur"... On peut faire une entité "salarié" avec comme attribut "nom" puis faire hériter les autres entités de cette propriété.
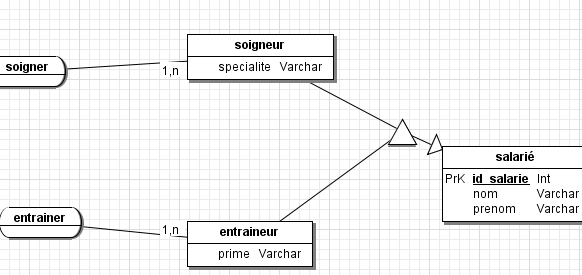
A noter qu'on pourrait laisser les entités "soigneur" et "entraineur" totalement vides.
Le triangle où se rejoignent les 3 traits indique l'héritage. On peut le remplir avec une contrainte.
Elles se placent dans le triangle et indique les règles entre les entités liées par un héritage.
-Un X indique que les 2 entités qui héritent ne peuvent pas fusionner. Autrement dit, un salarié est soigneur OU entraineur. On parle de "Non couverture, exclusion, disjonction". On suppose qu'il peut y avoir d'autres salariés que soigneur ou entraineur.
-Un T (comme totalité) indique que les propriétés des 2 entités peuvent fusionner, autrement dit qu'un salarié peut être soignant ET entraineur. Il ne peut pas y avoir d'autres salariés, on couvre ici la totalité des possibilités. On parle de "couverture, non disjonction, totalité".
-Un + ou XT indique que les entités qui héritent ne peuvent pas fusionner et qu'il n'existe pas d'autre objet que ces 2 là qui pourront hériter. Autrement dit, un salarié est soigneur OU entraineur et ces 2 statut couvrent l'ensemble des salariés de l'entreprise. On parle de "couverture, partition, disjonction". "Soit l'un ou l'autre mais pas les 2".
-Un triangle vide indique que les entités qui héritent peuvent fusionner et qu'il en existe potentiellement d'autres. Un salarié peut être soignant OU entraineur et il y a éventuellement d'autres types de salariés.
Lorsqu'on a deux entités liées ensemble par plusieurs verbes, on peut mettre une contrainte pour savoir si les entités peuvent faire les deux verbes en même temps. Par exemple "bus" lié à "heure" avec les verbes "arriver" ety "partir". Un bus ne peut pas arriver et partir à la même date et la même heure.
On retrouve les mêmes contraintes que sur les héritages.
-Totalité (T) : les deux verbes peuvent être faits en même temps et il n'y a pas d'autres verbes possibles pour ces relations.
-Partition (XT) : les deux verbes ne peuvent pas être faits en même temps et il n'y a pas d'autres verbes. "Soit l'un ou l'autre mais pas les 2".
-Simultanéité (S ou =) : les deux verbes doivent nécéessairement exister en même temps.
-Exclusion (X) : les deux verbes ne peuvent pas être faits en même temps et il y a potentiellement d'autres verbes possibles.
-Inclusion (I) : on fait les 2 verbes en même temps, le premier verbe est une sorte de spécialisation du deuxième (un joueur peut "être joueur" et peut "jouer", on voit que pour jouer il faut être joueur). On met une flèche du verbe qui englobe vers l'autre.
Plusieurs verbes, mêmes lointains et connectés à des entités très différentes peuvent être liés entre eux. Par exemple, une action "réserver" va être connecté avec un "S".
Exemple :
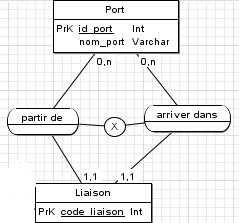
Pas d'impact sur la structure de la base, c'est juste pour assurer sa cohérence.
Un "R" pour conditionner l'existence d'une entité à une autre.
salarié--0,N---recevoir---1,1-R-bulletin salaire
Moteur --1,N---composer---1,1-R-pièce
projet--0,N---attacher---1,1-R-tâche
chantier--1,N---lier---1,1-R-facture
Agrégation : on encadre plusieurs éléments du MCD et on indique des cardinalités commes'il s'agissait d'une seule entité (exemple).
On va perdre le côté conceptuel et s'intéresser au fonctionnement de la BDD. Le passage du MCD au MLD est mécanique, en suivant quelques règles.
1) Associations X,1 <--->X,N
L'entité ayant la cardinalité maximum la plus basse récupère la clef de l'autre. Cette clef venant d'une autre entité s'appelle une clef étrangère et on la notera avec un dièse.
Une flèche indique d'où vient la clef étrangère (son sens est sujet à débat).
[clef A, attribut]--x,1--relation--1,N--[clef B, attribut]
donne
[clefA, #clef B, attribut]<-------[clef B, attribut]
S'il y a 2 verbes relationnels entre les 2 entités, les clefs seront récupérées en double :
[clefA, #clef B, #clef B, attribut]<-------[clef B, attribut]
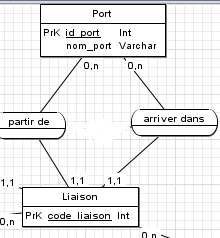
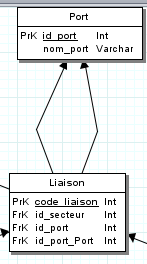
Exemple, liaison récupère 2 "id_port" (qu'on appellera id_port_arrive et id_port_depart par la suite) :
2)X,N ou X,N
Dans ce cas, le verbe relationnel se transforme en entité et récupère la clef des 2 autres.
[clef A]--X,N--(verbe)--X,N--[clef B]
donne
[clef A]---->[#clef A, #clef B]<----[clef B]
Une relation ternaire donne les 3 clefs au verbe de liaison.
La clef mise en premier sera celle utilisée le plus souvent pour trier. Il est parfois difficile de choisir laquelle mettre en premier. Ce n'est pas une faute grave de se tromper dans l'ordre on perd juste de l'optimisation.
3)Relation réflexive : on suit les règles énoncées plus haut.
4)Relations X,1<--->X,1
Un cas rare, on applique la règle X,1<-->X,N. A nous de décider quelle entité récupère la clef étrangère.
5)Relations très précises : 2,3<--->2,4
On applique strictement la règle 2.
Les propriétés portées se transforment en attribut.
Etape suivante, modèle physique, qui est un MLD présenté de façon un peu différente.
La plupart des SGBD ne supportent pas l'héritage.
employe(id_employe, nom, prenom)
herite de employe : soigneur(specialite)
herite de employe : entraineur(prime)
Il existe 3 façons de le simuler :
1)Dans la table mère, on met les attributs des classes filles et on indique le type. Facile à mettre en place et rapide à lire, mais des types seront nuls et ce sera dur pour une entité d'être de plusieurs types à la fois.
employe(id_employe, nom, prenom, specialite, prime, type)
2)Dans les tables filles, on recopie les attributs de la table mère. On a toutes les infos sous la mais (pas besoin de join) mais il faut modifier toutes les tables à la fois si on veut rajouter des attributs.
employe(id_employe, nom, prenom, specialite, prime, type)
employe(id_employe, nom, prenom, specialite, prime, type)
3)Dans les tables filles, on transmet la clef primaire de la table mère. Beaucoup de tables en base et de jointures à faire mais facile à avoir des typesqui se superposent.
employe(id_employe, nom, prenom)
soigneur(#id_employe, specialite)
entraineur(#id_employe, prime)
Bons petits exercices sur les MCD
Un ouvrage gratuit sur Merise
http://selsek.free.fr/eloker/miage/cours%20M1/msi/Poly-Merise2%20IUT-Info-Grenoble.pdf
https://www.youtube.com/watch?v=GzYrKJ4cFEo
1. Méthode Merise
- Recueil des données
- Établissement du dictionnaire des données
- Mise en place des dépendance fonctionnelles et non-fonctionnelles
- Modèle Conceptuel des Données (MCD)
- Les formes normales
- Héritage
- Contraintes sur héritage
- Contraintes entre relations
- Identifiant relatif
- Plus loin dans le MCD
- Modèle Logique des Données (MLD)
2. Liens
Une base de donnée est :
-centralisée et unifiée (règles de fonctionnement communes à toute la base).
-elle a une indépendance physique et logique vis à vis de l'applicatif.
-elle dispose de systèmes de sécurité pour assurer l'intégrité des données et leur cohérence (règles de remplissage, vérification des associations entre les données...).
-l'administration est facilitée (systèmes de droit d'accès).
-gestion de la concurrence : plusieurs utilisateurs peuvent modifier la base en même temps.
-performances.
-langage unifié pour manipuler les données (SQL).
-la redondance est mieux maîtrisée.
Pour comprendre la redondance, voir le tableau suivant. Beaucoup d'informations sont redondantes (Fiat est répété 5 fois) :
| Marque | Modèle |
|---|---|
| Fiat | Punto |
| Fiat | Uno |
| Fiat | Panda |
| Fiat | Mini |
| Fiat | Bravo |
| Opel | Corsa |
| Renault | Megane |
| Renault | Laguna |
Si on avait un deuxième tableau (contenant "Fiat:1, Opel:2, Renault:3"), on pourrait considérablement économiser de l'espace disque de la façon suivante :
| Num_marque | Modèle |
|---|---|
| 1 | Punto |
| 1 | Uno |
| 1 | Panda |
| 1 | Mini |
| 1 | Bravo |
| 2 | Corsa |
| 3 | Megane |
| 3 | Laguna |
Pour utiliser une base de donnée, il faut un SGBD (système de gestion de base de donnée).
SGBDR (Relationnelles) -> Mysql, access, oracle, Navicat, Postegresql, db2, sql server.
Il existe aussi des SGBD "objet" (se basant sur les principes de la programmation objet) comme MongoDB. Intéressantes mais pas forcément plus performantes. Elles restent confidentielles car il faudrait changer les programmes et les SGBDR sont bien implantées.
Il faut prendre du temps pour réfléchir à la mise en place de sa base de donnée : mal définie elle peut être trop lente, pas évolutive, trop simpliste ou trop complexe, ne pas répondre du tout aux besoins.
Méthode Merise
La méthode Merise permet d’organiser la BDD.
UML est un système de modélisation qui explique comment représenter, pas une méthode. Elle est mal adaptée au relationnel.
Principes posés dans les années 70 car c'est l'époque de l'élaboration des SGBD. Avant les SGBD on travaillait avec des fichiers.
Merise permet l'oganisation du système d'information. C'est une méthode très vaste qui va au delà de la conception de base de données, elle permet la conception du système d'information.
| Niveaux | Donnes | Traitements |
|---|---|---|
| Conceptuel | Modèle conceptuel des données (MCD) | Modèle conceptuel des traitements |
| Organisationnel | Modèle organisationnel des données | Modèle organisationnel des traitements |
| Logique | Modèle logique des données (MLD) | Modèle logique des traitements |
| Physique | Modèle physique des données (MPD) | Modèle opérationnel et physique des traitements |
On utilisera les MDC, MLD et MPD pour concevoir notre base de donnée.
Au niveau conceptuel, on fait abstraction des contraintes techniques (quelle SGBD, quel langage...).
On va recueillir les données à traiter, établir un dictionnaire des données pour bien les identifier, lier les données entre elles et établir une structure de la base de donnée. C'est là qu'on fait le recueildes données, l'établissement du dictionnaire, des dépendances et dessine le MCD.
En plus des "données" (mémorisation des informations) et des "traitements" (tâches à effectuer sur les données), la "communication" est un troisième domaine étudié par Merise (celui des flux), ajouté plus tard. Il ne nous sera pas utile pour concevoir des bases.
Recueil des données
Pour réaliser une base de donnée à partir d'éléments existants (exemple : une entreprise souhaite informatiser ce qu'elle gérait sur papier), la première étape est le recueil des données.
-voir quel champ métier est concerné. Pour une base "ressource humaine" -> les RH, la paye, les employés en général, les personnes qui valident les congés...
Les données peuvent être recueillies en interviewant les experts métier et analysant les documents internes (fiche de paye, facture, feuille d'inventaire...).
Il faut essayer d'être exhaustif car sous spécifier une base est plus grave que de la sur-spécifier.
-On stocke les infos au niveau atomique, c'est à dire qu'on ne doit pas pouvoir les décomposer. Une adresse se découpe donc au minimum en "voie, CP, ville" (il existe en réalité des normes à respecter pour les adresses postales européennes). De la même manière, si on trouve sur un formulaire un champs "âges" permettant de noter plusieurs âges à la suite, on devra découper âge par âge tous les âges notés. Une date jour-mois-année est atomique dans le sens où on a besoin en général de ces trois éléments en même temps pour la comprendre (donner jour-mois sans l'année ne permet pas de donner un âge par exemple). On pourrait, à l'extrême, stocker le numéro de sécurité sociale dans plusieurs champs différents (sexe, mois, année de naissance...). Stocker de façon atomique permet d'indexer les champs et de rendre les recherches plus rapides (bien sûr il existe des commandes comme SUBSTRING pour éclater un champ mais on aura pas d'index).
-On regroupe les données similaires pour éviter les redondances. Par exemple, une date de livraison et une date d'expédition se regroupent en "Date". Un prix HT et un prix TTC peuvent se regrouper en "prix". Parfois on peut même regrouper des concepts comme des nombres. Recueillir toutes les données puis grouper celles qui ont un concept similaire. De la même manière, si on trouve un champ "prénoms" (ou "âges" pour reprendre l'exemple précédent), on va faire une donnée conceptuelle "prénom" et surtout pas "prénom1, prénom2...".
A ce stade, on essaie donc de regrouper un maximum de chose au concept proche, quitte à se rendre compte par la suite qu'il vaudrait mieux les garder séparer et revenir sur notre décision.
Des interviews des personnes concernées par la base les plus poussées possibles sont nécessaires pour bien comprendre l'organisation de la structure (demande de reformulation, poser plusieurs fois la même question à plusieurs personnes différentes...).
Il faut surtout se focaliser sur les questions portant sur les données, les questions sur les traitements ("Si un colis n'arrive pas à temps, que se passe-t-il ?") pourront venir plus tard, car au niveau conceptuel on veut séparer traitement et données.
Établissement du dictionnaire des données
Le dictionnaire va nous aider à établir des relations entre les données. Il sera partagé avec le programmeur.
On y indique le nom de la donnée, son format (alphabétique, alphanumérique, numérique -si elle servira pour des calculs, date, booléen...), sa longueur (nombre de caractères), son type ("élémentaire" si impossible à deviner ou "calculée" si elle vient d'autre données), sa règle de calcul (pour les données calculées, ce qui servira au programmeur), sa règle de gestion ("toujours positif", "unique"...) et le document où on a récupéré la donnée.
| Nom de la donnée | Format | Longueur | Type (élémentaire/calculé) | Règle de calcul | Règle de gestion | Document |
|---|---|---|---|---|---|---|
| Numéro de facture | Numérique | 8 | Elementaire | unique, obligatoire | Facture 04502 | |
| Nom | Alphabétique | 64 | Elementaire | Facture 04502 | ||
| date | date | 10 | Elementaire | Facture 04502 | ||
| prix | Numérique | 8 | Elementaire | obligatoire | Facture 04502 | |
| taxe de séjour | Numérique | 8 | Elementaire | obligatoire | Facture 04502 | |
| prix total | Numérique | 8 | calculé | prix+taxe | obligatoire | Facture 04502 |
Les dictionnaires de données peuvent varier. Certains n'y mettent pas les données calculées, d'autres rajoutent des champs "commentaires" et "nom du champs dans la base".
Mise en place des dépendance fonctionnelles et non-fonctionnelles
A ce stade, on met en place les liens qui existent entre les données. On peut se rendre compte qu'on a besoin de retourner modifier son dictionnaire de données.
2 catégories de dépendances : fonctionnelles ou non.
Dépendances Fonctionnelles : les plus importantes, elles permettent de trouver de façon sûre et précise une autre donnée. Exemple : un numéro d'adhérent dans un club doit nous permettre de trouver de façon sûre, sans ambiguité, un nom et un prénom.
Il faut supposer que les données sont à jour (sinon, ça ne fonctionnerait jamais...). Par exemple, une personne peut changer son nom et son prénom après son inscription à un club, mais ce qui nous intéresse ce sont les données dans la base. On peut trouver avec un n° d'adhérent de façon sûre et certaine le nom et le prénom enregistré dans la base.
Dépendances Non Fonctionnelles : une information donne plusieurs résultats. Par exemple, une ville va retourner zéro, un ou plusieurs noms de clients différents.
Il peut exister des dépendances composées, c'est à dire qu'on a besoin de plusieurs éléments pour identifier de façon sûre une donnée. Exemple : n° du coureur, n° de course -> temps du coureur.
Attention aux fausses dépendances composées. Par exemple, dans "numéro de sécu, ville -> nom" on a pas besoin de la ville.
Une dépendance qui n'est pas composée est dite "élémentaire".
Il existe des dépendance indirectes : n° client -> pays, pays -> taxe applicable à ce pays. C'est intéressant à noter mais comme il peut en exister beaucoup, on va plutôt privilégier la recherche de dépendance directe.
Noter les dépendances trouvées à partir du recueil et du dictionnaire de données. On peut se rendre compte qu'il faut créer de nouvelles données (un numéro de client pour identifier à coup sûr un client). Penser à l'évolution future de la base : un numéro d'employé ne sera peut être plus unique si l'entreprise fusionne avec une autre, un numéro de sécurité social peut changer si changement de sexe ou être inconnu lors de l'admission d'un patient à l'hôpital (ce qui empêcherait de créer le patient dans la base). Une clef ne devrait pas porter d'information (car si l'information change, la clef aussi), ne devrait pas être trop long en raison des performances : un nombre qui s'incrémente est idéal.
On parle parfois d'identifiant naturel ("numéro de sécu" ou "nom/prenom") et artificiel (numéro qui s'auto-incrémente).
Dans tous les cas, lors de l'établissement des dépendances, garder en tête l'utilisation qui sera faite de votre base pour ne pas noter des dépendances inutiles. Exemple : un prénom donne une ou plusieurs villes, mais va-t-on souvent chercher une ville à partir d'un prénom ? Il y a des choix à faire pour rester pertinent.
Modèle Conceptuel des Données (MCD)
C'est une représentation schématique qui fait la synthèse du recueil, du dictionnaire et des dépendances trouvées.
Attention, ce concept va demander beaucoup de vocabulaire.
Un MCD est constitué d'entités (un carré), d'associations (ovales d'où partent des segments connectant les entités entre elles, parfois appelés à tort "relations") et de propriétés (des attributs dans les carrés, des informations élémentaires -non déductibles- concernant une entité ou une association).
On peut le dessiner une feuille ou le créer sur ordinateur avec des logiciel comme Jmerise.
Un exemple d'entité "Client" avec ses propriétés (on dit aussi attributs) "n° de client", "Nom", "Prénom" :
| Client |
|---|
| n° de client |
| Nom |
| Prénom |
Toute entité comporte une clef (un identifiant) : toutes les propriétés de l'entité dépendent fonctionnellement de cette clef (ci-dessus "n° de client").
Les propriétés ne doivent apparaître qu'une seule fois dans le MCD.
Elles sont liées entre elle par un lien verbalisée.
Par exemple, l'entité client pourra être lié avec l'entité produit de la façon suivante : client ---souscrire--- contrat.
Lorsqu'une propriétés concerne 2 entités, on peut en faire une propriété portée :
client ---souscrire (date)--- contrat
Date est ici une propriété portée.
Le terme "relation" est à l'origine utilisé pour parler d'entité : l'entité "client" serait une "relation" client, pas dans le sens où elle est en lien avec quelque chose, mais dans le sens où elle relate quelque chose. La relation est entre le nom du champ et la donnée.
Les cardinalités sont une paire de chiffres indiquant un maximum et un minimum qui vont répondre aux questions suivantes : "Un client peut souscrire a combien de contrat(s) ?" et "Un contrat peut être souscrit par combien de client(s) ?".
Exemple :
client 1,N -----souscrire----- 1,1 contrat
On apprend ici :
-qu'un client peut souscrire à minimum 1 contrat, maximum N (une infinité) de contrat ;
-qu'un contrat peut être souscrit par minimum 1, maximum 1 client ;
Autre exemple :
Joueur 1,1 ------ jouer ----- 1,N Club
"Chaque joueur peut jouer avec un seul club (min 1, max 1)."
"Chaque club peut faire jouer un ou plusieurs joueurs."
Encore un exemple pour bien comprendre :
Véhicule 1,1 -----immatriculer------ 0,N Date
"Chaque véhicule ne peut être immatriculé qu'à une seule date."
"A chaque date, 0 ou plusieurs véhicules peuvent avoir été immatriculés."
Comment passer des dépendances fonctionnelles au MCD ?
1)Les identifiants donnent des clefs.
2)Une clef (non fonctionelle ou fonctionnelle) donne une entité (si on a une clef n° joueur on comprend qu'on a une entité joueur).
3)Une dépendance composée donne une relation ternaire ou une propriété portée (marque de voiture,modèle -> nombre de portes).
4)Les dépendances entre clefs donnent des associations (si on a trouvé une dépendance n° de client -> commande, on aura une association).
5)Les dépendances fonctionnelles donnent les propriétés (num client -> nom client, "nom client" sera une propriété de l'entité client).
Le MCD aura donc une certaine structure visuelle avec divers éléments liés entre eux.
Les dépendances fonctionnelles composées donnent des propriétés portées ou des relations ternaires (un verbe relié à trois branches). Attention, les cardinalités sont difficile à mettre en place en cas de ternaire.
Une ternaire peut se découper entre plusieurs binaires (exemple tiré de http://cyril-gruau.developpez.com/uml/tutoriel/ConceptionBD/) :
Avant de faire une ternaire, mieux vaut tester si ça fonctionne avec une binaire.
Se poser la question, pour une ternaire avec les entités X, Y et Z : pour chaque X, combien y a-t-il de Y ? Pour chaque X combien y a-t-il de Z ?
Notez que si une association est porteuse de données, on trouve en général une cardinalité maximum de "n" de chaque côté.
Le modèle le plus performant est un modèle en étoile, avec l'entité très importante dans le coeur du métier au centre à laquelle est rattachée d'autres entités.
Quelques astuces pour les cardinalités :
-Impossible d'avoir une cardinalité maximale de 0.
-Si on a une cardinalité 1,1---association---1,1, autant fusionner les 2 entités.
-Si on a une cardinalité maximum de 1 dans une ternaire, il y a sans doute une erreur.
-Une association type 1,1---association---1,N ne peut pas avoir de propriété portée.
Le modèle le moins performant est un petit train avec les entités à la queue-leu-leu, ce qui implique que pour passer d'un côté à l'autre du train il faut remonter toutes les entités, ce qui demande beaucoup de traitement.
On peut se retrouver avec des "boucles", ce qui peut faire diminuer les performances, mais c'est parfois préférable à un modèle en petit train.
Plus on détaille le MCD en créant des entités au lieu de propriétés, plus il sera évolutif. Par exemple, on peut créer une entité "contrat" avec la propriété "type contrat" ou bien 2 entités séparées (une "contrat" et une "type contrat"). Mais plus il y a d'entités, plus cela nécessitera de traitements.
On a souvent un choix à faire entre nombre d'entités qui fait ralentir les requêtes et propriétés qui chargent l'espace disque. Le choix est fait selon l'utilisation qui sera faite de la base de donnée. Vaut-il mieux répéter deux mille fois "Renault" en propriété ou avoir une entité "marque de voiture"...?
Il vaut mieux aller du général au particulier : type de véhicule vers le centre du MCD, puis marque, puis modèle à l'extrémité du MCD, ceci afin de filtrer plus efficacement.
D'après Christian Soutou, "une base bien modélisée contient un grand nombre de tables, dotées d'un faible nombre de colonnes".
On peut vouloir éviter de laisser la possibilité d'avoir des champs "null" car ils prendront de la place en base. Par exemple, si on estime que beaucoup de clients n'ont pas d'email, au lieu d'avoir une table "nom, prénom, email" (qui contiendra beaucoup de NULL), mieux vaut avoir une table "email" séparée (les enregistrements n'existeront même pas). Le champ NULL est parfois réservé (plus rapide à écrire mais prend plus de place), parfois non, selon la configuration de la base. Il peut rendre plus compliqué l'écriture de requête (on doit le prendre en compte et vérifier si le champ est null) et ralentir les recherches car il n'est parfois pas indexé.
Lorsqu'on a des relations de type : 0,n---x,1 on parle parfois de CIF (Contrainte d'intégrité fonctionnelle).
Les formes normales
Les relations/dépendances fonctionnelles ont plusieurs niveaux de qualité, qu'on appelle "les formes normales. On essaie de tendre vers le meilleur niveau de qualité mais parfois il est impossible de dépasser 3 étoiles.
Première forme normale (niveau de qualité une étoile) : Le contenu des attributs n'est pas divisible ("atomique", adresse est découpé en voie, cp, ville) + pas de valeur répétitives (pas prénom1, prénom2...). Ce travail a été fait lors du recueil et de l'établissement du dictionnaire des données.
Deuxième forme normale : Elle est de première forme normale+les attributs ont une dépendance élémentaire avec la clef (la dépendance "num secu,"age"->nom" n'est pas de 2e forme normale car "age" est inutile ici.
Troisième forme normale : Elle est en 2e forme normale+les propriétés non-clef ne doivent pas dépendre d'autres propriétés non-clef.
Exemple : une entité commande avec "num_commande" en clef et "num_client, nom_client" en propriétés n'est pas en 3e forme normale car le nom_client est obtenu avec num_client, pas directement).
Forme normale de Boyce Codd (4 étoiles) : Elle est en 3e forme normale+les dépendances ne sont pas composées. Une dépendance composée donnant une relation ternaire, elle est très reconnaissable sur le MCD. Si on trouve une cardinalité de 1,1 sur une ternaire, c'est une fausse ternaire et mieux vaut l'éliminer.
Dit autrement (Christian Soutou) : "Aucun attribut d'une classe association ne doit pouvoir jouer le rôle d'un identifiant d'une autre classe.".
Exemple : on a une entité vache avec comme propriétés "race (en clef), pays (en clef), région".
On voit ci dessus qu'il y a une dépendance fonctionnelle entre région et pays (une région donne un seul pays) : il faudrait donc avoir 2 entités, une entité Races (idRace, idrégion) et une entité région (idrégion, idpays).
Autre exemple (source) : Une entité "recolte" avec comme propriétés producteur (en clef), année (en clef), litres, id_vin.
-Elle est en 2e forme normale car on ne peut pas déterminer le numéro de vin avec aucun des deux parties de la clef.
-Elle est en 3e forme normale car on ne peut pas déterminer le numéro de vin avec une propriété non-clef.
-Par contre, la propriété id_vin peut servir à identifier un et un seul producteur.
id_vin--DF-->producteur
id_vin, année --DF-->litres
https://stph.scenari-community.org/bdd/nor1-prs/co/norUC026.html?mode=html
http://www.fsg.rnu.tn/imgsite/cours/Chap4-BD%20P2.pdf
http://salihayacoub.com/420Khg/Semaine%205/NormalisationEn%20Bref.pdf
https://cours.etsmtl.ca/gpa775/Cours/P05_2.pdf
Héritage
Introduit dans Merise 2, la notion d'héritage (concept "orienté objet") n'est pas prise en compte par toutes les SGBD. Si on utilise cette notion dans notre MCD, il faudra une base telle que PostgreSQL ou Oracle pour l'implémenter (impossible dans MySQL).
Symbolisé par un triangle dans le MCD.
L'héritage permet de faire de la généralisation ("moto" et "auto" généralisés en "véhicule")/spécialisation ("véhicule", spécialisé en "moto" et "auto").
Attention à ne pas confondre avec une notion de composition : train->wagon=composition, train->TGV=spécialisation.
Il permet d'éviter de dupliquer des attributs et se retrouver par exemple avec un champ "nom" pour une entité "joueur", un autre champ "nom" pour une entité entraineur, un autre champ "nom" pour une entité "soigneur"... On peut faire une entité "salarié" avec comme attribut "nom" puis faire hériter les autres entités de cette propriété.
A noter qu'on pourrait laisser les entités "soigneur" et "entraineur" totalement vides.
Le triangle où se rejoignent les 3 traits indique l'héritage. On peut le remplir avec une contrainte.
Contraintes sur héritage
Elles se placent dans le triangle et indique les règles entre les entités liées par un héritage.
-Un X indique que les 2 entités qui héritent ne peuvent pas fusionner. Autrement dit, un salarié est soigneur OU entraineur. On parle de "Non couverture, exclusion, disjonction". On suppose qu'il peut y avoir d'autres salariés que soigneur ou entraineur.
-Un T (comme totalité) indique que les propriétés des 2 entités peuvent fusionner, autrement dit qu'un salarié peut être soignant ET entraineur. Il ne peut pas y avoir d'autres salariés, on couvre ici la totalité des possibilités. On parle de "couverture, non disjonction, totalité".
-Un + ou XT indique que les entités qui héritent ne peuvent pas fusionner et qu'il n'existe pas d'autre objet que ces 2 là qui pourront hériter. Autrement dit, un salarié est soigneur OU entraineur et ces 2 statut couvrent l'ensemble des salariés de l'entreprise. On parle de "couverture, partition, disjonction". "Soit l'un ou l'autre mais pas les 2".
-Un triangle vide indique que les entités qui héritent peuvent fusionner et qu'il en existe potentiellement d'autres. Un salarié peut être soignant OU entraineur et il y a éventuellement d'autres types de salariés.
Contraintes entre relations
Lorsqu'on a deux entités liées ensemble par plusieurs verbes, on peut mettre une contrainte pour savoir si les entités peuvent faire les deux verbes en même temps. Par exemple "bus" lié à "heure" avec les verbes "arriver" ety "partir". Un bus ne peut pas arriver et partir à la même date et la même heure.
On retrouve les mêmes contraintes que sur les héritages.
-Totalité (T) : les deux verbes peuvent être faits en même temps et il n'y a pas d'autres verbes possibles pour ces relations.
-Partition (XT) : les deux verbes ne peuvent pas être faits en même temps et il n'y a pas d'autres verbes. "Soit l'un ou l'autre mais pas les 2".
-Simultanéité (S ou =) : les deux verbes doivent nécéessairement exister en même temps.
-Exclusion (X) : les deux verbes ne peuvent pas être faits en même temps et il y a potentiellement d'autres verbes possibles.
-Inclusion (I) : on fait les 2 verbes en même temps, le premier verbe est une sorte de spécialisation du deuxième (un joueur peut "être joueur" et peut "jouer", on voit que pour jouer il faut être joueur). On met une flèche du verbe qui englobe vers l'autre.
Plusieurs verbes, mêmes lointains et connectés à des entités très différentes peuvent être liés entre eux. Par exemple, une action "réserver" va être connecté avec un "S".
Exemple :
Pas d'impact sur la structure de la base, c'est juste pour assurer sa cohérence.
Identifiant relatif
Un "R" pour conditionner l'existence d'une entité à une autre.
salarié--0,N---recevoir---1,1-R-bulletin salaire
Moteur --1,N---composer---1,1-R-pièce
projet--0,N---attacher---1,1-R-tâche
chantier--1,N---lier---1,1-R-facture
Plus loin dans le MCD
Agrégation : on encadre plusieurs éléments du MCD et on indique des cardinalités commes'il s'agissait d'une seule entité (exemple).
Modèle Logique des Données (MLD)
On va perdre le côté conceptuel et s'intéresser au fonctionnement de la BDD. Le passage du MCD au MLD est mécanique, en suivant quelques règles.
1) Associations X,1 <--->X,N
L'entité ayant la cardinalité maximum la plus basse récupère la clef de l'autre. Cette clef venant d'une autre entité s'appelle une clef étrangère et on la notera avec un dièse.
Une flèche indique d'où vient la clef étrangère (son sens est sujet à débat).
[clef A, attribut]--x,1--relation--1,N--[clef B, attribut]
donne
[clefA, #clef B, attribut]<-------[clef B, attribut]
S'il y a 2 verbes relationnels entre les 2 entités, les clefs seront récupérées en double :
[clefA, #clef B, #clef B, attribut]<-------[clef B, attribut]
Exemple, liaison récupère 2 "id_port" (qu'on appellera id_port_arrive et id_port_depart par la suite) :
2)X,N ou X,N
Dans ce cas, le verbe relationnel se transforme en entité et récupère la clef des 2 autres.
[clef A]--X,N--(verbe)--X,N--[clef B]
donne
[clef A]---->[#clef A, #clef B]<----[clef B]
Une relation ternaire donne les 3 clefs au verbe de liaison.
La clef mise en premier sera celle utilisée le plus souvent pour trier. Il est parfois difficile de choisir laquelle mettre en premier. Ce n'est pas une faute grave de se tromper dans l'ordre on perd juste de l'optimisation.
3)Relation réflexive : on suit les règles énoncées plus haut.
4)Relations X,1<--->X,1
Un cas rare, on applique la règle X,1<-->X,N. A nous de décider quelle entité récupère la clef étrangère.
5)Relations très précises : 2,3<--->2,4
On applique strictement la règle 2.
Les propriétés portées se transforment en attribut.
Etape suivante, modèle physique, qui est un MLD présenté de façon un peu différente.
Héritage
La plupart des SGBD ne supportent pas l'héritage.
employe(id_employe, nom, prenom)
herite de employe : soigneur(specialite)
herite de employe : entraineur(prime)
Il existe 3 façons de le simuler :
1)Dans la table mère, on met les attributs des classes filles et on indique le type. Facile à mettre en place et rapide à lire, mais des types seront nuls et ce sera dur pour une entité d'être de plusieurs types à la fois.
employe(id_employe, nom, prenom, specialite, prime, type)
2)Dans les tables filles, on recopie les attributs de la table mère. On a toutes les infos sous la mais (pas besoin de join) mais il faut modifier toutes les tables à la fois si on veut rajouter des attributs.
employe(id_employe, nom, prenom, specialite, prime, type)
employe(id_employe, nom, prenom, specialite, prime, type)
3)Dans les tables filles, on transmet la clef primaire de la table mère. Beaucoup de tables en base et de jointures à faire mais facile à avoir des typesqui se superposent.
employe(id_employe, nom, prenom)
soigneur(#id_employe, specialite)
entraineur(#id_employe, prime)
Liens
Bons petits exercices sur les MCD
Un ouvrage gratuit sur Merise
http://selsek.free.fr/eloker/miage/cours%20M1/msi/Poly-Merise2%20IUT-Info-Grenoble.pdf
https://www.youtube.com/watch?v=GzYrKJ4cFEo